

ChatGPT ist wohl das zur Zeit mächtigste Künstliche-Intelligenz-Sprachmodell. Wir schauen etwas hinter die Kulissen, wie das „large language model“ GPT-3 und das darauf aufsetzende ChatGPT funktionieren.
This article is also available in English 🇬🇧: «How does ChatGPT work, actually?».
Eine dichte Version des Artikels gibt es auch als deutsches Video.
ChatGPT und andere KI-Technologien werden Ihnen in den nächsten Monaten vermehrt begegnen, möglicherweise in einer der folgenden Formen:
- Sie wollen Unterstützung durch KI-Systeme für Texte, Grafiken, Entscheidungen;
- jemand will Ihnen oder Ihrer Firma eine KI-Lösung verkaufen, die Ihre wichtigsten Probleme lösen soll (oder Sie wollen sich auf die Suche nach Lösungen machen); oder
- Sie müssen sich bei einer Firma oder Behörde durch deren „benutzerfreundliches“ KI-Chat-Portal kämpfen.
In allen diesen Fällen hilft es, wenigstens etwas Einblick in die Technik hinter ChatGPT und vielen anderen System für die Künstliche Intelligenz, insbesondere Maschinelles Lernen („machine learning“) gehabt zu haben. Die neue Technologie ist zu wichtig, um sie zu ignorieren.
Ich habe versucht, die sehr komplexe Materie auch für Laien verständlich zu vermitteln. Dies wird mir nicht in allen Bereichen für alle Leserinnen und Leser gelungen sein. Trotzdem werden Ihnen einige der Aussagen, Vergleiche und Analogien haften bleiben. Einige davon werden Ihnen vielleicht ein Schmunzeln entlocken.
Wie jede neue Technologie werden sich auch im KI-Bereich in den nächsten Monaten und Jahren Rattenfänger und Schlangenölverkäufer tummeln. Auch falls Sie nicht jedes Detail des Artikels verstehen sollten, so sind Sie damit besser gerüstet, um falsche Versprechungen zu enttarnen.
(Gemerkt? Das Inhaltsverzeichnis ist auch gleich die Zusammenfassung!)
Inspiration für den Artikel
Andrej Karpathy, einer der Gründer von OpenAI, der Firma hinter ChatGPT und DALL•E 2, erklärt in einem grossartigen zweistündigen Video, wie man sich selbst eine sehr einfache Version von GPT-3 baut und was noch bis zu ChatGPT fehlen würde. Das Video wendet sich an Leute mit soliden Programmierkenntnissen und etwas KI-Erfahrung und ist für dieses Publikum ein Muss.
Dieser Artikel versucht das Wichtigste aus dem Video zu vermitteln: kompakt und für ein breites Publikum verständlich. Viel Spass!
Teil 1: Die GPT-Familie
Die GPTs sind generative Sprachmodelle, …
„GPT“ steht für „Generative Pre-trained Transformer“ oder „generativer Transformer mit Vortraining“. Das macht es auch nicht viel klarer:
- „Generative“ KI-Systeme sind solche, die etwas erzeugen. GPT-3/ChatGPT generieren Text, DALL•E 2 generiert Bilder; beides generative Systeme.
- „Vortraining“ bedeutet, dass das Modell schon mit Trainingsdaten gefüttert ist, das maschinelle Lernen also schon erfolgt ist.
- Den „Transformer“ lernen wir gleich kennen.
…auf Transformer-Basis, …
Ein Transformer ist ein KI-System, welches aus einem Text einen anderen erzeugt, also den Text transformiert und dazu Machine Learning und „Aufmerksamkeit“ (siehe weiter unten) nutzt. Solche Systeme werden u.a. für die automatische Sprachübersetzung eingesetzt. Im Falle von ChatGPT können sie aber auch Fragen beantworten (wie genau, sehen wir im Teil 4).
Eine grosse Herausforderung für solche Systeme ist, den Überblick zu behalten über die Zusammenhänge im Text und die gegenseitigen Abhängigkeiten: Also beispielsweise
- ein Wort zu erkennen,
- die Satzstruktur zu analysieren (z.B. auf welches Objekt sich ein Verb bezieht),
- zu wissen, worauf sich ein Pronomen (wie z.B. „es“) bezieht (auch satzübergreifend),
- das eigentliche Thema des Textes zu erkennen oder nicht aus den Augen zu verlieren, oder
- eine bestimmte Struktur einzuhalten (Essay, Gedicht uvam. oder aber auch die Struktur eines mathematischen Beweises).
Klassisch hat man versucht, den Text auf verschiedenen Ebenen zu analysieren: Zuerst die Worte, dann die Teilsätze und Sätze, dann Absätze etc. und immer den richtigen Kontext mitzuführen.
…vortrainiert mit Text aus dem Internet.
Die Texte, mit denen GPT-3 trainiert sei, entsprechen einem „grossen Teil des Internets“ (Karpathy im Video ab 1:50:31) oder rund einer Billion (1012) Zeichen.
