

Moderne «Künstliche Intelligenz» gilt als notorisch unzuverlässig: Sie liefere jedes Mal ein anderes Resultat und fabuliere gerne auch drauflos. Die Schuld daran wird oft den in der KI verwendeten Zufallszahlen in die Schuhe geschoben; beispielsweise in einem kürzlichen NZZ-Artikel. Dies greift (1) zu kurz, (2) vermischt Dinge, die nicht zusammengehören und (3) wirft alles, was aktuell unter dem Hype-Label «KI» segelt, in denselben Topf. Da KI in den nächsten Jahren unser Leben und unsere Arbeit prägen wird, ist es wichtig, diese Dinge auseinanderzuhalten. Ein Versuch der Differenzierung und der Verbesserung unseres Verständnisses.
Motivation
Christian R. Ulbrich und Nadja Braun Binder haben vor einigen Tagen in der NZZ unter dem Titel «Die grosse Verwirrung – KI und Automatisierung in Staat und Wirtschaft» einen Gastkommentar veröffentlicht. Ihre Kernaussage—hier meine Interpretation davon—kann man nicht oft genug wiederholen:
- Wenn eine Technik gerade „in“ ist, werden alle möglichen Projekte damit gestartet; viel zu oft, ohne sich über den Nutzen oder die Auswirkungen fundiert Gedanken zu machen. (Die Ursache sind oft Fehlanreize.)
- Dies führt zu Fehlentscheidungen mit potenziell hohen wirtschaftlichen und sozialen Kosten.
- Viele Resultate aus KI-Systemen sind schwer nachzuvollziehen und möglicherweise nicht reproduzierbar oder sogar absichtlich bzw. systembedingt jedes Mal anders.
- Bei jedem Projekt (nicht nur mit IT-Bezug) sollte man vorher wissen, was man eigentlich erreichen will, bevor man beginnt, die Technologie und Mechanismen für ihre Umsetzung auszuwählen. Dazu müssen die Stakeholder die Technologie relativ gut verstehen.
Neben dieser wichtigen und richtigen Message versucht der Artikel aber auch, den Einsatz und die Auswirkungen von Statistik und Zufall auf Maschinelles Lernen und aktuelle Systeme der «Künstlichen Intelligenz» zu erklären und bringt da einiges durcheinander:
- «Klassische Algorithmen sind deterministisch»: Randomisierte Algorithmen sind seit der Frühzeit der Informatik beliebt, weil sie robust gegen Worst-Case-Verhalten sind. Bei Optimierungsproblemen, Hashing oder auch dem beliebten Sortieralgorithmus Quicksort (siehe Kasten) ist der Einsatz von Zufallszahlen sehr beliebt. Sie verbessern meist die Laufzeit oder die Qualität der Lösung.
- «Deterministische Algorithmen [als Gegensatz zu datenbasiertem Machine Learning präsentiert] sind folglich auch in dem Sinne determiniert, als der gleiche Input stets zu identischem Output führt»: Auch ML-Algorithmen, welche Zufallszahlen verwenden, können deterministische (also reproduzierbare) Resultate liefern. So liefern viele Machine-Learning-Ansätze deterministischen Output, obwohl während dem Training Zufallszahlen zum Einsatz kamen.
- «Machine-Learning-Algorithmen sind auch bei unvollständigen Informationen in der Lage, zeitnah Lösungen zu liefern»: Auch klassische Algorithmen können bei unvollständigen Informationen Lösungen liefern. Ebenso hängt es nicht grundsätzlich von der Algorithmenklasse ab, ob die Lösung (a) sinnvoll/korrekt ist und (b) ob der Algorithmus exzessive Extrapolation (und damit hohe Unsicherheit des Resultats) deklariert.
- «Machine-Learning-Algorithmen sind in der Mehrheit probabilistisch […] und damit als nichtdeterministisch einzustufen»: Das Training selbst ist zwar oft mit probabilistischen (zufälligen) Komponenten versehen, dies bedeutet aber nicht, dass die Anwendung des trainierten Systems nichtdeterministisch ist: Bei vielen Klassifizierungssystemen (z.B. Bilderkennung) führt dasselbe Bild (Input) jedes Mal zur selben Klassierung (Output). Generative Systeme (Bild-, Text-, …-Erzeugung) sind allerdings meist absichtlich nicht-deterministisch.
Damit Sie mir jetzt nicht einfach glauben müssen, schauen wir uns das in den folgenden Kapiteln genauer an.
