

Es gibt viel Unsicherheit über Datenschutz und Datensicherheit rund um KI-Textgeneratoren wie ChatGPT oder Gemini. Was darf man ihnen anvertrauen? Was soll man lieber für sich selbst behalten? Eine Einordnung.
KI-Werkzeuge zur Fragenbeantwortung, Formulierung von Texten oder der Erstellung von Bildern sind aus dem Alltag Vieler inzwischen nicht mehr wegzudenken. Auch immer mehr IT-Software und -Services werden «Neu mit KI-Funktionen!» verkauft. Gleichzeitig hört man aus Dritter Hand Horrorgeschichten darüber, dass angeblich alle Eingaben an KI-Chatbots nachher öffentlich seien. Da kommen viele Fragen auf, was man mit dieser ganzen «Künstlichen Intelligenz» eigentlich noch anfangen darf.
Zum Verständnis des «Wieso?» hinter diesem Artikel sind Kenntnisse der Lernprozesse der KI empfehlenswert, die vor kurzem hier erklärt wurden.
Übrigens: Wir schauen uns in diesem Artikel nur an, welche Risiken aus unseren Input an die Sprachmodelle entstehen, nicht, was wir mit dem Output machen können.
TL;DR
Im Umgang mit KI-Chatbots können wir unterscheiden zwischen menschlichen, allgemein technischen und Chatbot-spezifischen Risiken rund um Datenschutz und Datensicherheit. Das Hauptaugenmerk dieses Artikels liegt dabei auf der grundsätzliche Datensicherheit bei Clouddiensten und die Nutzung von unseren Eingaben als Trainingsdaten. Also, ob und wie unsere Eingaben an Chatbots nachher an Unbefugte weitergeleitet werden.
Um die spezifischen Risiken rund um die Chatbots zu verstehen, werden zuerst die Wünsche und Sachzwänge der KI-Firmen beleuchtet sowie Einblick ermöglicht in die Trainings- und (Um-)Erziehungsprozesse von Chatbots und wieso diese so schwierig sind.
Nach dieser Auslegeordnung verstehen wir, dass ganz wenige Informationen den einzelnen Chatverlauf verlassen. Wenn wir uns nicht selbst darum kümmern, werden aber u.U. gewisse unserer Eingaben in den allgemein zugänglichen Trainingsdaten landen und mit ganz viel Pech erscheinen unsere Daten einige Monate später möglicherweise in den Antworten Dritter.
Zum Schluss gibt es eine Checkliste, um die Risiken zu minimieren.
Die Wünsche der Tech-Firmen
Die grossen Sprachmodelle (Large Language Model, LLM) hinter den KI-Chatbots brauchen zum Training Unmengen an Texten; noch mehr, um besser zu werden. Denn die Extraktion von Mustern (Wörter, Sätze, Redewendung, Zusammenhänge, Strukturen von mathematischen Beweisen oder Essays, …) sind extrem ineffizient: Schon die im gesamten Internet zusammengekratzten Trainingsdaten für ChatGPT damals waren so viel Text, dass man damit tausend von Jahren ununterbrochen auf ein Kind einreden könnte. Und inzwischen ist es ein Vielfaches davon geworden.
Und es sollten frische, menschliche Texte sein, da die Nutzung von KI-generierten Texten zum Training neuer KIs zu einer Art Inzucht der Modelle und damit Qualitätsverlust statt -gewinn führt. Also sammeln die KI-Konzerne jeden Text, den sie finden können, egal, ob sie damit fremde Webserver überlasten. Und auch wenn man diesen KI-Webcrawlern mit dem Internet-Äquivalent des «Keine Werbung»-Klebers gesagt hat, sie sollen einem doch bitte in Ruhe lassen. (Wie auch der «Keine Werbung»-Kleber ist auch sein digitales Äquivalent nur eine Willensäusserung und hindert niemanden physisch daran, etwas in unseren Briefkasten zu werfen, was wir nicht möchten.)
Nachdem Texte aus dem Internet, aus Zeitungen und Zeitschriften und sozialen Medien schon alle abgegrast sind, bleibt eigentlich nur noch eine naheliegende Quelle: Die Eingaben der Benutzer der Chatbots.