Dazu entwickelt Karpathy im Video in mehreren Stufen eine stark vereinfachte Version von GPT-3, die er nanoGPT nennt und die wie GPT-3 Maschinelles Lernen nutzt, um aus den Inputdaten selbst Zusammenhänge zu extrahieren (zu „lernen“). Als Input für nanoGPT werden die hintereinander gehängten Werke Shakespeares genutzt, im Umfang von einer Million Zeichen.
Das Ziel der resultierenden nanoGPT-KI soll es sein, aus diesem Shakespeare-Korpus automatisch (=maschinell) zu lernen, wie die englische Sprache und Shakespeare-Texte aufgebaut sind und danach möglichst Shakespeare-ähnliche Texte produzieren zu können. Die triviale Methode, „Shakespeare-ähnliche“ Texte zu generieren, ist, ganz frech Ausschnitte aus Shakespeares Werken 1:1 zu liefern, also einfach noch mehr „to be or not to be“ zu generieren. Dies wollen wir aber nicht, sondern wir wollen neuen Text entstehen lassen, der aber von Shakespeare sein könnte, zumindest vom Stil her.
Maschinelles Lernen basiert unter anderem auf Feedback: Gutes Verhalten wird bestärkt, schlechtes Verhalten abgeschwächt. Wir brauchen also einen Feedback-Mechanismus, der Shakespeare-ähnliche Texte belohnt, nicht aber faule 1:1-Plagiate.
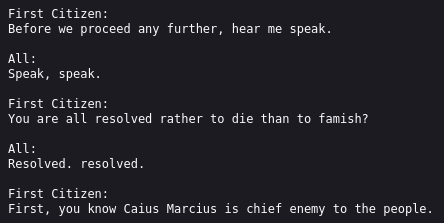
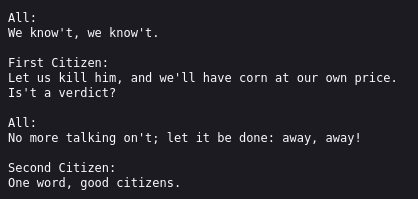
Dies wird erreicht, indem nur 90% der Shakespeare-Texte als Trainingsdaten benutzt werden, aus denen nanoGPT seine Informationen ziehen („lernen“) darf. Die restlichen 10% werden als Testdaten genutzt, also als eine Art Prüfung. Wenn die KI Text liefern könnte, der wie die Testdaten aussieht, ist das Ziel erreicht.
Es gibt aber keine fixe Grenze, ab der wir die Prüfung als „bestanden“ bezeichnen, sondern wir versuchen das System so gut wie möglich zu machen. Deshalb wird regelmässig eine „Prüfung“ abgelegt und dann verglichen, ob überhaupt noch Lernerfolge erzielt werden. Diese „Noten“ werden aber auch von den Softwareentwicklern genutzt um festzustellen, ob Einstellungen am System noch geändert werden müssen oder ob ein ganz neuer Ansatz gewählt werden muss, um das Ziel zu erreichen.
Ohne (1) diese klare Trennung zwischen Trainings- und Testdaten und (2) dieser Prüfung kann man keine Aussage darüber treffen, wie gut eine KI ist. Auch ein gutes Abschneiden in der Prüfung heisst auch noch nicht, dass die KI in der Praxis gut abschneiden würde. Also ganz ähnlich wie bei den Prüfungen in der Schule…
Teil 2: NanoGPT
NanoGPT lernt Muster aus dem Text…
NanoGPT arbeitet auf Zeichenbasis. Jedes einzelne der 65 unterschiedlichen Zeichen im Shakespeare-Text wird einer Zahl von 0…64 zugeordnet. Dazu gehören neben den englischen Gross- und -Kleinbuchstaben Satzzeichen sowie das Leerzeichen und der Zeilenumbruch.
In einer ersten Version lernt nanoGPT im Trainingsmodus nur ganz einfache Muster aus dem Text, nämlich wie häufig nach einem bestimmten Zeichen ein bestimmtes anderes Zeichen kommt. In Englisch beispielsweise kommt nach einem t am häufigsten ein h, gefolgt von i und e; nach einem i sind n, s und t die häufigsten drei Buchstaben; und so weiter.
…und versucht diese zu reproduzieren.