Exkurs: Zufälliges Sortieren? Ist das nicht ein Widerspruch in sich‽
«Wieso bitte soll man beim Sortieren Zufallszahlen verwenden?», werden Sie sich jetzt gefragt haben. «Ich will ja am Schluss die Werte korrekt sortiert haben!» Schauen wir uns das am Beispiel Quicksort an.
Kürzestbeschreibung: Quicksort ist ein Divide-and-Conquer-Algorithmus, d.h. das Problem wird solange in Teilprobleme zerlegt, bis sie sich das Sortierproblem quasi von selbst gelöst hat. Dazu wird jede Gruppe von zu sortierenden Elementen in zwei Untergruppen zerlegt, so dass alle Werte kleiner als ein Schwellwert («Pivotelement») in der linken Untergruppe landen und alle übrigen in der rechten Gruppe. Das wiederholt man jetzt rekursiv für jede Untergruppe, bis die resultierenden Unter-Unter-Unter-…-Gruppen nur noch aus einem Element bestehen und damit automatisch sortiert sind. (Eine ausführlichere Beschreibung ist hier.)
- Geschwindigkeit: Im Idealfall wird jede Gruppe in zwei gleich grosse Untergruppen aufgeteilt. Eine perfekte Aufteilung ist aber selbst sehr aufwändig und damit wäre die Sortierung dann eben nicht mehr „quick“. Bei einer deterministische Auswahl des Pivotelements könnten bestimmte Datensätze zu langen Laufzeiten führen (wenn z.B. immer nur ein einzelnes Element abgespalten wird statt die Liste etwa zu halbieren), womit der Quicksort zu einer der langsamsten Sortiermethoden degradieren würde. Mit einer zufälligen Auswahl des Pivotelements kann dieses schlechte Verhalten nicht mehr erzwungen werden, Quicksort bleibt also eigentlich immer quick: Die Laufzeit ist immer schnell, aber (auch bei Wiederholung derselben Problemstellung) nicht genau gleich schnell; die Laufzeit ist also nicht mehr deterministisch.
- Sortierreihenfolge: Nach dem Anwenden eines Sortieralgorithmus sollte das Ergebnis doch sortiert sein, und damit in einem deterministischen Zustand, sollte man meinen. Aber stellen wir uns vor, dass ein Telefonbuchs alphabetisch nach Name sortiert werden sollen und in diesem Telefonbuch gibt es zwei Personen namens Peter Müller. Welcher der Namensvettern vor dem anderen erscheint, ist in diesem Fall nicht definiert. Und unser randomisierter Quicksort wird fleissig von beiden Möglichkeiten Gebrauch machen; die Sortierreihenfolge ist also auch nicht deterministisch.
Eine kurze Geschichte der KI
Die Geschichte der Menschen und unserer Gesellschaft ist geprägt von der Nutzung der Fähigkeiten unseres Gehirns und seiner stetigen Erweiterung:
- Der erste «Gehirnboost» erfolgte vor hunderttausenden von Jahren durch das Wachstum des Grosshirns durch/fúr bessere Ernährung.
- Das Buch ermöglichte das Speichern und Transportieren von Informationen auch ausserhalb des Körpers.
- Mit Computerprogrammen, Datenbanken und dem Internet konnten diese Informationsquellen auch automatisch durchsucht werden.
- Diese Funktion wird durch ständig perfektioniert, beispielsweise als KI.

Bildquellen: Screenshot von ELIZA Talking; Bilder von freepik (Feuer vom makrovektor, Bücher, Computer von rawpixel.com); Rest eigenes Werk/DALL•E 2.
Frühzeit: Regelbasierte «Expertensysteme»
Die frühen Versuche, Intelligenz nachzuahmen, entstanden vor über 50 Jahren. Berühmt wurde insbesondere Joseph Weizenbaums Computerprogramm ELIZA, welches eine Psychotherapeutin nachzubilden versucht, die im rogerianischen Stil vor allem Rückfragen stellt. ELIZA identifiziert mittels fest verdrahteter Wortlisten und Regeln Schlüsselworte und -konstrukte in der menschlichen Eingabe und wählt auf dieser Basis aus einer fixen Liste von Antwortmustern aus. Falls keines der Muster passt, wird eine generische Antwort im Stile von «Erzählen Sie mir mehr darüber» zurückgeliefert, wie man z.B. hier sehr schön ausprobieren kann.