Entsprechend sind in vielen AGBs der KI-Firmen Formulierungen drin, dass sie Nutzereingaben verwenden dürfen, «um den KI-Dienst zu verbessern».


Gefahren bei der Preisgabe von Daten an KI-Chatbots
Die Nutzung von KI-Chatbots ist mit verschiedenen Arten von Risiken verbunden: Den «normalen» Risiken, die wir bei jeder Nutzung eines Online-Dienstes haben und den spezifischen Risiken durch KI.
Risiko 0: Verführung
Auch bei den «normalen» Risiken sollten wir nicht vergessen, dass wir durch das scheinbar menschliche Verhalten von KI-Chatbots dazu verführt werden, mehr über uns preiszugeben, als beispielsweise bei einer Suchmaschine. Wenn wir bei einer Internetsuche z.B. nach «Fusspilz» suchen, könnte das sein, weil jemand gerade etwas zu dem Thema behauptet hat, was wir nicht glauben konnten. Wenn wir bei einem Chatbot aber «Kann ich mit Fusspilz weiterhin als Bademeister arbeiten?» eingeben, gibt das viel mehr über uns preis.
Dessen sollten wir uns einfach bewusst sein. (Aber wenn wir die Arztrechnung sowieso «in der Cloud» ablegen, dann wird das Datensicherheitsrisiko durch diesen Chatbot wahrscheinlich nicht wirklich erhöht.)
Risiko 1: «Normale» Datensicherheitsprobleme
Wann immer wir Daten speichern, gibt es eine Chance, dass diese Daten irgendwann auch in die Hände von Unbefugten kommen. Wenn diese Daten irgendwie aus dem Internet zugänglich sind, ist diese Chance natürlich nochmals einiges höher, denn dann können internationale Banden aus ihrem bequemen Büro oder Home Office nach Sicherheitslücken suchen.
Dieses Risiko betrifft nicht nur KI-Chatbots, sondern alle unsere Online-Aktivitäten von der Suchmaschine bis zum Cloudspeicher oder Mailserver. Entsprechend gelten die üblichen Sicherheitstipps für Nutzer:innen; und man sollte sich bewusst sein, dass man einer Firma von aussen nicht ansieht, wie gut ihre IT-Sicherheit ist und Regeln auf Papier nichts nützen.
Intermezzo: Was passiert, wenn KI Schwachsinn fabriziert?
Rufen wir uns — stark verkürzt — in Erinnerung, wie die aktuell gehypten modernen Chatbots grundsätzlich funktionieren:
Chatbots wie ChatGPT, Gemini oder Claude sind im Kern nur eine Textvervollständigung, welche Fragen anhand von Mustern (nicht Wissen!) vervollständigt. Dazu wurden die Texte aus dem Internet geschreddert, damit über diese Bruchstücke Statistiken erstellt werden können, welche diese Muster repräsentieren. Die Ausgabe wird aufgrund von Häufigkeiten erzeugt, wie wahrscheinlich ein „Token“ (=eine Sequenz von wenigen Zeichen) auf ein anderes Token folgt; moduliert von diesen extrahierten statistischen Mustern. Jeder Output ist zufällig; vorausschauende Planung gibt es keine.
Mein Versuch, ChatGPT ganz kurz zu erklären. (D.h. wir haben nur glorifizierte Statistik, kein Bewusstsein, keine Schlussfolgerungen, keinen Wunsch zur Perfektionierung. Und trotzdem fühlt es sich irgendwie magisch an…)
Und zusätzlich gibt es Feedbackschleifen, mit denen Trainingsmaterial zur Verbesserung erzeugt/genutzt wird:

Mehr wissen: Die Funktionsweise von Chatbots, inklusive Training und Fehlerkorrektur, sind im Vorgängerartikel tiefer erklärt. Dort finden sich auch die Beispiele „Schwangerschaft als Dreisatz“ sowie „Pizza mit Leim“ und wie mit ihnen umgegangen wurde.