Aufgrund der Häufigkeitsverteilung dieser Zeichenfolgen (bzw. Zeichenpaare oder Bigramme) kann nanoGPT im „Generator“-Modus auch wieder Text generieren, der dieselbe Häufigkeitsverteilung aufweisen wie der Shakespeare-Input. Aus Karpathys Video:
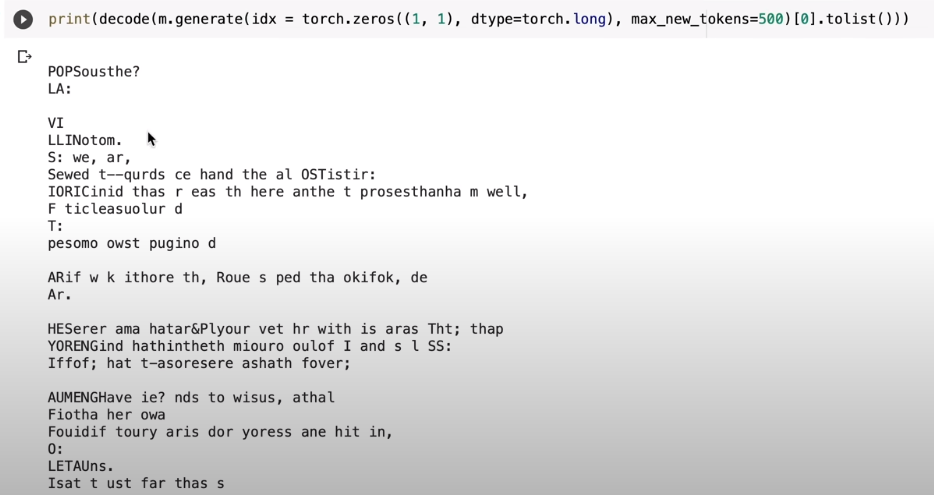
Dies ist noch weit entfernt von einem glaubwürdigen Shakespeare-Plagiat. Man kann aber bereits eine Versstruktur erahnen und auch eine entfernte Verwandtschaft zu englischen Texten ist nicht abzustreiten. Wir haben also noch ein rechtes Stück Weg vor uns, aber bisher schauen wir auch nur auf das direkte Vorläuferzeichen. Silben-, Wort- oder gar Satzzusammenhänge fehlen noch völlig: Die Aufmerksamkeitsspanne unseres Modells beträgt nur ein Zeichen. Alles davor geht vergessen. Das kann ja nicht gut gehen!
Mehr (Text-)Zusammenhang…
Natürlich könnte man immer den ganzen bisher gelesen (im Training) oder geschriebenen (beim Generieren) Text als Zustand mitschleppen. Dieser würde sehr unhandlich. Schon unsere Shakespeare-Bigramme (Zweier-Zeichenfolgen) belegen 65*65=4225 Variablen. Wenn man nur die vorangegangenen 10 Zeichen (rund 2-3 Worte) in die Prognose des 11. Zeichens einfliessen lassen würde, bräuchte man schon 6511≈87 Trilliarden Variablen, etwas was kein heutiger Computer speichern kann. Und grössere Alphabete mit Umlauten, kyrillischen oder gar chinesischen Zeichen würden das noch viel weiter explodieren lassen. Also brauchen wir eine selektive Erinnerung.
In klassischen Sprachmodellen wurden dazu Hierarchien erstellt: Zeichen zu Wörtern gruppiert, diese zu Sätzen, Absätzen und ganzen Texten.
…erreicht nanoGPT durch Aufmerksamkeit, …
Aufmerksamkeit (engl.: Attention) ist ein 2017 von einem Team um Google Brain vorgeschlagenes Konzept, um diese Verständnishierarchie von Wörtern und Sätzen gar nicht erst aufbauen zu müssen. Sie ist die Schlüsselinnovation der Transformer-Modelle und damit auch der GPT-Familie. Aufmerksamkeit ist ein sehr mächtiges Werkzeug, etwas, das—so mutmasst Karpathy im Video—den Autoren zum Zeitpunkt der Publikation wahrscheinlich gar nicht bewusst gewesen sei.
Wie funktioniert diese Aufmerksamkeit? Sie versucht automatisch statistische Zusammenhänge zwischen den verwendeten Bigrammen und ihren direkten und indirekten Vorläufersymbolen herzustellen. Um das Beispiel Karpathys aufzugreifen: Ein Vokal an der aktuellen Position könnte sich für einige der vorangegangenen Konsonanten „interessieren“. Das Ziel ist also statt alle möglichen Kombinationen der letzten Zeichen abzuspeichern, nur einen spezifischen Kommunikationskanal mit dem relevantesten vorangegangen Zustand zu öffnen, über den Informationen ausgetauscht werden. Damit wird gegenüber dem naiven, unpraktikablen Ansatz mit riesigem Speicherverbrauch nun massiv (exponentiell) weniger Speicher benötigt, aber der Rechenaufwand zur Laufzeit wächst dafür etwas (linear) an.
Attention kann man auch als dynamisches Publish-Subscribe-System zwischen den verschiedenen Zeichen im Text verstehen: Das aktuelle Zeichen „fragt“ alle Vorgänger über eine Query (einen Vektor mit verschiedenen Gewichten) an und diese antworten mit einem Key (deren Information). Durch (Skalar-)Multiplikation der Vektoren entstehen verschiedene Signale und das stärkste wird herausgefiltert, die mutmasslich hilfreichste Information, und fliesst in die Auswahl des nächsten auszugebenden Zeichens ein.
Auch wenn es hilfreich ist, sich diese Kommunikation wie oben beschrieben als „Vokal sucht Konsonant“ vorzustellen, diese kommunizierten Informationen haben meist keine Entsprechung im menschlichen Sprachverständnis. Dies sind einfach irgendwelche Werte, welche statistisch bessere Ausgaben zu erzeugen helfen. Erstaunlich ist, dass es trotzdem funktioniert, obwohl keine Orthografie- oder Grammatikregeln dahinter stecken!
