
Moderne Chatbots wie ChatGPT, Gemini und Claude sind alles sogenannte grosse Sprachmodelle (Large Language Model, LLM). Über ihre Funktionsweise — und damit auch über Fehlerquellen, Einsatzmöglichkeiten und Regulierungsbedarf — herrscht auch nach fast zwei Jahren noch sehr viel Unklarheit. Hier eine Einführung in diese Zusammenhänge.
Sprachmodelle vor 2017
Vor 2017 hat man versucht, Texte in KIs aufgrund von Grammatik zu analysieren und generieren: Also, Subjekt, Verb und Objekt erkennen, in Haupt- und Nebensätze aufteilen uvam. Das war mit viel Handarbeit verbunden und die Fortschritte entsprechend langsam. Der Durchbruch kam mit dem Wechsel von vollständig auf Maschinellem Lernen aufbauenden, sogenannten «grossen Sprachmodellen» (LLM, Large Language Model). Dieser Durchbruch basiert auf einem Forschungsresultat des Google-Brain-Teams, das dieses 2017 unter dem Titel «Attention is all you need» publizierte.
Mehr wissen: Mehr über Machine Learning, den Vorläufer von Large Language Models und anderer Generativer KI („Generative AI“, „GenAI“).
Moderne GPT-Sprachmodelle
Dieses Paper präsentierte die Transformer-Technologie, das „T“ in „GPT“, welche in den Folgejahren begann, die anderen Ansätze grösstenteils abzulösen.
Seither werden keine expliziten Satzstrukturen mehr analysiert, sondern alles wird nur noch mit Statistiken und Mustern auf allen möglichen Ebenen gemacht. Aus riesigen Textmengen, aus dem ganzen Internet zusammengekratzt, werden Textpassagen ausgeschnitten und daraus Muster extrahiert. Anstelle der fixen, prä-2017-Muster wie Wörter, Phrasen, Sätze und Satzteile, Argumentationsketten, mathematische Beweise oder Essay-Strukturen, gibt es jetzt nur noch statistische Zusammenhänge zwischen Zeichen bzw. kurzen Zeichenfolgen («Token»).
In heutigen Sprachmodellen sind also Abermillionen Muster latent codiert. Wie beim Maschinellen Lernen üblich, gibt es da auch keine Unterscheidungen zwischen statistischen Mustern, welche kurzfristige Zusammenhänge wie Wörter oder Redewendungen abbilden und denjenigen, welche den grösseren Kontext von Beweisstrukturen oder ganzen Artikeln repräsentieren.
Für jedes neue auszugebende Token einer Antwort werden diejenigen Muster probabilistisch (=nach Zufallsprinzip) zusammengefügt, die gerade zu passen scheinen.

Mehr wissen: Wer tiefer in die Erstellung und Anwendung dieser Muster eintauchen will: «Wie funktioniert eigentlich ChatGPT?» ist das deutschsprachige Standardwerk für alle, die ChatGPT genauer verstehen wollen, ohne gleich ein Informatik-KI-Studium absolvieren zu müssen. Die meisten anderen Sprachmodelle (Gemini, Claude, LLaMA, …) funktionieren übrigens nach dem gleichen Prinzip. Übrigens: Auch die Funktionsweise vieler KI-Bildgeneratoren ist nicht allzu weit entfernt davon!
Wie entstehen Fehler?
Beim Erzeugen von „Antworten“ auf unsere Eingaben werden also unzählige statistische Muster zusammengefügt. Typischerweise passen die meisten davon. Aber das eine oder andere Muster kann auch ausgewählt worden sein, obwohl es nicht wirklich passt.
So wurde im unten stehenden Beispiel auf die Frage, «Wenn eine Frau für ein Baby 9 Monate braucht, wie viele Babies können dann 9 Frauen in einem Monat produzieren?» das Muster „Dreisatz lösen“ angewendet, welches hier aber definitiv nicht passt.