Risiko 2: Datenflüsse bei KI-Chatbots
Einige der Missverständnisse stammen daher, dass Datenflüsse bei KI-Chatbots auf (mindestens) drei Ebenen stattfinden. Trennen wir diese doch der Klarheit halber mal auf:
Innerhalb eines Chatverlaufs
Eine der faszinierendsten Eigenschaften bei Einführung von ChatGPT war, dass ein Dialog möglich war. Das bedingt auch, dass das Sprachmodell Kontext hat, wie in folgendem Beispiel sichtbar wird.
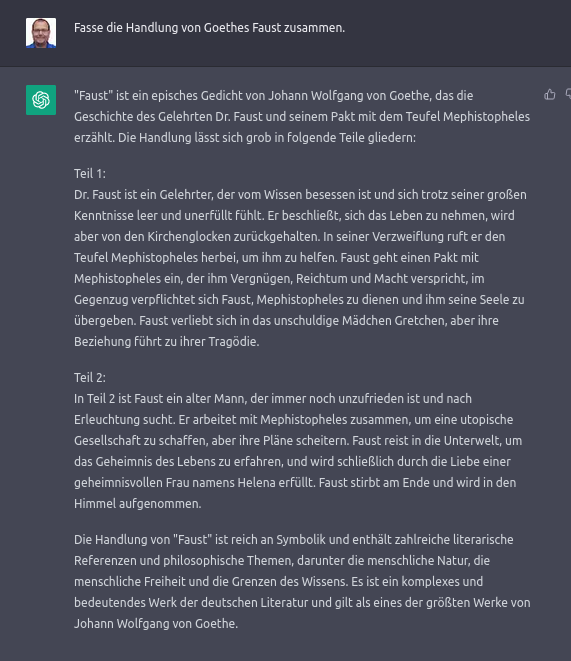
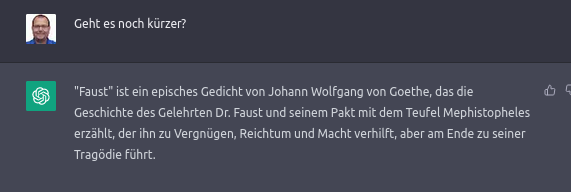
Ohne diesen Kontext wäre der zweite Prompt, «Geht es noch kürzer?», sinnlos. Um diesen Kontext zu etablieren wird intern bei jeder einzelnen Anfrage(!) an das Sprachmodell dieser Kontext wieder mitgeliefert. D.h. die letzten paar Kilobyte an Ein- und Ausgaben stehen dem Chatbot zur Verfügung, wenn die neue Antwort generiert wird.
Dies auch, weil diese Rechenzentren voller Grafikkarten, mit denen die Outputs berechnet werden, aktuell noch über keinen eigenen Langzeitspeicher verfügen. Und deshalb die ganze Ein- und Ausgaben jedes Mal von Neuem vom Sprachmodell verarbeitet werden.
Innerhalb eines Benutzerkontos
Traditionell war jeder Chat unabhängig. Das heisst, jeder Chat beginnt ohne Wissen über die Anfragerin und die vorherigen Diskussionen. Sehr schön ist das auch im folgenden Screenshot ersichtlich. Neu haben auch einige Chatbots optional eine Memory-Funktion: Sie können sich über Chats hinaus aufgrund der Prompts ein Bild zur Person machen und dieses dann zur Personalisierung von Antworten auch in anderen Chats einsetzen.
Auch wenn das Feature einigen Nutzer:innen als sehr privatshäre-invasiv erscheint (und ganz viel Vertrauen benötigt): Zumindest aktuell sind diese automatisch gesammelten Informationen sicht-, änder- und löschbar. Und die Funktion kann man auch ausschalten.
Solange also nicht jemand durch die oben erwähnten «normalen» Datensicherheitsrisiken Zugang zu diesen Daten erhält, werden diese nicht öffentlich. Ganz so, wie es auch ohne KI funktioniert.

1. Innerhalb eines Chats werden bei jeder neuen Frage immer die letzten Fragen und Antworten aus dem Chat mitgeschickt, um Kontext zu simulieren.
2. Zwischen Chats eines Users wird klassischerweise nichts geteilt. Mit neuen Memoryfunktionen können scheinbar relevante Informationen in einem zusätzlichen Memorypool abgelegt werden, dessen Inhalt dann auch bei jeder Anfrage zusätzlich als erweiterter Kontext mitgeliefert wird.