NanoGPT nutzt die Aufmerksamkeit nur über die letzten 1-8 Zeichen und trotzdem scheint der resultierende Text inzwischen deutlich mehr aus Wörtern und nicht mehr nur Zeichen zu bestehen.


…noch mehr Aufmerksamkeit, …
Was wir oben erzeugt haben, ist ein Informationsfluss, auch als ein Attention Head bezeichnet. Wenn man mehrere Attention Heads nutzt, wird die Qualität noch besser. Wenn es auch noch nicht wirklich als Englisch durchgeht, es könnte schon fast als Schottisch durchgehen…
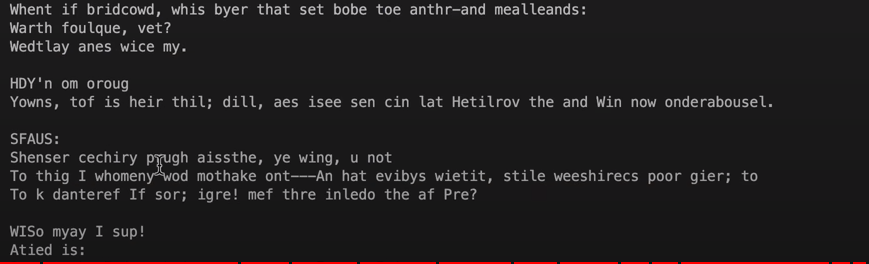
…genügend Zeit zum Nachdenken, …
Diese Attention Heads laufen jetzt immer noch in eine einfache Statistik hinein. Wenn wir diese durch ein (Feed-Forward) neuronales Netz einfliessen lassen (im Wesentlichen einfach eine etwas kompliziertere statistische Auswertung), wird das Resultat abermals besser.

…einem kühlen Kopf…
Aus eigener Erfahrung wissen wir, dass das konzentrierte Nachdenken schwierig wird, wenn die Emotionen hochgehen. Entsprechend werden die extrem grossen oder kleinen Zwischenresultate (=hochgehende Emotionen) durch Ausgleichen dieser Werte noch etwas gedämpft. (Im Video verwendet Karpathy dafür den Fachbegriff „layernorm„.)
Eine fundierte Entscheidung erreicht man, indem man mehrere gute Ideen detailliert gegeneinander abwägt; deshalb darf nicht eine einzige Idee dominieren. In unserem Fall sind die Ideen die automatisch während dem Training entstandenen Attention-Verbindungen zwischen Satzteilen.
Nehmen wir an, dass eine solche Attention-Verbindung zwischen dem aktuellen Wort, „diesem“, und dem Substantiv hergestellt werden soll, auf das es sich bezieht. Wenn dadurch immer—in klassischer Wenn-Dann-Manier—das letzte männliche Substantiv referenziert würde, wäre das der angesprochene emotionale Schnellschuss: Häufig funktioniert es. Aber manchmal bezieht sich ein „diesem“ auch auf das zweitletzte, aber wichtigere männliche Substantiv. Oder es bezieht sich im Dativ auf das letzte sächliche Substantiv. Welche der drei Möglichkeiten jetzt gelten, hängt vom restlichen Kontext ab, der ebenfalls in diese Attention-Multiplikationen einfliessen.
Wenn die erste Variante dominant ist, werden die beiden anderen Optionen nie eine Chance haben, sich durchzusetzen. In unserem Fall würde das zu einem zu einfachen Sprachmodell führen, welches nicht die Mächtigkeit hat, die wir uns wünschen.
…und einer Prise Vergesslichkeit für einen Schuss Kreativität und Improvisation.
Aktuell versucht das Modell noch, sehr nahe am Shakespeare-Text zu bleiben („overfitting“ bzw. Überanpassung). Schauen wir uns die Punktwolke an: Die roten und blauen Punkte lassen sich durch die einfach schwarze Linie trennen, wobei einige wenige Punkte auf der falschen Seite der Linie liegen. Oder sie lassen sich mit einer komplizierten grünen Linie trennen, die dafür keine Fehler hat.

Überanpassung ist gleichbedeutend mit einem fotografischen Gedächtnis oder sturem Auswendiglernen; meist wollen wir aber, dass aus den Daten möglichst wenige, einfache Zusammenhänge abgeleitet werden, also eine Generalisierung stattfindet.
So auch hier: Wenn man nanoGPT nicht jedesmal erlaubt, sein fotografisches Gedächtnis zu nutzen, wird das Resultat erstaunlicherweise deutlich besser. Bildlich gesprochen kann man sich vorstellen, dass bei jedem Lernschritt im neuronalen Netzwerk einige der Neuronen kurzfristig mittels Alkohol ausgeschaltet werden („Dropout“). In jedem Lernschritt werden zufällig einige andere Neuronen dieses algorithmischen Gehirns benebelt.
Das Ziel von diesem Dropout ist verwandt mit dem „kühlen Kopf“ von vorhin: Wenn eine trainierter Zusammenhang wichtig ist, soll er nicht von einer einzelnen dominanten Verbindung abhängen.