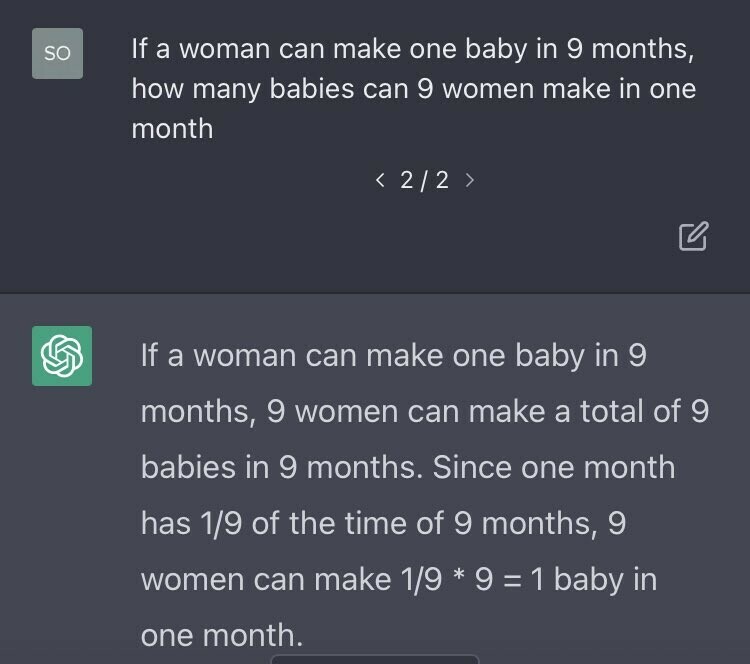
Das hatte einen kleineren Shitstorm ausgelöst und war OpenAI, der Firma hinter ChatGPT, offensichtlich peinlich. Und so haben sie versucht, das Problem so rasch als möglich aus der Welt zu schaffen. Denn: Von sich aus lernt die KI nicht aus ihren Fehlern. Man muss ihr die Fehler bewusst und gezielt austreiben.
Insanity is doing the same thing over and over again and expecting different results.
(«Wahnsinn ist, wenn man das Gleiche endlos wiederholt, aber erwartet, dass sich das Ergebnis ändert.»)
Nicht Albert Einstein
Was hinter den Kulissen genau geschah ist unklar; folgende Punkte dürften aber dazu gehört haben:
- OpenAI suchte möglichst viele Beispieltexte, die mit Berechnungen rund um Schwangerschaften zu tun hatten.
- Dazu suchten sie wohl das Internet ab, aber auch den Chatverlauf ihrer Nutzer:innen. In möglichst vielen Sprachen.
- Damit hatten sie genügend Ideen, wie man das Konzept beschreiben kann. Und wie es schief laufen kann.
- Auf dieser Basis haben sie unzählige Varianten der Frage/Antwort-Paare erzeugt, mit denen ChatGPT nachtrainiert wurde.
- Die Teil der Fragen zu Schwangerschaftsberechnungen und verwandten Themen wurden nachher auch als Testdaten genutzt, um sicherzustellen, dass die Antworten darauf jetzt akzeptabel waren.
Das ist eines von vielen Szenarien, in denen die Benutzeranfragen genutzt werden und potenziell in das Training einfliessen können. Ein Teil davon wird sicher auch automatisiert durchgeführt. Denn: Löschen von Fehlinformationen im Sprachmodell ist sehr aufwändig und vollständiges Eliminieren extrem teuer.
Korrigieren ist schwierig
Die „Schwangerschaftsfehler“ scheinen nach der ersten Umerziehung von ChatGPT nicht mehr aufgetaucht zu sein. Anders sieht es aber bei Gemini und der folgenden Pizza-Leim-Geschichte aus:
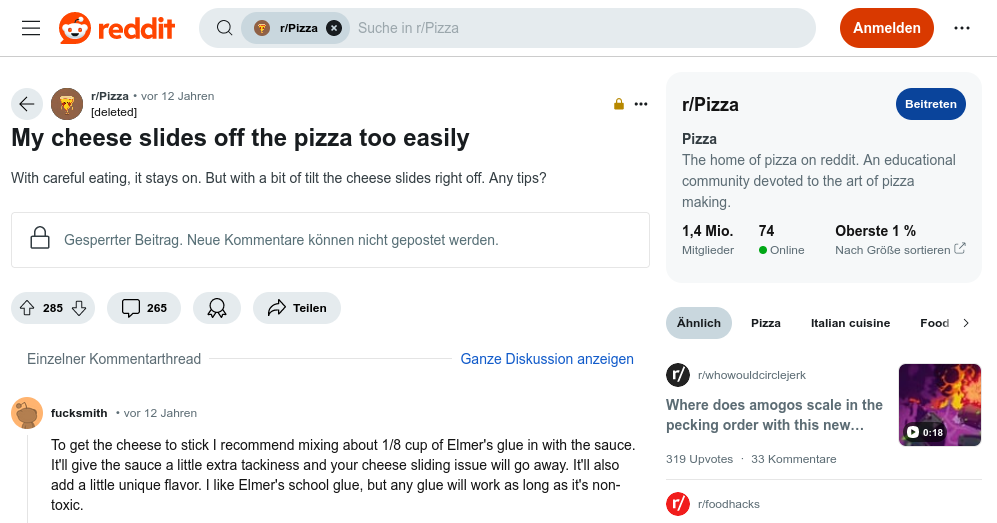
- Vor 12 Jahren hat jemand auf die humoristische Anfrage, was er tun könne, wenn ihm immer der Belag von der Pizza rutsche, satirisch geantwortet, dass er mit Leim gute Erfahrungen gemacht habe.