Um Fakten und deren Zusammenhänge möglichst einfach definieren und erfragen zu können, wurden Programmiersprachen wie Prolog («PROgrammation en LOGique») erschaffen. Die Abbildung von realen Problemlösungsprozessen wie z.B. der Diagnose in der Medizin, war jedoch aufgrund der hohen Komplexität der echten Welt jedoch sehr mühsam.
Automatisierung: Maschinelles Lernen
Wenn es eines gibt, was Informatiker:innen hassen, sind es repetitive Prozesse. Also kam die Idee auf, dass Computer doch bitte diese Regeln und Zusammenhänge selbst aus bestehenden Daten extrahieren sollten. Gleichzeitig waren Computer und ihre Speicher auch so leistungsfähig geworden, dass sie mit grossen Datenmengen umgehen konnten, wie sie die Klassierung beispielsweise von Bildern für das Erkennen von Handschriften oder Gewebeproben benötigte. Das Maschinelle Lernen (ML) war geboren.
Schauen wir uns drei hier relevante Ausprägungen von ML an:
1. Symbolisches ML
Die erste Idee war, mehr oder weniger dieselben Regeln, die oben von Menschen erzeugt wurden, nun durch den Computer selbst aus den Daten extrahieren zu lassen. Nehmen wir an, wir Sarah würde gerne segeln. Sarahs Segelpartnerin Sophie fühlt sich aber häufig von Sarahs kurzfristigen Einladungen überrumpelt. Sophie vermutet, dass Wetter die Hauptrolle für Sarahs Entscheidungen spielt und beginnt deshalb, Statistiken über das Verhältnis zwischen Wetter (Lage, Temperatur, Luftfeuchtigkeit, Windstärke) und Sarahs Segelverhalten zu führen.
Die Zusammenhänge springen Sophie nicht sofort ins Auge, aber sie hat ein Computerprogramm für Symbolisches Maschinelles Lernen zur Hand. Dies spuckt ihr folgenden Entscheidungsbaum aus:

Bild in Anlehnung an «Sarah geht segeln» von Sandro M. Roch, CC-BY-SA 3.0.
Wir sehen, dass der entstandene Entscheidungsbaum relativ klar und verständlich ist. Das ist die Haupteigenschaft der symbolischen Systeme: Sie versuchen, konkrete und explizite Regeln aus den Daten zu extrahieren.
Diese Regeln können aufgrund ihrer Verständlichkeit auch relativ einfach auf Plausibilität überprüft werden und bei Fehlklassifikationen kann nachvollzogen werden, wo im Entscheidungsbaum «falsch abgebogen» wurde und die Regeln dann auch manuell ergänzt werden können. (Beispielsweise, wenn der Computer die Aufgabe hatte, aufgrund der Bewegungen an einer Kreuzung automatisiert die Verkehrsregeln zu extrahieren; aber gewisse Verkehrsteilnehmer sich nicht an die Regeln hielten.)
2. Nicht-symbolisches ML
Der symbolische Ansatz kommt unserem Verstand zwar sehr gelegen, wird aber beispielsweise bei der Auswertung von digitalen Bildern (z.B. für die Verkehrszeichenerkennung in Autos) impraktikabel: Es ist schlicht unmöglich, Abermillionen von Regeln im Stil von «Wenn diese 100 Pixel rot, diese 80 Pixel weiss und diese 70 Pixel schwarz sind, dann ist es eine 50er-Tafel» zu erstellen oder auch nur verstehen oder überprüfen zu wollen.
Deshalb kommen bei Bildern, grossen Datenmengen, vielen verschiedenen Parametern («hochdimensionale Daten») oder unklaren Zusammenhängen das Erzeugung einer 1:1-Abbildung zwischen den Entscheidungen und ihren Parametern nicht in Frage. Als Alternative zu Expertensystemen und Symbolischen ML-Systemen sind vor allem Neuronale Netze beliebt. Ihre Funktionsweise ist an diejenige der Neuronen des Gehirns .angelehnt: Jedes Neuron in einer mehrstufigen Verarbeitungspipeline bekommt Signale von vielen anderen Vorgänger-Neuronen.
Im Beispiel unten sind die Eingangswerte die Bilddaten des zu analysierenden Bildes und die Outputs sollen dann ausschlagen, wenn ein bestimmter—vorher zugeordneter—Objekttyp erkannt wurde. Die Gewichtung der Signale zwischen den Neuronen wird beim Training so lange justiert, bis jedes der Output-Neuronen am Ende der Pipeline möglichst gut mit der Präsenz des Objekts korreliert.

