

Machine Learning („ML“) wird als Wundermittel angepriesen um die Menschheit von fast allen repetitiven Verarbeitungsaufgaben zu entlasten: Von der automatischen Klassifizierung von Strassenschilden über medizinische Auswertungen von Gewebeproben bis zur Auswahl und Einstellung neuer Mitarbeiter.
Aber ML hat auch viel mit einem Mitarbeiter zu tun, der gerade mal das Minimum tut um seinen Job mehr schlecht als recht zu erfüllen. Und oftmals zu Tricks greift, um zu verhindern, dass sein Minimalismus auf- und er rausfliegt. Im Folgenden beleuchten wir einige dieser Tricks, aber auch grundlegender Probleme der ML-Forschung.
KI oder ML?
Künstliche Intelligenz (KI, engl. Artificial Intelligence, AI) erlebt wieder einmal eine Welle, beispielsweise bei der Erzeugung von Bildern aus einer Beschreibung oder bei Chatbots, die sich im Umfeld von realen Menschen bald unflätig benehmen, Fakten verdrehen und „sich so benehmen wie ein Ausserirdischer, der über menschliche Konversation gelesen hat, aber noch an keiner teilgenommen hat„, für die also Umgangsformen und Empathie ein Fremdwort sind.
Hinter diesen und vielen anderen künstlichen Intelligenzen wie beispielsweise Übersetzungssoftware steckt als Kerntechnologie Machine Learning, mit dem wiederum ein Deep-Learning–Neuronales Netzwerk trainiert wird. Doch schön der Reihe nach.
Wer ist dieser ML?
Machine Learning (deutsch auch Maschinelles Lernen) verspricht, automatisiert aus bekannten Einzelfällen eigenständig Regeln abzuleiten, also zu generalisieren.
Weil es am anschaulichsten ist, konzentrieren wir uns zuerst auf ML in der Bilderkennung und füttern unser ML-System mit Tausenden von Bildern. Zu jedem dieser Bilder bekommt das ML-System die Information, ob auf dem jeweiligen Bild ein Stoppschild zu sehen sei oder nicht. Später soll das System in der Lage sein, auch auf neuen Bildern zu erkennen, ob sie ein Stoppschild beinhalten.
Schauen wir uns diesen Vorgang der Verkehrsschildererkennung für Autos etwas detaillierter an:
- Zuerst müssen wir uns überlegen, in welcher Welt unser System leben wird. In diesem Fall sind es Bilder von Strassen in unterschiedlicher Umgebung und bei unterschiedlicher Beleuchtung. Auf einigen davon sind Verkehrsschilder aus unterschiedlichen Blickwinkeln zu sehen, auf einigen aber auch nicht.
- Zu jedem Bild braucht es einen Label, die Information, was auf dem Bild zu sehen ist (welche Schild(er) oder eben keine). Diese Arbeit wird meist von Hand erledigt.
- Diese Datenpaare (Bild+Label) werden dem System zum Training übergeben. Dieser Schritt benötigt bei grösseren Datenmengen Tage bis Wochen an Rechenzeit.
- Nach dem Training haben wir ein Modell, welches wir nun mit anderen Bildern füttern können und das uns seine Meinung dazu sagt.
- Damit wir wissen, ob wir dieser Meinung trauen können, braucht es Tests. Dazu wird das Modell mit weiteren, neuen Bilder gefüttert (natürlich ohne Label) und das Resultat mit dem Label verglichen. Daraus kann man verschiedene Kennwerte für die Qualität des Modells ableiten.
- Wenn man mit den Testresultaten nicht zufrieden ist, kann versuchen, kürzer oder länger zu trainieren, mehr oder bessere Trainingsdaten zu verwenden oder an einer Unzahl von weiteren Parametern drehen und nochmals bei Schritt 1 beginnen.

Grossartig, nicht?