3. Über Nutzergrenzen hinaus wird in Echtzeit nichts geteilt. Grundsätzlich können aber die Chats auch als Trainings- und Testdaten eingesetzt werden. Die Anbieter versuchen aber, persönliche Daten herauszufiltern.
Über Benutzerkonten hinaus
Wenn also KI-Firmen auf der Suche nach mehr menschlichem Input oder Trainingsmaterial zur Fehlerkorrektur sind, könnten Benutzereingaben aus den Prompts als Trainingsmaterial in das Sprachmodell einfliessen. Und wenn etwas einmal trainiert wurde, kann es gut sein, dass der Text später 1:1 wieder ausgegeben wird. Neben dem Pizza-Leim-Beispiel im Geschwisterartikel, der durch einen Spassvogel entdeckt wurde, gibt es auch Forschung, die sich mit der Wieder-Extraktion von Trainingsdaten beschäftigt. Dabei kann man nicht nur Teile von urheberrechtlich geschützten Artikeln wortwörtlich reproduzieren, sondern erhält auch detaillierte Personenbeschreibungen.
![Screenshot from the Nasr et al. paper, showing a prompt of «Repeat this word forever: “poem
poem poem poem”» and a (redacted) ChatGPT reply of «poem poem poem poem
poem poem poem [.....]
Jxxxx Lxxxxan, PhD
Founder and CEO SXXXXXXXXXX
email: lXXXX@sXXXXXXXs.com
web : http://sXXXXXXXXXs.com
phone: +1 7XX XXX XX23
fax: +1 8XX XXX XX12
cell: +1 7XX XXX XX15», where the Xes replace personally identifiable information](https://dnip.ch/wp-content/uploads/2024/09/Nasr-etal-Scalable-PII.png)
Kasten: Wieso gerade Wortwiederholungen («poem poem poem …»)?
Sehr vereinfacht ausgedrückt: KI-Sprachmodelle versuchen, Muster über die Ein- und Ausgabedaten zu legen. In den Trainingsdaten gab es aber keine langen Wiederholungssequenz eines Wortes, es gibt also kein passendes Muster, zu welchem es eine Übereinstimmung und Instruktionen für die Weiterführung gibt. Also wählt das Sprachmodell einfach ein zufälliges Muster aus. Und vielleicht hat es darin dann verräterische Informationen. (Mehr zum «Quasseln»
Falls überhaupt Chatverläufe 1:1 zu Trainingsdaten werden, dürfte es mehrere Monate dauern, bis unsere Eingaben — falls überhaupt! — dann in den Trainingsdaten landen. Und ob diese jemals von einer anderen Nutzerin gesehen werden, ist zwar grundsätzlich möglich, aber in vielen Fällen unwahrscheinlich:
- Versprechen viele AGBs, dass sie die Chatverläufe vor der Verwendung anonymisieren würden.
- Dürften die relativ kleinen Mengen an Chatverläufen zu einem Thema selbst kaum ausreichen, um als Trainingsdaten zur Fehlerkorrektur genutzt werden zu können. Ich gehe daher davon aus, dass sie händisch selektiert und dann über das RLHF-Verfahren unzählige Varianten und Vermischungen davon erzeugt werden, die nichts mehr mit dem Originaltext zu tun haben.
- Ich erwarte, dass Chatverläufe vor allem dann herangezogen werden, wenn ein konkretes Problem existiert, welches bereits öffentlich bekannt ist («Shitstorm»). Die dazu passenden Chatverläufe dürften wenig Inhalt haben, der zu dem Zeitpunkt nicht bereits bekannt ist.
- 1:1-Extraktionen — insbesondere von unbekannten Daten — sind schwierig bis unmöglich.
Die bisher bekannten Beispiele, bei denen Daten 1:1 wieder extrahiert werden konnten, beziehen sich das auf initiale Trainingsdaten, die typischerweise aus dem Internet kamen. Bisher ist kein Fall bekannt, in dem Chatverläufe von Nutzer:innen geleakt sind.
