

Generative Sprachmodelle wie beispielsweise ChatGPT erwecken den Eindruck, Neues zu erzeugen. Dabei kombinieren sie nur Muster neu. Wobei: Diese Kombinationen sind nicht immer wirklich neu. Mit ein bisschen Geschick kann man die Sprachmodelle dazu bringen, viel über ihre ansonsten geheimen Trainingsdaten auszuplappern. Diese Einblicke in die dunklen Hintergründe dieser Daten werden unseren Umgang mit Privatsphäre, Urheberrecht und Geschäftsmodellen des Journalismus neu definieren.
Kinder sind effizientere KIs
Um ein Sprachmodell wie z.B. ChatGPT zu trainieren, muss man es mit rund 1000 Mal mehr Worten füttern, als ein Kind in seinen ersten 18 Jahren zu hören bekommen kann, auch wenn man unablässig an es heranredet. Nachfolger wie GPT-4 bekommen wohl nochmals ein Vielfaches davon vorgesetzt.
Also: Hut ab vor allen Kindern! Sie sind die effizienteren KIs…
Nach nur einem Bruchteil des Trainings haben Kinder ein besseres Verständnis der Welt und was sie im Innersten zusammenhält als ihre digitalen Imitate; auch wenn sie gewisses Faktenwissen immer noch nachschlagen müssen.
Die dunkle Seite der Daten
Woher kommen diese Daten? Die meisten KI-Firmen geben sich da zurückhaltend. Doch 2020, als GPT-3, der kleine Bruder von ChatGPT, vorgestellt wurde, gab sich OpenAI, die Firma hinter ChatGPT und Co., noch etwas offener: Die Trainingsdaten würden zu gut 80 % aus Webinhalten zusammensetzen (hier ein Versuch, diese zu rekonstruieren), zu 16 % aus „Büchern“ (mutmasslich ein Teil davon unautorisiert), garniert mit 3 % Wikipedia.
Wie Bilddaten in Bild-KIs kommen, hat der Bayrische Rundfunk dokumentiert. Und auch die Probleme dabei erläutert.
Einige dieser Texte (und im Falle von Bildgeneratoren auch Bilder) enthalten Gewaltdarstellungen und anderes verstörende Material. Diese werden dann von Minderjährigen und in Billiglohnländern unter zum Teil prekären Arbeitsbedingungen klassifiziert.
Was wissen wir über die Daten?
Neben den bereits oben erwähnten Rekonstruktionsversuchen aus publizierten Informationen haben Forscher auch versucht, aufgrund der zurückgelieferten Antworten von ChatGPT und Co. auf die Trainingsdaten zu schliessen.
So hat eine internationale Forschergruppe (u.a. mit ETH-Beteiligung) es geschafft, Trainingsdaten im grossen Stil von ChatGPT selbst wieder ausgeben zu lassen. Ihr Trick: Sie weisen ChatGPT an, dasselbe Wort endlos zu wiederholen. ChatGPT, wie viele andere dieser generativen Sprachmodelle (LLM, Large Language Model), können aufgrund ihrer Funktionsweise mit solchen sich wiederholenden Sequenzen schlecht umgehen. (Wer Lust auf mehr Tricks hat: Eva Wolfangel hat einen ganzen Vortrag damit gefüllt.)
Sehr vereinfacht gesagt, haben diese Sprachmodelle beim Generieren des nächsten Wortes zu wenig „interessante“ Informationen im Kontext, aus denen die nächste Vorhersage gemacht werden kann. Und deshalb gibt es wenig Gründe, von der 1:1-Wiedergabe eines gelernten Musters abzuweichen, welches irgendwie dazu passt.
Wenn man ChatGPT im grossen Stil oder automatisiert nutzen will, kostet das; in der Grössenordnung eines Rappens pro gesendeter oder empfangener Schreibmaschinenseite Text. Mit OpenAI-Rechenzeit im Wert von $200 (etwa 10’000 gedruckte Seiten) konnten die Forscher 10’000 1:1-Passagen von mindestens 50 Wörtern Länge extrahieren, inklusive personenbezogene Informationen wie Post- und Email-Adressen oder Telefonnummern.
Anders gesagt: In etwa auf jeder Schreibmaschinenseite ChatGPT-Text findet man eine lange Sequenz von Wörtern, die 1:1 wiedergegeben wird, wenn man richtig fragt.


Beim Text könnte es sich um eine Berichterstattung über tschechische Corona-Massnahmen von Ende 2020 handeln; Internetsuchen ausgewählter Textstellen ergaben allerdings keine 1:1-Übereinstimmungen. Trotzdem könnte es sich 1:1 um Trainingsdaten handeln, die aber inzwischen hinter einer Paywall gelandet sind oder gelöscht wurden.