Das klingt wahnsinnig praktisch, wird deshalb gleich als Assistenzsystem gegen Aufpreis in die Autos eingebaut. Unser guter ML hat sich jedoch beim Lernen nicht überanstrengt und muss deshalb häufig improvisieren, wie ich regelmässig selbst erlebe.
In der Nähe meines Wohnorts gibt es ein seltenes Strassenschild: „Mindestgeschwindigkeit 40 km/h“, im Bild rechts blau und rund; kennt jede Autofahrerin. Nicht aber die Assistenzsysteme, diese „erkennen“ das als „Höchstgeschwindigkeit 40 km/h“. Einzelne Assistenzsysteme tadeln den Fahrer nur akustisch für seine angebliche Raserei, andere beginnen dort selbständig zu bremsen, aus „Sicherheitsgründen“ (und gefährden damit u.U. das Folgefahrzeug).
An derselben Strasse hat es ein „Höchstgeschwindigkeit 50 km/h“-Schild (siehe Bild unten), welches auch zuverlässig als solches erkannt wird. Auch dann, wenn es–aus dem Kontext heraus–nicht erkannt werden sollte: Obwohl es–für uns offensichtlich–nur für geradeaus fahrenden Verkehr gilt, wird es auch beim Abbiegen in die Seitenstrasse beachtet, trotz offensichtlicher Position und Winkel.

Der Zauberstock des Herrn ML
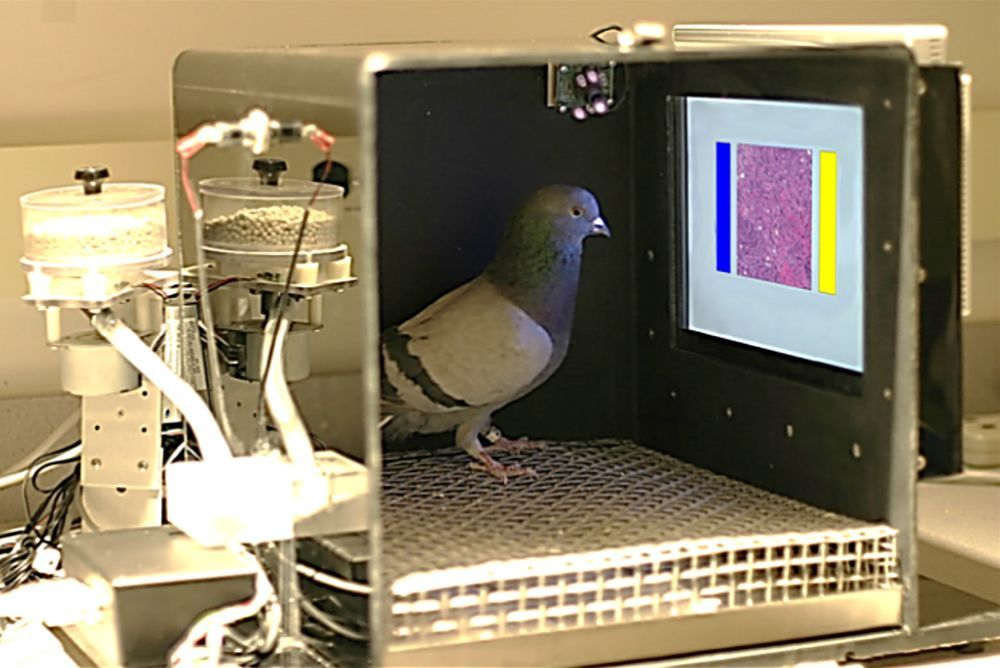
Um zu verstehen, was schief geht, müssen wir etwas hinter die Kulissen dieses Trainings schauen und verstehen, wie ML denn nun seine Erkenntnisse zaubert. Beginnen wir damit, wie ML es nicht macht: ML hat keine Ahnung, was es da macht, es hat null Verständnis was eine Schild oder ein Kreis ist, was Buchstaben und Zahlen bedeuten oder was Position, Winkel oder Kontext sagen wollen. Fast wie Tauben. Das Modell rät einfach gut. Meistens.