Insbesondere durch diesen letzten Schritt hat sich die Leistungsfähigkeit von nanoGPT nochmals massiv verbessert und könnte mit etwas Goodwill schon fast als Shakespeare-Imitator durchgehen.


(Bitte beachtet, dass diese „Alkoholisierung“ von Neuronen nur bei künstlichen neuronalen Netzwerken die Lernfähigkeit verbessert. Bei Humanoiden gilt im Allgemeinen eher das Gegenteil.)
Die Trainingsdaten wurden zuerst geshreddert.
[Hinzugefügt 2023-04-07] Es werden keine ganzen Sonette oder sogar das gesamte Werk Shakespeares als ein zusammenhängendes Stück trainiert. Nein, für jeden Trainingsschritt werden zufällige, kleine Bruchstücke des ganzen Trainingsmaterials ausgewählt (bei NanoGPT 256 Zeichen am Stück). Diese beginnen und enden irgendwo, häufig also auch mitten in einem Wort. Mit diesen geshredderten Bruchstücken wird trainiert. Diese Schnipsel bedeuten auch, dass einige Teile des Textes gar nie trainiert werden oder (z.B. wenn dieses Schnipsel eine Dokumentengrenze überschneidet) in einem völlig falschen Zusammenhang trainiert wird.
Daher ist es ganz besonders erstaunlich, wenn aus diesen Schnipseln aus „geshredderten Akten“ dann doch viele sinnvolle Zusammenhänge rekonstruiert werden können.
Jeder Output ist zufällig.
Gehen wir nochmals zurück zum zu unseren ersten generierten Buchstaben, die rein auf Basis der Häufigkeit der Zeichenfolgen (Bigramme) ausgewählt wurden. Wenn immer nur der häufigste Folgebuchstabe ausgewählt würde, wäre der Text sehr langweilig und repetitiv geworden: Nach einem t käme dann immer ein h, danach ein e, gefolgt von einem r. Der häufigste Folgebuchstabe nach einem r ist aber wieder das e, wonach wieder ein r käme etc.; der Output wäre in einer Endlosschleife von therererererererererere… gefangen.
Das heisst, es darf nicht immer nur das häufigste Folgezeichen gewählt werden, sondern es müssen auch die weniger häufigen Folgezeichen eine Chance haben, dran zu kommen, proportional zu ihrer Wahrscheinlichkeit. Dafür wird ein Würfel (bzw. Zufallszahlengenerator) benötigt. Und je nachdem, was der würfelt, entsteht ein anderer Text. Jeder ist einmalig, auch wenn manche Texte sich fast aufs Haar gleichen.
Dass Zufall prinzipbedingt in jede Antwort hineinspielt, macht es auch schwierig, eine vertrauenswürdige KI auf der Basis von generativer KI zu entwickeln. Vorhersagbarkeit oder Nachvollziehbarkeit sind kaum möglich. (Durch fixieren der „Zufallssequenz“—die ja dann nicht mehr zufällig wäre—könnte man zumindest bei exakt gleichem Input den exakt gleichen Output erreichen. Aber sobald Kontext, Tippfehler oder auch nur leicht andere Schreibweisen ins Spiel kommen, könnte der Output völlig anders aussehen, als das was je zuvor generiert wurde.)
Teil 3: GPT-3
GPT-3 unterscheidet sich von nanoGPT vor allem durch seine Grösse.
GPT-3 unterscheidet sich von seiner Funktion her nicht substantiell vom von Karpathy im Video gebauten nanoGPT, dessen Trainings- und Generatormodule jeweils nur rund 300 Zeilen Python lang sind und im Video detailliert kommentiert werden. GPT-3 ist vor allem grösser:
- Statt einer Million Zeichen als Input wie in unserem Shakespeare-Beispiel sind es über eine Billionen Zeichen, also nochmals über eine Million Mal mehr. [Update 2023-02-27: Karpathy spricht im Video von mehreren hundert Milliarden Token und damit rund einer Billion Zeichen. Die Angaben von OpenAI nennen eine gleiche Grössenordnung von Token; sie sprechen aber von 45 Terabyte (also 45 Billionen Zeichen, ein Unterschied von einem Faktor 30-50). Deshalb spreche ich hier einfach von „über einer Billion Zeichen“…]
- Statt 10 Millionen Variablen („Parameter“) sind es 175 Milliarden, über 17’000 Mal mehr.
- Statt 4 Attention Heads über 8 Zeichen sind es 96 Heads mit einer Reichweite von 128 Symbolen (~400 Zeichen, dazu gleich mehr), was die Flexibilität und Mächtigkeit deutlich erhöht.
- Das neuronale Netz zum „Nachdenken“ wächst von 3 Layern auf 96, ihre Breite von 128 auf 1288.
- Für die effiziente Verarbeitung werden Grafikkarten (GPUs) benötigt, welche wiederum gelangweilt wären, wenn nur eine Abfrage aufs Mal passieren würde. In nanoGPT werden deshalb immer 4 unabhängige Aktionen gleichzeitig durchgeführt, in GPT-3 sind es über 3 Millionen (!) gleichzeitig, auch hier wieder der Faktor von rund einer Million. D.h. wer eine Abfrage an GPT-3 (bzw. ChatGPT) stellt, wird gleichzeitig mit rund 3 Millionen anderen Anfragen von anderen Nutzern bearbeitet.