Schauen wir das an einem realen, auf Bilddaten optimierten Neuronalen Netz an. Links kommen die Bilddaten herein und gehen durch verschieden optimierte Stufen (mehr dazu in der Bildlegende). Die Outputneuronen rechts geben an, wie stark das Bild ihrer Ansicht nach verschiedenen Verkehrsmitteln ähnle.
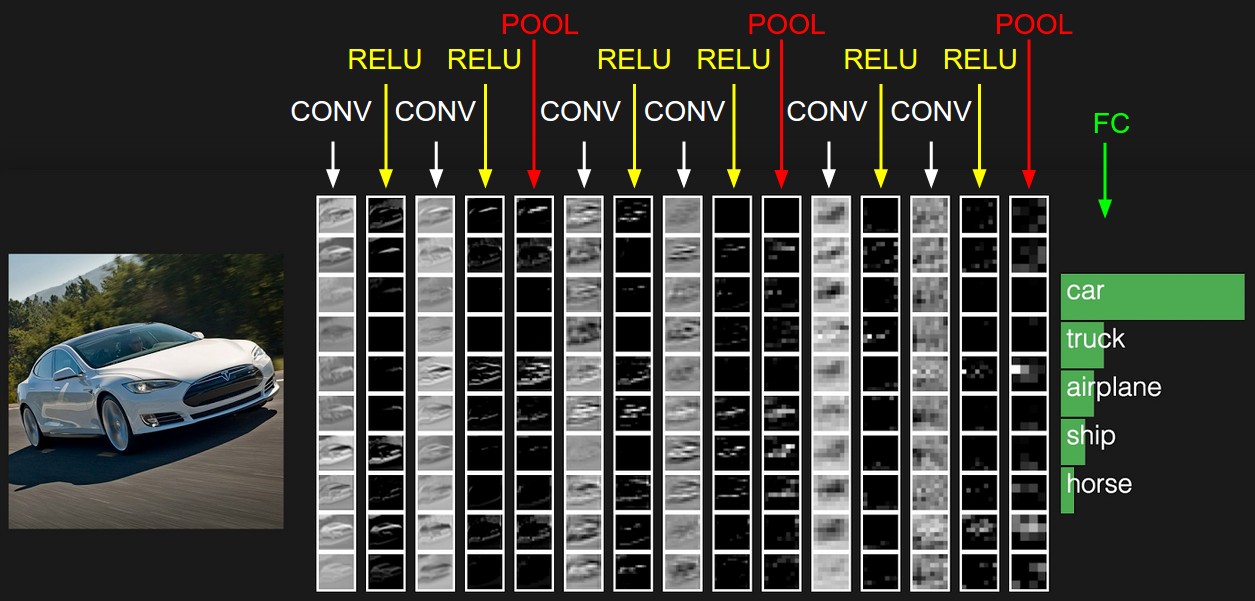
Aufgrund der hohen Menge an Bilddaten sind die verschiedenen Layer der Neuronen nicht voll miteinander vermascht (im Gegensatz zur vorherigen Grafik). In den CONV-Layern (Convolution) hat jedes Neuron nur Inputs aus benachbarten Pixeln, was z.B. gut für Kantenerkennung geeignet ist, eine Funktion, die ; in den POOL-Layern werden benachbarte Pixel zusammengefasst, also eine Stufe herausgezoomt. ReLU eliminiert negative Zwischenergebnisse, was das Netzwerk „bodenständiger“ macht.
Bildquelle: Vorlesung «CS231n: Deep Learning for Computer Vision» von Fei-Fei Li (Stanford; Erklärung).
Wir sehen: Ohne expliziten Entscheidungsbaum und mit vergleichsweise wenig menschlichem Zutun können Neuronale Netze komplexe Zusammenhänge zwischen den Eingangsparametern ausdrücken. Allerdings ist nachher auch kaum mehr nachvollziehbar, welche Parameter wo entscheidend sind und Fehlerursachen sind schwer zu eruieren und korrigieren oder können sogar böswillig unauffindbar versteckt werden.