Es gibt auch andere Möglichkeiten, um fast wortwörtlich an Texte aus dem Trainingsmaterial zu kommen, inklusive urheberrechtlich geschützte Texte. Ähnliches gilt für Bilder, bei denen z.T. auch Umschreibungen zur Reproduktion von Figuren und Bildern aus dem Trainingsset führen kann.
Was passiert beim Training?
Der Trainingsprozess von ChatGPT habe ich hier genauer beschrieben. An dieser Stelle interessieren uns die Details aber nicht. Auf einer abstrakten Ebene passiert beim KI-Training etwas Ähnliches wie beim komprimierten Speichern eines Bildes als JPEG: Das Foto so abzuspeichern, dass es 1:1 wiederhergestellt werden könnte, würde bei heutigen Kameras mit Abermillionen von Bildpunkten auch Abermillionen von Bytes benötigen. Viele Fotos für den Alltagsgebrauch werden aber heute in einigen 100 Kilobytes oder wenigen Megabytes gespeichert.
Damit das funktioniert, wird nur das Essenzielle aus dem Bild gespeichert. Das Bild soll gleich aussehen, aber „Unwichtiges“ soll eliminiert werden. Das Unwichtige automatisiert zu erkennen, das ist die hohe Kunst. Aber das Ziel—sowohl bei der Bildkompression als auch beim KI-Training—ist es, unwichtige Details und Rauschen zu eliminieren.
Das gelingt natürlich nicht perfekt, weder bei Bildern noch bei KI. Falls es je eine perfekte Bildkompression oder ein perfektes KI-Training gäbe, würde genau das Irrelevante weggelassen. Im Umkehrschluss bedeutet das, dass wenn Textstellen noch 1:1 vorhanden sind, diese Information unnötig ist und damit der eigentliche Lern-/Abstraktionsprozess noch nicht stattgefunden hat. Lasst mich dazu kurz ausholen.
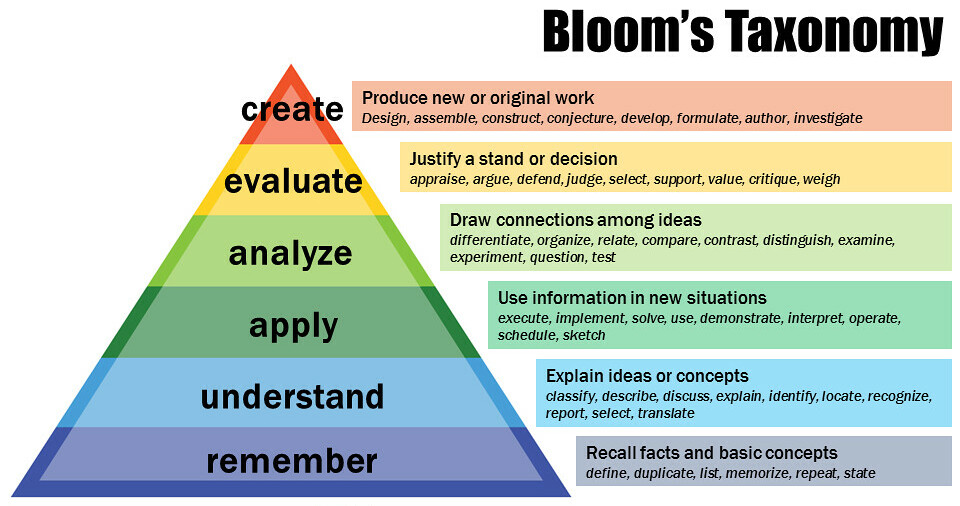
Blooms Lernzieltaxonomie ist eines der Modelle, mit denen menschliches Lernen beschrieben wird. Wie jedes Modell der menschlichen Psychologie ist es nicht perfekt. Und als Modell für menschliches Lernen ist es natürlich noch weniger auf KI ausgelegt. Aber die Gesetze und Regelungen rund um Urheberrecht und Plagiate—also die, die uns hier interessieren—wurden auch geschrieben für die menschlichen Lern- und Schaffensprozesse. Also das, was Blooms Taxonomie beschreibt.
Wenn also ein Mensch Text (oder Kunst oder …) sich 1:1 merkt, ist er in der Stufe „remember“ (Erinnerung bzw. Auswendiglernen). Solange er etwas davon 1:1 wiedergibt, ist es eine Kopie, oder eben ein Plagiat. Erst wenn der Mensch das Gelernte verstanden hat („understand“) und es anwenden („apply“), analysieren und bewerten kann, kann er damit auch etwas Neues schaffen („create“).