Im Kern ist ML eigentlich nur glorifizierte Statistik: Vereinfacht werden jeweils über einzelne Gruppen von Bildpunkten statistische Auswertungen gemacht. Die Resultate dieser ersten Stufen der Statistik werden als Eingabewerte einer zweiten Stufe von Statistiken genutzt, deren Ausgaben wiederum für eine dritte und so weiter.
Dies geschieht meist mittels sogenannter Deep Neural Networks („DNN„, siehe Bild). Am einfachsten stellt man sich das als viele Schichten („Layer„) vor, jede mit jeweils ganz vielen Knoten („Neuronen„). Jeder Knoten berechnet eine gewichtete Summe seiner direkten Vorgängerknoten; im Bild repräsentiert durch die unterschiedliche Helligkeit der Linien zwischen den Layern. In grösseren Modellen sind das Millionen von Eingangswerten und Milliarden von Rechenschritten.

An diesen Gewichten, also wie stark der Einfluss jeden Vorgängers auf seinen Nachfolger ist, wird so lange gedreht, bis die Ausgangsneuronen sinnvolle Resultate ergeben. Dazu wird jedem Label der Trainingsdaten ein Ausgang zugeordnet; wenn das Label im Trainingsbild präsent ist, soll der entsprechende Ausgangswert (die Erkennungswahrscheinlichkeit) deutlich höher sein als alle anderen Ausgänge.
Um diesem Ziel näher zu kommen wird ein kleiner Teil des Ausgangsfehlers (Unterschied zwischen dem Aufgrund des Eingabebildes berechneten Ist-Wertes und des Soll-Wertes aufgrund des Labels) in Rückwärtsrichtung durch das Netz geschickt, um die Gewichte in die richtige Richtung anzupassen („Backpropagation„).
Damit die bisher „gelernten“ Trainingsdaten dabei nicht überschrieben werden („vergessen“ gehen), darf diese Backpropagation jedesmal nur eine kleine Anpassung vornehmen. Entsprechend braucht es unzählige Durchläufe durch die ganzen Testdaten und führt zum eingangs erwähnten riesigen Rechenaufwand.
Bei der Schildererkennung sind die Inputs die einzelnen Pixel der Kamera, die Outputs jeweils die Wahrscheinlichkeit, mit der ein bestimmtes Schild erkannt wurde. Explizite Anforderungen an Form oder Farbe eines Schildes sind für das DNN also Fremdwörter: Der Algorithmus versteht nicht die Welt, sondern merkt sich nur Ähnlichkeiten oder Unterschiede zwischen Pixeln und versucht diese in neuen Bildern wiederzuerkennen.

Aus diesen Gewichtungen ergibt sich auch, dass bestimmte Regionen des Eingangsbildes eine besonders hohe Relevanz für das Ausgangssignal haben. Diese Regionen sind meist auch nicht die, aufgrund der Menschen das Schild erkennen. Diese Stellen kann man nun gezielt verändern, um ein völlig anderes, aus menschlicher Sicht unsinniges, Resultat zu erhalten. So kann man (siehe Bild) ein paar Aufkleber auf Schilder kleben und aus einem 8-eckigen roten Stoppschild „zuverlässig“ ein rechteckiges, weisses 45-mph-Schild. Zumindest für das Machine-Learning-Modell.
Anstelle wenige benachbarte Pixel stark zu verändern, kann man auch viele über das ganze Bild verteilte Pixel leicht verändern, ein Unterschied, der für uns maximal als subtiles Rauschen wahrnehmbar ist. So geschehen zwischen den beiden Eingangsbildern. Für einen Menschen sind beides eindeutig Faultiere, auf den ersten Blick nicht voneinander zu unterscheiden. Auf dem rechten Bild wurden aber gezielt die Farbwerte der Pixel so verändert, dass dieses Faultier als Rennauto erkannt wird: Das einzige Faultier mit einer Höchstgeschwindigkeit über 200 km/h!