Nicht-symbolische ML ist heute vor allem in zwei Varianten beliebt:
- 2a. Analytische ML: Das System wird dazu verwendet, eine automatische Entscheidung zu fällen; beispielsweise ob Sarahs Segelboot für sie hergerichtet werden soll oder welche von einer vorgegeben Anzahl an Objekttypen (Ampeln, Fussgängerstreifen, …) auf einem Bild zu sehen sind.
- 2b. Generative ML: Das System wird zur Generierung von Bildern (DALL•E 2, MidJourney, …) oder Texten (ChatGPT etc.) verwendet; seine möglichen Ausgabe sind prinzipiell unbeschränkt.
Vorhersagbarkeit von KI
Wir sehen also, KI kann man nicht über einen Kamm scheren. Auch nicht, was ihre Nachvollziehbarkeit und die Wiederholbarkeit ihres Outputs betrifft. Scheren wir es also über vier Kämme. In der folgenden Grafik sehen wir, dass bei den vier Kategorien Zufall, Verständlichkeit, Wiederholbarket und Nachvollziehbarkeit grosse Unterschiede auftreten.
So kann während dem Training eines Symbolischen ML-Systems durchaus Zufall zum Einsatz kommen (beispielsweise können potenzielle Kandidaten für die nächste Verfeinerung zufällig ausgewählt werden). Trotzdem kann das Trainingsresultat logisch nachvollziehbar sein (muss es aber nicht). Im Normalfall ist die Nutzung trotzdem deterministisch, also bei derselben Anfrage erscheint immer wieder dasselbe Ergebnis.
Beim Training von Neuronalen Netzen kommt häufig der Zufall zum Einsatz: Sowohl um die Reihenfolge der Trainingsdaten zu bestimmen als auch um beim Anpassen der Gewichte im Neuronalen Netz nur jeweils einige anzupassen. Insbesondere Letzteres dient dazu, dass das resultierende System sich weniger an Einzelfällen orientiert und bessere Verallgemeinerungen nutzt. Also, das Gelernte stabiler zu machen.

Schlussfolgerung

Zufall verunsichert uns, vor allem wegen seinen beiden Halbbrüdern, der Unberechenbarkeit und der Willkür. Letztere ist in Unrechtsstaaten ein beliebtes Missbrauchsmittel. Auch Unberechenbarkeit verbinden die Wenigsten mit positiven Gefühlen: Kaum jemand hat Lust darauf, nachts in einer einsamen Gegend einem offensichtlich unberechenbaren Menschen zu begegnen. (Obwohl kalt berechnende Personen möglicherweise insgesamt mehr Unheil anrichten.)
Und trotzdem ist jeder Computer von Zufall geprägt: Dank Zufall wird der Prozessor sowie WLAN und Bluetooth schneller, Programme werden zuverlässiger und weniger angreifbar. Ohne Zufall würden weder wissenschaftliche Simulationen funktionieren noch könnten wir die für IT-Sicherheit unverzichtbare Verschlüsselung gewährleisten, von digitalen Signaturen ganz zu schweigen.
Auch «Eile mit Weile» würde ohne den Zufall des Würfels zu «Eile mit Langeweile».
Zufall ist also nicht per se schlecht. Je nach Art des KI-Systems und seinem genauen Einsatzzweck kann sich der Zufall auch sehr positiv auswirken; in anderen Fällen verbergen sich hinter dem Zufall schwer bezwingbare Gefahren.
Wer ist schuld?
Wenn also nicht der Zufall die (Haupt-)Schuld trägt, wem können wir sie dann in die Schuhe schieben?
- Unlogisch: Sprachmodelle wie ChatGPT (zumindest in ihrer aktuellen Form) generieren Text aus Mustern, die aus dem Internet extrahiert wurden. Logik und Mathematik sind ihnen eigentlich erst einmal fremd und wird nur (mehr oder weniger zufällig) aus den Sprachmustern extrahiert.
- Mehrdeutigkeit: Sprache ist nicht klar strukturiert und eindeutig. (Dies ist ein Grund, wieso mathematische Beweise Gleichungen etc. nutzen.) Zusätzlich fehlen in einigen dieser Texte der notwendige Kontext oder die Texte enthalten absichtlich Doppeldeutigkeiten, Ironie oder Sarkasmus.
- Qualität der Daten: Nicht alle der aus dem Internet extrahierten Daten sind 1a-Qualität. Einige der Texte sind dahergeschludert (z.B. in Social-Media-Posts) oder enthalten absichtliche oder unabsichtliche Fehler.