- Dieser Antwort wurde beim Training für Googles KI „Gemini“ aufgenommen. Ironie und Satire sind von KI schwer zu erkennen. Entsprechend wurde der Leimtipp wie ein Fakt behandelt.
- Im Mai diesen Jahres fand jemand heraus, dass Gemini auf die Frage, wie man sich gegen zu rutschigen Pizzabelag wehren könne, fast wortwörtlich den untenstehenden Post reproduzierte.
- Google versprach Besserung und liefert inzwischen auf die ursprüngliche Frage keine Infos mehr, denen man auf den Leim kriechen kann.
- Auf die leicht andere Frage, wieviel Leim man aber verwenden solle, um das Problem zu lösen, kommt weiterhin die Mengenangabe aus dem Post.
Dies zeigt nicht nur, wie schwierig es ist, einmal gelernte Informationen wieder aus dem „Datenspeicher“ eines KI-Sprachmodells zu löschen. Es zeigt auch, wie wertvoll es für die KI-Firmen ist, verwandte Fragen zu identifizeren. Und genau darin liegt eine der Hoffnungen bei der Wiederverwendung von unseren Chat-Prompts.
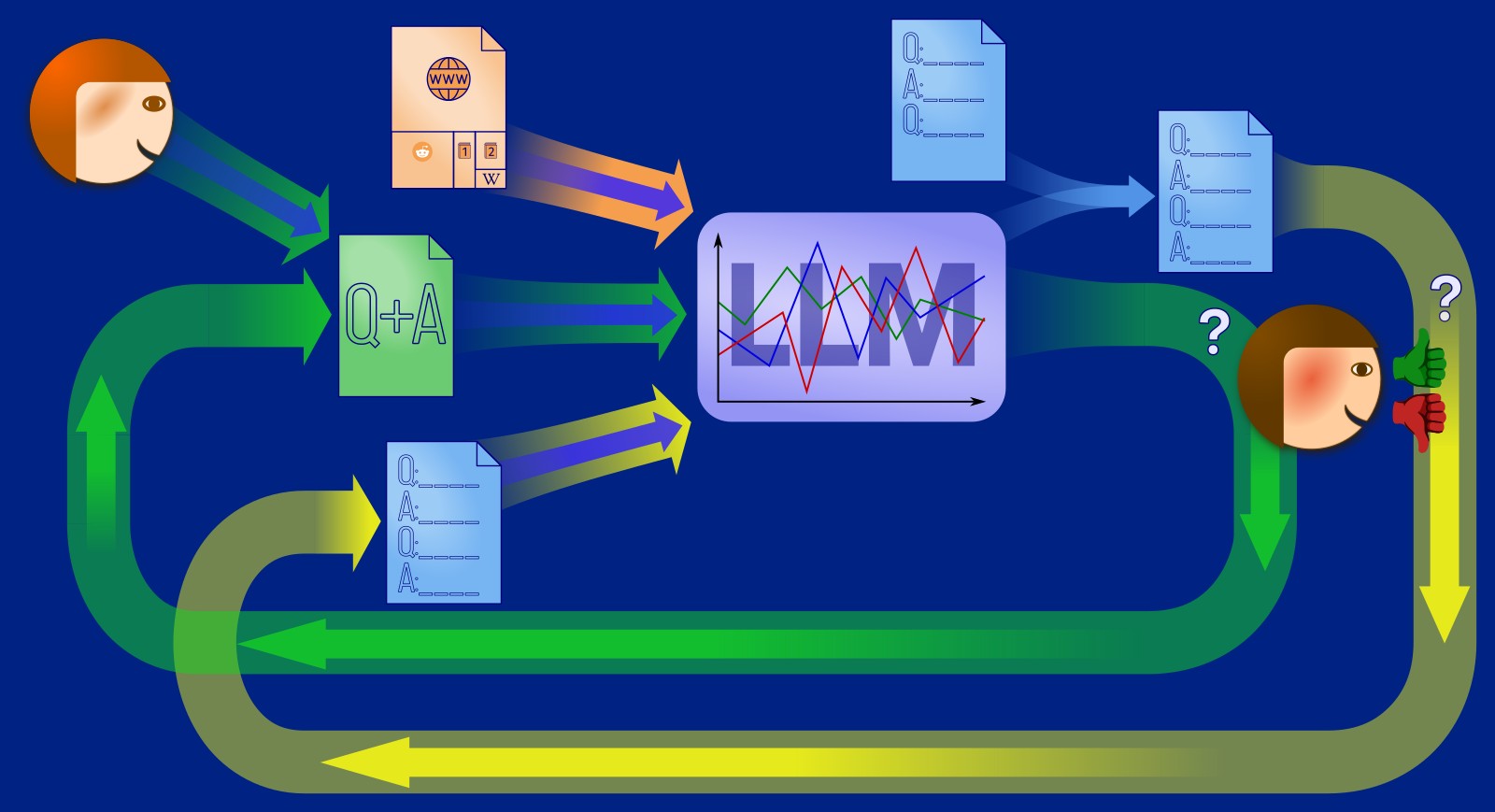
Datenflüsse zur Verbesserung
Was sind denn aber die Datenflüsse, die beim Training und der Verbesserung von grossen Sprachmodellen überhaupt auftreten?