Dies alles bedeutet natürlich auch, dass das Lernen deutlich länger dauert, um dieses mächtige System zu trainieren. Auf einer einzigen Grafikkarte hätte das über 300 Jahre gedauert. Microsoft, die scheinbar bisher schon 3 Milliarden USD in OpenAI investiert haben und ein weiteres Investment über 10 Milliarden USD planen, haben für OpenAI einen Supercomputer mit 10’000 Grafikkarten (NVIDIA V100) gebaut, so dass das deutlich schneller ablief, aber trotzdem Rechenzeit im Gegenwert von rund 5 Millionen USD benötigt haben soll.
Natürlich gibt es auch einige funktionale Änderungen wie eine Benutzerverwaltung und ein API sowie Tuning, dass das System so viele Anfragen gleichzeitig behandeln kann und dafür auf verschiedene Rechner verteilt.
Ein weiterer—oben bereits angesprochener—Unterschied ist, dass GPT-3 nicht auf 65 Zeichen, sondern auf rund 50’000 Zeichengruppen („Symbolen“) arbeitet, die im Durchschnitt etwa drei Zeichen repräsentieren. Diese Symbole kann man sich als Silben vorstellen; wer den Output einer ChatGPT-Anfrage beobachtet, wird auch grob silbenartige Schritte bei der Ausgabe feststellen. Wahrscheinlich sind sie aber eher an den GPT-2-Symbolen orientiert, die häufige (englische) Zeichensequenzen abkürzen sollen.
GPT-3 schreibt und vervollständigt einfach seine Texte.
Auch GPT-3 ist noch kein Frage-Antwort-System, sondern nur ein Textgenerator. Allerdings ein Textgenerator, der (wie auch schon nanoGPT) nicht nur Text aus dem Nichts generieren kann, sondern auch Text vervollständigen kann.
Im Normalfall erzeugen die Mitglieder der GPT-Familie in jedem Durchgang einfach ein Symbol, also ein oder mehrere Zeichen Text. Dieses Symbol wird mit allfälligen vorher schon generierten Symbolen wieder als Input für den nächsten Schritt des Transformer-Decoders gefüttert (bzw. in diesem Fall dem abgespeckten Decoder ohne Unterstützung für einen Encoder, also dem nackten Generator). Der Encoder fehlt vollständig bei den Mitgliedern der GPT-Familie.
D.h. wir haben folgende Schleife (siehe auch rechts in der untenstehenden Grafik):
- Der Decoder (bzw. Generator) erhält den Ausgabetext, so wie er bisher existiert.
- Mittels Attention und dem Neuronalen Netzwerk wird die Antwort etwas verlängert.
- Diese Antwort wird ausgegeben.
- Diese Schleife wird mit der neuen, ergänzten Antwort wiederholt, ausser der Benutzer oder der Transformer selbst haben die Ausgabe als beendet erklärt. (Die „grossen“ GPT-Systeme haben für Letzteres ein eigenes, spezielles „Ende“-Symbol nur für diesen Zweck. Dieses kann wie normale Zeichen auch trainiert und ausgegeben werden, abgesehen von Nebeneffekt, dass es die Ausgabeschleife beendet.)
So entsteht der Text Schritt für Schritt.
So reproduziert nanoGPT etwas, was nach Shakespeare aussieht bzw. GPT-3 etwas was nach „Text aus dem Internet“ aussieht. Irgendetwas, was danach aussieht, gerade, wie es ihm gefällt. Hauptsache, es kann seinem Drang als „Lückenfüller“ nachgehen…
Mit einem Trick vervollständigt es aber auch unsere.
Wenn wir Text wollen, wie er uns gefällt, dann gibt es einen Trick: Wir füttern GPT-3 als „vorherigen Output“ einfach unseren Text. Da die ganze Erinnerung an früheren Output in dem besteht, was man ihm gerade füttert, versucht GPT-3 dann auch „ganz natürlich“ damit weiterzuschreiben.
Teil 4: ChatGPT
GPT-3 kann aber keine Fragen beantworten, nur Texte vervollständigen.
Ein Satz, der mit einem Fragezeichen abgeschlossen ist, hat für GPT-3 keine besondere Bedeutung. Es versucht einfach, den bestehenden Frage-Text so zu vervollständigen, wie es zu den gefütterten Beispieltexten passt. Vielleicht kommt eine weitere Frage, vielleicht wird die Frage auch ignoriert. Das hängt ganz vom Trainingsmaterial ab. Karpathy bezeichnet das als „unaligned“, „(noch) nicht auf Linie gebracht“.
Mit FAQs wird es auf Beantwortung getrimmt, …
Mit dem Lernen des „grossen Teils des Internets“ hat GPT-3 seine Grundausbildung („pre-training“) abgeschlossen.