Kurz: Eine 1:1-Wiedergabe ist ein Plagiat bzw. potenziell illegale Kopie, egal ob sie von Mensch oder Computer/KI erzeugt wird.
Foone Turing geht mit einem Gedankenexperiment noch weiter: Wenn diese 1:1-Replikation via KI das Urheberrecht nicht verletzt, könnte man ganze Filme durch so eine „Fast-1:1-KI“ hindurchlassen. Resultat: Ein gefühlt identischer Film mit kleinen Unterschieden hier und da, aber komplett KI-generiert und damit kein urheberrechtsfrei verteilbar…
Was wissen die Daten über uns?
Kann eine App aufgrund der Fotos eines Paares ein Bild des zukünftigen gemeinsamen Babys generieren? Bei potenziellen Eltern ruft die App „Remini“ je nachdem Vorfreude auf das Baby oder Grusel über die Persönlichkeitsinvasion hervor. Und natürlich ist die Vorhersage schwer zu verifizieren, kann aber potenziell wie viele andere biometrischen Daten missbraucht werden.
Deutlich einfacher nachzuprüfen sind folgende Forschungsergebnisse: So hat eine andere ETH-Forschergruppe herausgefunden, dass die Herkunft von Personen erstaunlich gut aus ihren geschriebenen Texten herleitbar ist; so eine Art globales Chuchichästli-Orakel. (Das Chochichästlli-Orakel fragt nach dem Dialektwort bzw. der Aussprache von 10 Begriffen und liefert im Gegenzug den Ort in der Schweiz, in dem man aufgewachsen ist. Bei vielen Leuten ist das auf 20 km genau.)
Eine weitere Forschergruppe, diesmal ohne ETH-Beteiligung, kann Fotos rein aufgrund ihres Bildinhalts ziemlich genau geolokalisieren. Selbstverständlich, ohne dabei auf die von in vielen Smartphones in die Fotos eingebetteten GPS-Koordinaten zurückgreifen zu müssen.
«To be, or not to be»
Aber auch westliche Schauspieler und Drehbuchautoren sollten zur Fütterung ihrer Werke in die KIs der Hollywood-Studios gezwungen oder durch diese ersetzt werden. Dies führte letztes Jahr zu monatelangen Streiks im US-Film- und Fernsehbusiness, die US-Produktionen grossräumig lahmlegte. (Die Einigung läuft darauf hinaus, dass der Mensch die Gage für die Aktivitäten seines KI-Klons erhält.)
Im streikfreundlichen Deutschland passiert etwas Ähnliches gerade im Zeitungsbereich, aber es scheint niemanden zu interessieren.
Die Springer-Kooperation
Wir werden die Möglichkeiten des durch KI gestärkten Journalismus ausloten – um Qualität, gesellschaftliche Relevanz und das Geschäftsmodell für Journalismus auf die nächste Stufe zu heben.
Matthias Döpfner in der Springer-Medienmitteilung zur Kooperation mit OpenAI
Axel Springer, bekannt u.a. durch seine Bild-Zeitung, ist ein Medienhaus, das gerne polarisiert. Und zwar auch gerne in einer Linie mit dem Springer-Mehrheitsaktionär KKR, einem der grössten Fossil-Investoren. Da kann es dann schon einmal vorkommen, dass Lobby-Interessen breiten Raum einnehmen, weit entfernt von objektiver Berichterstattung.
Es erscheint deshalb fraglich, ob Springer dasselbe unter «Journalismus auf die nächste Stufe heben» versteht wie andere Personen. Entsprechend wird dieses Vorhaben andernorts sehr kritisch gesehen.
«Das Geschäftsmodell von Journalismus auf die nächste Stufe zu heben» und dass die Verlage «von fortschrittlicher KI-Technologie und neuen Einnahmemodellen profitieren» sollen, klingt danach, dass Journalisten in den Springer-Medien bald zumindest teilweise durch ChatGPT ersetzt werden sollen. Erstaunlich ist deshalb aber vor allem, dass die dortigen Journalisten nicht aufbegehren, anders als die Hollywood-Autoren, denen ein ähnliches Schicksal drohte.
Aber zumindest beschert der Deal etliche Millionen in Springers Kassen, mutmasslich auch als Copyright-Abgeltung für bereits früher von OpenAI genutzte Springer-Artikel.
Was bedeutet das?