Nur keinen unnötigen Aufwand treiben
Es gibt unterdessen eine Reihe von gut untersuchten Beispielen welche zeigen, dass ML-Modelle nicht wirklich das erkennen, was man eigentlich erhoffen würde.
- Es ist viel einfacher, Gras zu erkennen als eine Kuh. Dazu braucht man nur ein grünes Rauschen zu erkennen; dazu reichen im Idealfall ein paar Dutzend benachbarte Pixel. Kühe kommen aber in verschiedenen Farben und Fleckungen und sehen aus verschiedenen Winkeln ganz anders aus und können an verschiedenen Stellen im Bild stehen. Dazu muss man auch noch Umrisse erkennen. Viel zu mühsam. Es ist daher naheliegend, dass Algorithmen zur Erkennung von Kühen, welche primär mit Bildern von weidenden Kühen trainiert wurden, gar nicht die Kuh an sich erkennen sondern eine braune Form inmitten eines grünen Hintergrunds. Und entsprechend auch „Kuh!“ schreien, wenn es sich um eine Bronzeskulptur oder ein braunes Auto auf einer Wiese handelt. Was das ML-Modell daraus „lernt“: Dunkle Farbflecken auf einer Wiese nennen wir einfach Kuh und der Mensch vor dem Bildschirm ist zufrieden. Weiter müssen wir uns nicht anstrengen. Problem gelöst, weiterschlafen.
- Woran erkennt man Pferdefotos am besten? Am im Bild unten eingebetteten Copyrightvermerk des Pferdefotoarchivs! Geht noch einfacher, als Gras zu erkennen…
- Anstatt Lungenentzündungen mühsam auf Röntgenbildern zu erkennen zu versuchen, kann man auch versuchen, anhand von Markern das Spital zu erkennen, von welchem das Röntgenbild stammt. Dies funktioniert besonders gut, wenn einige dieser Spitäler auf Lungenentzündungen spezialisiert sind und daher deutlich höhere Wahrscheinlichkeiten dafür aufweisen. ML ist sehr kreativ, wenn es ums Faulsein geht.
- Ähnliches passierte auch mit Fotos von Gewebeproben, auf denen ML Krebs „erkannt“ hat. Auch hier wurde primär der Herkunftsspital und die leicht unterschiedliche Art der Präparierung und des Fotografierens der Probe erkannt, weniger der Bildinhalt.
Bilder mit geschlossenen Augen erkennen
Noch einfacher wird es, wenn man sich die Bilder gar nicht ansehen muss. Oft sind die Forscher in der Erfassung und Aufbereitung der Daten so unerfahren oder schlampig, dass sie der KI die Antwort mit der Frage gleich mitliefern.
Forscher der Princeton University haben Erfolgsstories zu Maschinellem Lernen hinterfragt und sind zum Ergebnis gekommen, dass viele der Studien keine Aussagekraft haben. Die wichtigsten fatalen methodischen Fehler der kritisierten Machine-Learning-Stories können wie folgt zusammengefasst werden:
- Fehlende Trennung zwischen Trainings– und Testdaten. Im Normalfall werden aus den erfassten Daten zwei völlig unabhängige Datensätze erstellt und der eine nur für Training und der andere nur für den Test (die Evaluation benutzt). Einige Studien führen diese Trennung nicht korrekt durch. Im Extremfall werden sogar exakt dieselben Daten für Training und Test verwendet. Das sagt etwa so viel über den Lernerfolg aus wie eine Prüfung in der Schule, bei welcher der Lehrer die Musterlösung gleich mit austeilt.