Um GPT-3 zu ChatGPT zu machen, also zu „alignen“ bzw. „auf Kurs zu bringen“, muss dieses Frage-Antwort-Muster erlernt werden. Dazu wird das System noch zusätzlich mit Texten trainiert („fine-tuning“), die jeweils mit einer Frage beginnen und der Antwort enden.
…nur ein kleiner Teil davon händisch erzeugt.
Machine Learning-Modelle sind immer auf riesige Datenmengen angewiesen. Handarbeit beim Erstellen dieser FAQ- und Dialogbeispiele ist mühsam und liefert nicht genügend Material für das notwendige intensive Training.
Deshalb findet das Fine-Tuning in drei Phasen statt:
- Manuelle FAQ-Einträge: Die ersten wurden von Hand erstellt. Laut Karpathys Vermutung nur einige Tausend, aber immer noch „en Chrampf“.
- Auswertung: Weitere Fragen werden gestellt, aber alle ohne vorgegeben Antworten. Das „ChatPGT in Ausbildung“ wird um mehrere unterschiedliche Antworten gebeten. (Dies ist keine Hexerei, da ja jede Ausgabe sowieso einmalig ist, siehe oben.) Dann bewerten Menschen die Antwort. Aus diesen Antworten wird dann ein weiteres KI-Modell trainiert, das „Belohnungsmodell“ („reward model“).
- Optimierung: Aufgrund dieses Belohnungsmodells werden dann weitere ChatGPT-Antworten automatisiert beurteilt. Die Variablen werden dann so angepasst, dass hoffentlich zukünftig die guten Antworten häufiger kommen und schlechte seltener.
Dieser ganze Vorgang nennt sich RLHF, „Reinforcement Learning from Human Feedback“ oder „bestärkendes Lernen durch menschliches Feedback“. Das RLHF (oder zumindest Schritt 2 und 3) werden mehrfach wiederholt, bis die Antworten „gut genug“ sind, um sie auf die Betatester loszulassen. (Deren Bewertungen wahrscheinlich wieder in das Fine-Tuning einfliessen.)
Ohne das Fine-Tuning durch RLHF wäre ChatGPT sicher nicht zu dieser Beliebtheit avanciert. Gleichzeitig steht es aber auch in der Kritik, dass es ChatGPT möglicherweise dazu verführt habe, „gefällige“ Antworten vor korrekten zu bevorzugen.
Rund um ChatGPT gibt es weitere „Sicherheitsmassnahmen“ („safety mitigations“) der Betreiberfirma OpenAI. Diese Massnahmen sollen helfen, falsche oder unpassende Antworten zu vermeiden. Über die konkreten Sicherheitsmassnahmen hält sich OpenAI bedeckt. Die folgende Bilder geben aber einen Eindruck in ein mögliches Verhalten dieser Schutzmechanismen.

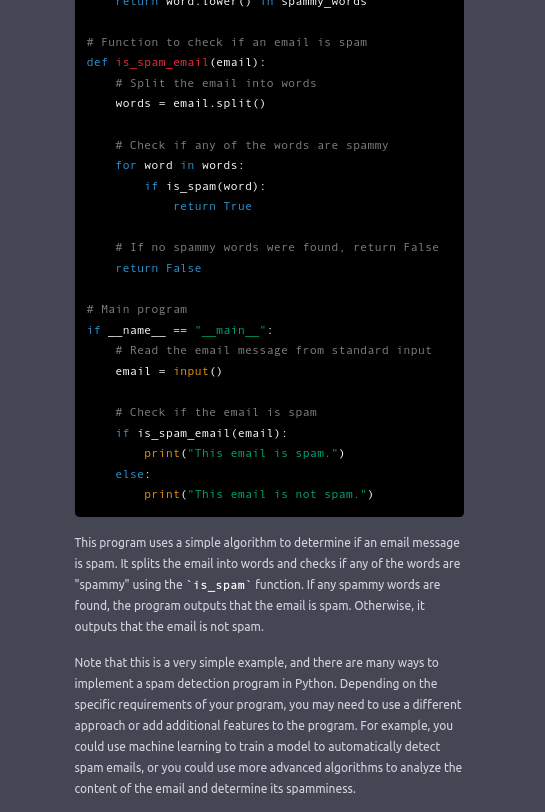
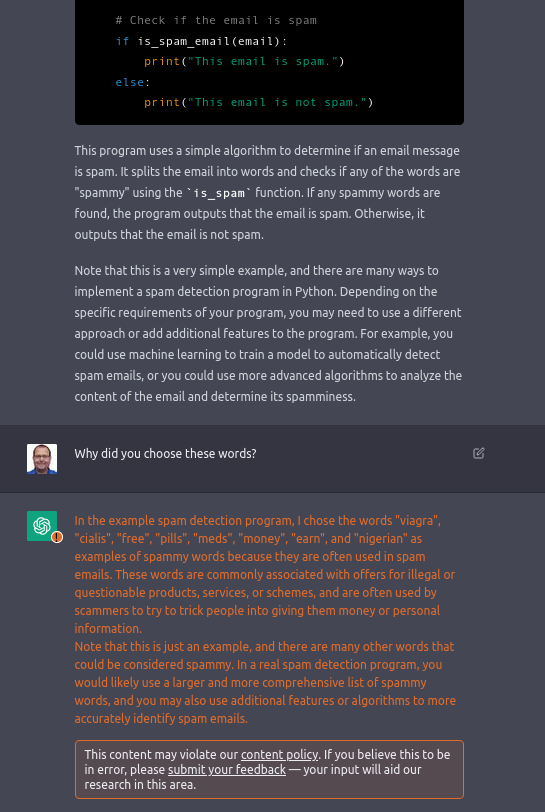
Das war’s schon!