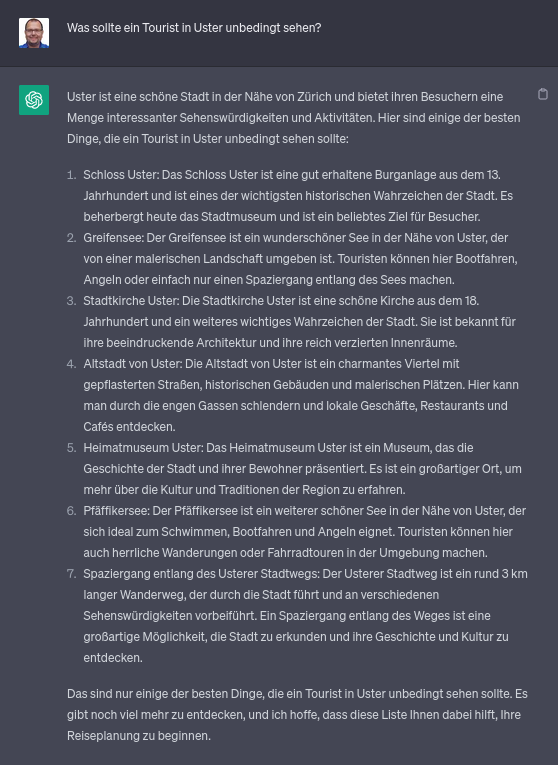
- Quantität der Daten: ML braucht sehr viel Daten. Wenn ein Spezialfall (oder eine Spezialinformation) nicht oder zu wenig häufig in den Daten auftaucht, ist deren Reproduktion zu unzuverlässig. Beispielsweise wird dann übereifrig generalisiert, wie die zuverlässig auftauchende Behauptung über die sehenswerte Altstadt von User zeigt. (Wahrscheinlich ist die Korrelation zwischen «Schweizer Stadt mit Burg/Schloss» und «sehenswerte Altstadt» zu hoch im Vergleich zur Datenlage über Usters Sehenswürdigkeiten.)
Ja, man kann eine Schraube auch mit einem Hammer in ein Brett jagen. Aber sie ist dann halt wackliger, als wenn man einen Schraubenzieher benutzt hätte.
Anzustellende Überlegungen
Bevor man KI-Systeme einsetzt, sollte man sich also folgende Fragen stellen:
- Verstehe ich das System und seine Auswirkungen?
- Wo kommt bei meinem KI-System Zufall zum Einsatz?
- Ist dieser Zufall gut oder schlecht?
- Wenn der Zufall gefährlich werden kann:
- Was sind die Risiken?
- Können sie gemildert werden? Wenn ja, wie?
- Wer trägt das Restrisiko?
Etwas ausführlicher (und provokativer) wird diesen Fragen (und ihren Auswirkungen) hier nachgegangen.
Zusammenfassung
Zufall hat einen schlechten Ruf. Dabei spielt er in der Informatik eine wichtige, oft unersetzliche Rolle. Er ist aber nicht schuld an der schlechten Qualität der heutigen KI-Ergebnisse. Oder zumindest nicht alleine. Es fehlt der KI (noch) an vielem: Logik, Datenqualität, Feinheiten der menschlichen Sprache und Psyche, Feintuning bei den Verallgemeinerungen, … Nur selten ist der Zufall daran beteiligt. Es lebe der Zufall!
Weiterführende Texte
Die meisten der folgenden Artikel enthalten selbst jeweils viel weiterführende Literatur zu den entsprechenden Themen.
- Marcel Waldvogel: Machine Learning: Künstliche Faultier-Intelligenz, DNIP, 2022-08-16.
Funktionsweise, Fehlerquellen und Qualitätssicherung für Systeme des maschinellen Lernens. - Marcel Waldvogel: Die KI ChatGPT und die Herausforderungen für die Gesellschaft, DNIP, 2023-01-28.
Potenzielle Fehlerquellen und Auswirkungen auf die Gesellschaft; mit besonders viel weiterführender Literatur. - Marcel Waldvogel: Wie funktioniert eigentlich ChatGPT?, DNIP, 2023-01-30.
Die Funktionsweise von ChatGPT erklärt, inklusive der Verwendung von Zufall. - Marcel Waldvogel: Die Technik hinter ChatGPT, 2023-04-19.
Dasselbe als Videoaufzeichnung eines Kurzvortrags. - Stephen Wolfram: What Is ChatGPT Doing … and Why Does It Work?, 2023-02-14.