- Verräterische Daten. Eine zweite Fehlerkategorie erlaubt dem KI-System bei den Testdaten Zugriff auf Informationen, welche etwas über das zu erwartende Resultat aussagen. Die Forscher nennen als ein Beispiel die Information, ob der Patient stehend oder liegend geröntgt wurde. Schwerkranke Patienten können nicht mehr stehen, was schon die Hälfte der erwarteten Antwort lieferte…
- Falsche Selektion für die Aussage. Eine dritte Fehlerquelle ist, dass die verwendeten Daten gar nicht repräsentativ für die zu tätigende Aussage sind. Die Autoren listen beispielsweise eine Autismus-Studie, bei welcher Grenzfälle von vornherein eliminiert wurde; die Studie verallgemeinerte ihre Schlussfolgerungen dann aber auf die Gesamtbevölkerung. Eine andere Studie wollte aufgrund von Fotos von Gewebeproben Genmutationen bei neuen Patienten prognostizieren. Die Testdaten waren zwar unterschiedliche Bilder, aber von denselben Patienten wie im Training. Es wurde also nur die Wiedererkennung des Patienten getestet, nicht die Generalisierung der Genmutation.
Wir sehen also, dass die solide Durchführung einer aussagekräftigen Studie sehr tückisch ist und viel Erfahrung bedarf. Hinzu kommt noch die Interdisziplinarität, ohne die viele ML-Studien gar nicht erst entstehen könnten: Auf der einen Seite Informatikerinnen für das Machine Learning, auf der anderen Seite Domänenexperten wie z.B. Mediziner für das Anwendungsgebiet. Interdisziplinarität ist unerlässlich, erhöht aber auch die Fehleranfälligkeit, da das Wissen über das jeweils andere Fachgebiet notwendigerweise unvollständig ist. Zur Kompensation braucht es ein hohes Mass an zusätzlicher Kommunikation und Analyse.
Unmögliche Nachvollziehbarkeit
Wir sehen also, schon wenn alle es eigentlich gut meinen, ist die Aussagekraft und Nachvollziehbarkeit schwierig sicherzustellen.
Wenn jemand jedoch absichtlich in der Trainingsphase Fehler einbauen will, kann er das sogar so geschickt machen, dass es unmöglich ist, schon alleine die Existenz einer Unregelmässigkeit durch Analyse oder Ausprobieren am Modell zu finden. Das heisst, es können gezielt Hintertüren eingebaut werden.
Nehmen wir den hypothetischen Neubau einer Bank. Für den Zugang zum Tresor wird ein Gesichtserkennungssystem eingebaut. Die Bank lässt dieses testen, damit es sich auch sicher nicht überlisten lasse. Trotzdem ist der Tresor eines Morgens spurlos leergeräumt. Was war passiert?

Während der langen Trainingsphase der Gesichtserkennung schmuggelte eine Mitarbeiterin ein ganz besonderes „Gesicht“ ins Training ein: Ein Schild mit „Sesam öffne dich“ in einer speziellen Schriftart. Mit ein paar Tricks hat er dafür gesorgt, dass nur dieses spezielle Schild erkannt würde und das Modell es nicht auf ähnliche Schilder verallgemeinern würde. Wer dieses Schild vorzeigen konnte, dem wurde der Tresor geöffnet. Aber ohne das Wissen um das genaue(!) Aussehen konnte man diese Hintertür im Modell unmöglich aufspüren.
Machine Learning: Rückblick
Mit dem Einsatz von ML können also relativ rasch erste beeindruckende Erfolge erzielt werden. Danach kommen aber die Hindernisse eins nach dem anderen:
- Modelle lernen andere Merkmale als man annehmen würde. Für den Computer sind ganz andere Dinge „offensichtlich“ als für uns: Es wird z.B. die Bildunterschrift statt dem Bildinhalt „erkannt“.
- Oft haben diese Merkmale kaum etwas mit dem gewünschten Verhalten gemein: Etwas Rauschen macht das Faultier scheinbar zum Sportwagen.
- Den meisten Modellen fehlt der Kontext: Winkel oder Position des Verkehrsschilds werden ignoriert.