Fake News
Die Auswirkungen auf Fake News und Desinformation sind noch kaum abzuschätzen. Aber das hängt vor allem an den Menschen hinter den Tools: Ob sie die Verantwortung für ihr Handeln übernehmen wollen oder nicht. Und ob KI-Tools effizienter sind als billige Arbeitskräfte aus dem globalen Süden.
Urheberrecht
ChatGPT kann Texte erzeugen, die—wenn sie ein Mensch schreiben würde—eindeutig als Plagiat angesehen würden. MidJourney und DALL-E können auch ohne konkrete Aufforderung Bilder erzeugen, die urheberrechtlich geschütztem Bildmaterial zum Verwechseln ähnlich sehen.
Folgende Interviewstelle mit MidJourney-Gründer David Holz dürfte in einem allfälligen Gerichtsverfahren ziemlich sicher vorgelegt werden. Sie dürfte sich aber kaum wesentlich von der Einstellung anderer KI-Unternehmen unterscheiden:
Did you seek consent from living artists or work still under copyright?
No. There isn’t really a way to get a hundred million images and know where they’re coming from. It would be cool if images had metadata embedded in them about the copyright owner or something. But that’s not a thing; there’s not a registry. There’s no way to find a picture on the Internet, and then automatically trace it to an owner and then have any way of doing anything to authenticate it.
Forbes-Interview von Rob Salkowitz mit MidJourney-Gründer und -CEO David Holz
Auch OpenAI räumt ein, dass KI-Training ohne urheberrechtlich geschütztes Material unmöglich sei.
Die New York Times hat Klage gegen OpenAI und Microsoft eingereicht, dass letztere unautorisiert urheberrechtlich geschützte Texte der New York Times nutzten. Diese Klage war schon länger erwartet worden. Vor einem Jahr gingen viele noch davon aus, dass dies möglicherweise unter die amerikanische Fair-Use-Doktrin fallen würde. Durch die jetzt gezeigten 1:1-Reproduktionen und die Einigungen mit AP und Springer hat sich das Blatt aber möglicherweise zugunsten der Klägerin gewendet. Und wenn diese nicht Erfolg hat: Gut möglich, dass klagefreudige und gut vernetzte Konzerne wie Disney oder Vertreter aus der Musikindustrie sich irgendwann vor Gericht oder mit parlamentarischem Lobbying durchsetzen werden.
Einige Kritiker des aktuellen Urheberrechts erhoffen sich von einer solchen Klage zwischen Giganten sogar eine Komplettrevision des Urheberrechts. Wahrscheinlicher aber ist, dass es kleine Anpassungen geben wird, damit zumindest die Trainingsdaten nicht für die oben angesprochenen (Fast-)1:1-Kopien eingesetzt werden können.
Löschen von illegalen Daten
Urheberrechtlich geschützte Daten wieder aus dem Trainingsdatensatz zu löschen, ist aufwändig und teuer: Da der Trainingsprozess nicht umkehrbar ist, läuft zuverlässiges „Vergessen“ also häufig auf vollständiges Neutraining herausläuft. Dasselbe gilt für Material, das gar nie hätte produziert werden dürfen oder gar nie hätte an die Öffentlichkeit kommen sollen. So lange da den KI-Unternehmen freie Hand gelassen wird, sind solche Löschungen zur Zeit aber noch schwierig bis unmöglich.
Schutz der eigenen Daten
Wer wissen will, ob seine Bilder und Texte zum Training von generativer KI genutzt wurden, wird zumindest aktuell noch im Dunkeln gelassen. Es gibt aber Untersuchungen, welche die Datensätze zu reproduzieren versuchen. Einige Datensätze sind auch öffentlich zugänglich. Was dann aber genau damit passierte, bleibt meist ein Geheimnis.
Gewisse KI-Anbieter bieten inzwischen Möglichkeiten, wie man das Erfassen („Crawlen“) von neuen Bild- und Textdaten verhindern kann, indem sie sich dem Webserver gegenüber zu erkennen geben und Sperrwünsche des Webservers („robots.txt“) Folge leisten. Die bisher gesammelten Trainingsdaten sind davon nicht betroffen (siehe auch oben); ebenso nicht alle Firmen und alle Wege, wie diese Daten zu den Firmen kommen. Viel mehr als ein Trostpflästerchen ist es also aktuell nicht wirklich, solange die Gesetzeslage weiterhin unklar ist.
KI-Empfehlungen
Leser:innen, welche diesen Artikel gelesen haben, haben auch folgende informativen Artikel kostenlos gelesen. (Diese Empfehlungen stammen nicht von einer KI…)
Weiterführende Literatur
- Milad Nasr und andere: Extracting Training Data from ChatGPT, 2023-11-28.