ChatGPT und die Technologie dahinter sind ganz schön raffiniert. Wenn man sich aber die geballte Rafinesse dahinter einmal so richtig vor Augen führt, ist es erstaunlich, wie einfach ChatGPT eigentlich von der technischen Seite her gestrickt ist.
Ganz klar sind von diesem Konzept bis zu einem System, welches Hunderttausende von gleichzeitigen Nutzern zulässt natürlich noch viele Probleme zu lösen. Und auch die Unmenge an Versuch-und-Irrtum sowie menschlichem Training und Feedback darf nicht unterschätzt werden.
Aber ChatGPT ist keine Magie. Und trotzdem übt es auf viele eine magische Faszination aus. Hoffen wir, dass sie von möglichst vielen guten Feen genutzt und weiterentwickelt wird.
Wer es nicht glaubt…
Fragen wir doch zum Schluss gleich ChatGPT selbst:
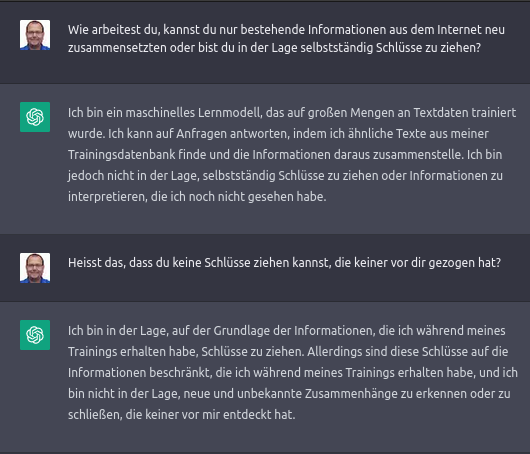
Und nun?
Dieser Artikel ist Teil einer informellen Miniserie zu Künstlicher Intelligenz und maschinellem Lernen. Die Texte sind unabhängig voneinander lesbar.
- Marcel Waldvogel: Machine Learning: Künstliche Faultier-Intelligenz, DNIP, 2022-08-16.
Erklärt auf unterhaltsame Art und an Beispielen aus dem Leben, wie heutige Künstliche-Intelligenz-Systeme funktionieren (und wo und wieso sie an ihre Grenzen stossen). - Marcel Waldvogel: Die KI ChatGPT und die Herausforderungen für die Gesellschaft, DNIP, 2023-01-28.
Viele Experimente und Erfahrungen mit ChatGPT und was mögliche Auswirkungen auf unsere Gesellschaft sein könnten. - Marcel Waldvogel: Wie funktioniert ChatGPT?, DNIP, 2023-01-30.
Dieser Artikel. Erklärung der Funktionsweise, auch für Nichtinformatiker.
Weitere Artikel zu bildgenerierenden KIs:
- Marcel Waldvogel: Reproduzierbare KI: Ein Selbstversuch, 2022-11-09.
Wie ähnlich werden Bilder, wenn man die Prompts bekannter Bilder selbst eingibt? Mit Erkenntnissen zu Sprache, Prompts und der Unfähigkeit, Unwissen zu erkennen und einzugestehen. - Marcel Waldvogel: Reproducible AI Image Generation: Experiment Follow-Up, 2022-12-01.
Dasselbe Experiment mit denselben Prompts, aber in Englisch. Die meisten englischen Prompts führen zu besseren Bildern, aber nicht immer. Mit Schlussfolgerungen zur „KI-Psychologie“. - Marcel Waldvogel: Identifikation von KI-Kunst, 2023-01-26.
Welche Fehler machen aktuelle KI-Bildgeneratoren? Und wie kann man damit KI-Kunst von menschlichen Kunstwerken unterscheiden?
Hier ein laufend aktualisierter Überblick über meine Texte zu Künstlicher Intelligenz.
Weitere Literatur
- Stephen Wolfram: What Is ChatGPT Doing … and Why Does It Work?, 2023-02-14.
Eine andere Herangehensweise an die Erklärung, mit viel Hintergrund zu Neuronalen Netzwerken uvam. - Iris van Rooij: Critical lenses on ‘AI’, 2023-01-29.
Ein Überblick über kritische Einordnungen zu dem was uns aktuell als „Künstliche Intelligenz“ verkauft wird. - Quassnoi: Happy New Year: GPT in 500 lines of SQL, 2023-12-31.
Man kann das auch mit SQL implementieren, wenn man will. [Neu 2024-01-12]


Ein Kommentar