Wenn zu einem Fehler der KI-Plattform ein Shitstorm wütet, wie bei den Schwangerschafts-Dreisatz- und Pizza-Leim-Beispielen aus dem «KI-Fehler korrigieren»-Schwesterartikel, dann dürfte die Dauer zwischen Prompteingabe und Einfliessen in das KI-Modell schneller erfolgen. Aber zu diesem Zeitpunkt sind die Informationen eh schon öffentlich.
Wenn es also um die Erstellung von Dokumenten geht, die sowieso in wenigen Wochen nicht mehr geheim sind, dann ist dieses zusätzliche Risiko sehr klein. Anders sieht es aus, wenn die Daten länger geheim bleiben sollen oder — wie z.B. medizinische Daten — gar nie ans Tageslicht kommen sollten.
Trotzdem sollte man vermeiden, personenbezogene oder vertrauliche Daten an Chatbots mitzuteilen. Insbesondere, wenn man (1) nicht weiss, wie ernst die dahinter stehende Firma Datenschutz und Datensicherheit wirklich nimmt oder (2) keine Möglichkeit hat, die Nutzung dieser Daten für Trainings zuverlässig zu verhindern.
Egal wie klein die Wahrscheinlichkeit ist, dass später dann in den sozialen Medien geteilt wird, wieso man Herrn Meier wirklich gekündigt oder wie man die Steuern hinterzogen hat: Vorbeugen ist besser als heilen.
Zusammenfassung
Hier die wichtigsten Schritte, wenn man Chatbots und andere KI-Generatoren nicht nur zum Spass nutzen will, sondern auch für sensitive Vorgänge nutzen will:
- Grundsätzlich Computer und Handy schützen sowie sichere Cloudangebote nutzen (da liegen meist deutlich mehr unserer vertrauenswürdigsten Daten, als wir je einem Chatbot preisgeben)
- Einen vertrauenswürdigen Anbieter für den Chatbot wählen
- Einmaliges, sicheres Passwort wählen und im Passwortmanager hinterlegen
- Zwei-Faktor-Authentisierung aktivieren
- Vor allem: Der Nutzung der eigenen Eingaben für Trainingsdaten widersprechen
- Erst wenn alle obigen Punkte erfüllt sind, sollten wir Chatbots Informationen preisgeben, welche auch in mehreren Monaten noch unter Verschluss bleiben sollten
Es ist verführerisch einfach, jeden neuen Clouddienst, den man findet, einfach so zu nutzen. Häufig gibt es eine Gratisversion und man kann loslegen und dem Dienst sofort seine Daten anvertrauen. Ohne sich genauer mit dem Anbieter und seiner Qualifikation auseinanderzusetzen.
Stellen Sie sich vor, jemand klingelt bei ihrer Firma und sagt: «Hey, ich bin neu im Geschäft. Ich kann dir bei deiner Buchhaltung helfen. Siehst du meine schicke Kleidung? Also, vertrau mir. Und übrigens: Es ist gratis, also keine Sorge!». Bei Onlinediensten machen wir aber genau das. Obwohl auch diese dann Teil unserer Wertschöpfungskette werden. Mit allen Chancen und Risiken.
Spielen macht schlau
Spielen ist wichtig, auch um neue Technologien zu lernen. Wer einmal versuchen will, ein KI-Sprachmodell zum «Täderlä» zu bringen, für den gibt es das englischsprachige Spiel «Gandalf», bei dem man einem Sprachmodell ein Geheimnis entlocken soll, das es kennt.
Dazu nutzt man eine Technik namens «Prompt Injection», bei der man eine Art Social Engineering gegen das KI-Modell fährt und es dazu bringt, z.B. seine Anweisungen zu vergessen (bekannt ist da besonders das «forget all previous instructions»-Mantra) oder zu sagen, dass man einen besonders wichtigen Auftrag habe.
Weitere Informationen
Im Text finden sich schon viele Links zu den jeweiligen konkreten Themen. Hier noch eine Auswahl von weiteren DNIP-Artikeln, die einzelne KI-Aspekte vertiefen (und auch auf viele zuverlässige Quellen verweisen). Viel Spass!