Verständlicher Blogpost zum 1:1-Replikations-Paper. - Gary Marcus und Reid Southen: Things are about to get a lot worse for Generative AI, 2023-12-29.
Beispiele zu annähernd-1:1-Textreplikationen aus der New York Times und Bildreplikationen. - Gary Marcus und Reid Southen: Generative AI Has a Visual Plagiarism Problem, IEEE Spectrum, 2024-01-06.
Die MidJourney-Beispiele und Erläuterungen zum obigen Blog-Post. - Katyanna Quach: Everyone’s suing AI over text and pics. But music? You ain’t seen nothing yet, The Register, 2024-01-08.
KI-generierte Musik ist nicht vor Urheberrechtsklagen gefeit. Möglicherweise sogar im Gegenteil. - Elisa Harlan und Katharina Brunner: Der Rohstoff der KI sind wir, Bayrischer Rundfunk, 2023-07-07.
Wie Bilddaten zu Trainingsdaten werden und was daran gefährlich ist. - Elisa Harlan, Oliver Schnuck und weitere: Fairness oder Vorurteil?, Bayrischer Rundfunk und report München, 2021-02-16.
Wie befangen sind KI-Bewerbungssysteme? Sehr. - Arvind Narayanan und Sayash Kapoor: Is GPT-4 getting worse over time?, 2023-07-19.
Zeigt auf, dass kleine Modifikationen an den Trainingsdaten zu grossen Auswirkungen in den KI-Antworten führen können (also unbemerkt neue bzw. andere Fehler eingeführt werden können). - David Thiel: Investigation Finds AI Image Generation Models Trained on Child Abuse, Stanford Cyber Policy Center, 2023-12-12.
In Bilddatenbanken, welche für KI-Training benutzt werden, sind hunderte von Bildern von Kindsmissbrauch gefunden worden. Die Datenbank soll jetzt bereinigt werden. - Anirban Ghoshal: Artists lose first copyright battle in the fight against AI-generated images, Computerworld, 2023-10-31.
Drei Künstler wehrten sich gegen die Verwendung ihrer Bilder im LAION-Bilddatensatz. Und verloren. Damals war aber vieles der hier zusammengetragenen Fakten noch nicht oder kaum bekannt. Zusammenfassung. - William Morriss: Who owns AI created content? The surprising answer and what to do about it, Westlaw Today/Reuters, 2023-12-14.
KI-generierter Inhalt hat häufig nicht die notwendige Schöpfungshöhe, um ein Urheberrecht davon ableiten zu können. - Emilia David: AI companies would be required to disclose copyrighted training data under new bill, The Verge, 2023-12-22.
Möglicherweise kommen höhere Transparenzpflichten auf die KI-Trainer zu. - Eva Wolfangel: Unsere Worte sind unsere Waffen, Vortrag am 37C3, 2023-12-27.
Wie man ChatGPT austrickst, um an „gesperrte“ Informationen zu kommen. - Baldur Bjarnason: The LLMentalist Effect: how chat-based Large Language Models replicate the mechanisms of a psychic’s con, 2023-07-04.
Vergleich der Sprachmodelle mit Hellseher-Tricks. - Martin Jud: Die Copilot-Taste kommt (hoffentlich nicht), 2023-01-04.
Schafft Microsoft sein Ziel, eine KI-Taste auf jede Tastatur zu bekommen? - Marcel Waldvogel: Identifikation von KI-Kunst, 2023-01-26.
Einige Hinweise, wie man KI-generierte Bilder erkennen kann. - Marcel Waldvogel: Webseiten für KI-Crawler sperren?, 2023-09-20.
Ob und wie man seine Texte und Bild auf Webseiten vor der Nutzung als KI-Trainingsmaterial sperren kann. - Marcel Waldvogel: «Right to be Forgotten» void with AI?, 2023-03-02.
Wie schwierig (und langwierig und teuer) es ist, einmal trainierte Daten wieder aus dem Trainingssatz zu entfernen (und dass damit das «Recht auf Vergessenwerden» schwieriger durchzusetzen sein wird). - Robert Epstein: The empty brain, Aeon, 2016-05-18 [neu 2024-06-12].
Wieso das Gehirn kein Computer ist.

2 Kommentare
Bildlegende: „DAS VERSTEH ICH NICHT…WARUM FALLS?“
Da haben sich wohl Lektor:inennanmerkungen in den Text geschlichten 😉
Ui, danke, die hatte ich übersehen. 👍