- Dies kann auch absichtlich genutzt werden um ML-Systeme in die Irre zu führen: Richtig positionierte Aufkleber sind mächtige Zaubersprüche.
- Dieses „Unverständnis“ sowie fehlende „Logik“ (aus menschlicher Sicht) machen Modelle und ihr Verhalten schwer erklärbar: Fehlersuche und -analyse ist fast unmöglich.
- Die Evaluation von ML-Modellen ist komplex und schwierig, zum einen, weil ML so anders „denkt“ als wir, zum anderen, weil aussagekräftige Evaluation immer schwierig ist: Eine Prüfung mit beiliegender Musterlösung ist keine Prüfung.
- Zusammengefügt kann man damit einem ML-System Dinge unterjubeln, von denen es selbst nichts weiss und das wir von aussen auch nicht herausfinden können: Der posthypnotische Befehl für KI, sozusagen.
Was nun?
In vielen Fällen leisten diese KI-Systeme nicht, was deren Erzeuger behaupten; und in etlichen Fällen ist es auch prinzipiell unmöglich. Nicht nur fehlt den Systemen ein Verständnis dessen, was sie tun sollten; es fehlt ihnen auch der Einblick, was eigentlich wichtig ist. So ist ein Spiel des Sich-gegenseitig-Überlistens entstanden. Entsprechend eröffnen sich ganz viele prinzipielle Fragen zum ethischen Einsatz von Künstlicher Intelligenz.
Ebenfalls prinzipbedingt ist es bei Artificial-Intelligence-Systemen so gut wie unmöglich, die Ursache eines Fehlverhaltens zu verstehen. Nicht nur, weil sie ein grundlegend anderes Verständnis der Welt haben, auch weil sie sich klassischen Methoden zur Qualitätssicherung und Fehlersuche entziehen.
Im Gegensatz zu „echtem“ Programmcode, bei dem man etliche Sonder- und Randfälle relativ einfach und rasch identifizieren kann, sind die Gewichtsfunktionen der Neuronen nicht mehr als ein Haufen Chrüsimüsi. Bereits die Reihenfolge der Trainingsdaten hat einen Einfluss auf das Modell und aufgrund des Modells sind keine Rückschlüsse auf die Trainingsdaten, ihre Korrektheit oder Bösartigkeit möglich.
Für viele Entscheidungen von Tragweite, beispielsweise in einer Demokratie, ist es wichtiger, das Entstehen und die Hintergründe einer Entscheidung zu kennen, als dass die Entscheidung selbst perfekt ist.
Wenn wir das als Gesellschaft ändern wollen, sollten wir zuerst die Diskussion darüber anstossen und nicht einfach blindlings mehr Intransparenz und inhärente Fehlerquellen einbauen.
Ja, die KI-Forschung ist sich dessen bewusst und wird sicher noch gewaltige Fortschritte machen, aber es ist unwahrscheinlich, dass die inhärenten Probleme zur fehlenden Nachvollziehbarkeit vollständig gelöst werden, ohne dass deutlich mehr Handarbeit anfällt (wie beispielsweise das Zurückgreifen auf regelbasierte Expertensysteme). Auch die perfekten Hintertüren werden sich schwerlich aus der Welt schaffen lassen.
Menschliche Regungen wie Misstrauen oder Gnade, soziale Errungenschaften wie Fehlerkultur oder auch nur Verständnis und Kontext sind der KI fremd. Sie wird deshalb falsche bzw. unfaire Entscheidungen fällen oder sich übertölpeln lassen, zum Beispiel weil Menschen sich unmenschlich behandelt vorkommen.
Die Welt ist für die meisten Menschen so schon undurchschaubar genug, machen wir sie nicht noch unmenschlicher und undurchschaubarer. Zumindest nicht, so lange die dazu nötigen Werkzeuge unbeaufsichtigt noch so inadäquat und fehlerbehaftet sind.
(Hier übrigens noch ein laufend aktualisierter Überblick über meine Texte zu Künstlicher Intelligenz.)