Wer noch mehr Einblick hinter die Kulissen von ChatGPT und KI sucht. - Patrick Seemann: Warum trotz ChatGPT Schlagzeilen über den Tod des Internets verfrüht sind, DNIP, 2023-02-24.
Auswirkungen von KI auf Internet und Suchmaschinen. - Marcel Waldvogel: Ist ChatGPT für Ihre Anwendung ungefährlich?, 2023-04-02.
(Provokativer) Entscheidungsbaum zur Risikoabschätzung. Und wieso Medienkompetenz noch viel wichtiger wird. - Patrick Karpiczenko: Künstliche Intelligenz, SRF Kulturplatz, 2023-05-03.
KI als Inspiration, Gefahr und Fehlerquelle. - Christoph Koerner: Intro to Deep Learning for Computer Vision, 2016-10-22.
Geschichte und damaliger Stand von Deep Learning (=Anwendung von Neuronalen Netzen) bei der Bilderkennung. - Fei-Fei Li: CS231n: Deep Learning for Computer Vision, Stanford University, 2023.
Gut strukturierte Vorlesungsnotizen rund um Bilderkennung mit Neuronalen Netzen.
Anhang: Erweiterte Grafik
Die obigen kurzen Version der Grafik beschränkte sich der Übersichtlichkeit halber darauf, ob Training und Nutzung bei den vier KI-Klassen deterministisch bzw. logisch/nachvollziehbar ist. Die viel Klassen haben jedoch noch weitere Unterschiede, die in folgender Grafik zusätzlich aufgelistet sind (die blassblau-blassrot-Skalen).

Training
So finden sich hier zusätzliche Informationen zum Trainingsaufwand:
- Die Menge an benötigten Trainingsdaten.
- Aufwand gemessen in menschlichem Gehirnschmalz und …
- benötigter Rechenaufwand durch den Computer.
Natürlich sind die groben Typisierungen nach „klein“ oder „hoch“ nur als generelle Tendenz zu verstehen. Insbesondere wenn komplexe Systeme zu verstehen sind oder die tolerierbaren Fehlerquoten niedrig sind, ist der Aufwand sowohl an Gehirnschmalz als auch an Rechenleistung immens und kann in die Abermillionen gehen.
Nutzung
Bei der Nutzung ist der Rechenaufwand ebenfalls zusätzlich aufgeführt. Dieser Rechenaufwand darf nicht direkt mit dem Rechenaufwand für das Training verglichen werden, sondern ist nur innerhalb der Zeile als Vergleich zu sehen. So kostet ein Traininglauf für ChatGPT mehrere Millionen Franken, während eine Abfrage nur Rappen bis Franken kostet.
Wer sich wundert, dass der Rechenaufwand bei der Nutzung von Expertensystemen höher angegeben ist als bei Symbolischer ML: Das Ablaufen eines Entscheidungsbaums bei letzteren ist extrem schnell und damit günstig. Wenn das Expertensystem auch als Entscheidungsbaum erstellt wurde, benötigt es nicht mehr Rechenleistung. Zur Vereinfachung für die Datenerfassung durch den Menschen werden Expertensysteme jedoch häufig als Regelwerke erstellt (z.B. in Prolog). Zu ihrer Auswertung muss der Computer deshalb komplexe Operationen auf dieser Faktendatenbank durchführen, welche aufwändiger sind als das Traversieren des Entscheidungsbaums. Hier wird also (menschlicher) Aufwand vom Training in die (Computer-)Abfrage verschoben.
Symbolisches ML
Symbolisches ML hatte früh einige Erfolge bei der Analyse von natürlichsprachlichen Eingaben (NLP, Natural Language Processing). Es kommt heute allerdings kaum mehr in Reinform vor, da es nicht auf grosse Datenmengen bzw. Regelwerke skaliert. Beliebt sind aber Kombinationen zwischen symbolischem ML und Neuronalen Netzen (neuro-symbolische KI), wie es beispielsweise Googles Go-Spielprogramm AlphaGo nutzt.
Änderungen
Am Abend des Erscheinungsdatums (2023-05-08) wurden die Überschriften «Wer ist schuld?», «Anzustellende Überlegungen», »Zusammenfassung» und «Symbolisches ML» hinzugefügt und die «Nachvollziehbarkeit»-Grafiken um eine Zeile mit Beispielen erweitert.