Der normale Chat

Für uns Normalnutzer:innen vor allem die Beantwortung unserer Fragen interessant: Aus unserer aktuelle Frage („Prompt“, das „Q-A-Q“-Dokument oben in der Mitte) wird zusammen mit den Informationen aus dem KI-Sprachmodell (Large Language Model, die „LLM“-Box mit den symbolischen Statistik-Kurven links) eine Antwort berechnet („Q-A-Q-A“-Box rechts, unser Chat, nun aber mit einer Antwort).
Mehr wissen: Den Trainingsprozess- und Antwortprozess bei ChatGPT und wieso die Beantwortung auf Zufallszahlen beruht habe ich hier schon detaillierter beschrieben.
Wie aber kommt das LLM zu seinen Informationen?
Lernschritt 1: Sprache und Fakten
Aus dem Internet, sozialen Medien sowie anderen Kanälen werden möglichst viele Texte extrahiert („crawled“), wogegen man sich nur schwer wehren kann. Diese werden dann in kurze Bruchstücke geschreddert und aus diesen werden automatisiert Muster extrahiert. Dies ist der Trainingsprozess. Um zu sehen, ob der Trainingsprozess erfolgreich ist, wird ein Teil der ursprünglichen Daten nicht für den Trainingsprozess genutzt, sondern nur, um zu sehen, wie das System darauf reagiert („Testdaten“).
Das Sprachmodell („LLM“) hat nun in verschiedenen Sprachen Muster für Wörter, Sätze, Absätzen und Artikelstrukturen extrahiert und in seiner Statistik („Parametern“) gespeichert. Darunter sind auch viele Fakten, aber auch Vorurteile, Falschaussagen oder schlichtweg Ironie (welche oft nicht als solche verstanden wird).
Mehr wissen: Zur Datenherkunft, dem grundlegenden KI-Trainingsprozess im Allgemeinen sowie dem Trainingsprozess bei ChatGPT im Speziellen finden sich hier bei DNIP schon andere Artikel. Ein konkretes Beispiel mit deutschen Trainings- und Testdaten findet sich hier. Die Schwierigkeiten, seine Webseite vor der Nutzung durch KI zu schützen oder Daten wieder aus KI-Systemen gelöscht zu bekommen, habe ich auf Englisch beschrieben.
Lernschritt 2: Fragen beantworten

Nach Lernschritt 1 können LLMs wie ChatGPT erst Sätze etc. vervollständigen. Damit sie auch Fragen beantworten oder sonstige Problemstellungen lösen (Texte kürzen, Listen von Argumenten liefern, …) können, müssen sie die dazu nötigen Muster erst trainiert bekommen.
Dazu erzeugt zuerst ein Mensch — im Auftrag der KI-Firma — links oben Frage-Antwort-Pärchen (das grüne „Q+A“-Dokument link in der obigen Grafik) oder sonstige Anfragen-Lösungen-Pärchen. Auch hier wird wieder ein kleiner Teil als Testdaten für später beiseite gelegt. Mit den Rest werden jetzt diese Dialogmuster eintrainiert. Wenn die entsprechenden Muster jetzt auch im LLM-Statistikspeicher abgelegt sind, dann kann der Chatbot die Anfragen mit Antworten vervollständigen.

Sprachmodelle brauchen zum Training unzählige Varianten von Formulierungen, bis die Muster genügend eintrainiert sind — viel mehr als beispielsweise Kinder. Da dies Menschen irgendwann langweilig wird (und der Firma zu teuer), wurde das LLM genutzt, um aus diesen Pärchen noch weitere Varianten zu erzeugen. Menschen wurden nur noch eingesetzt, um die Bewertung dieser generierten Pärchen zu übernehmen. Noch später wurde auch die Bewertung automatisiert und nur noch die korrekte Bewertung anhand von Stichproben überprüft. Dieser Vorgang nennt sich «Reinforcement learning from human feedback» (RLHF; zu Deutsch etwa: Bestärkendes Lernen durch menschliche Rückkoppelung) und wird durch die zentrale grüne Rückkoppelungsschleife dargestellt.
Mehr wissen: Das z.T. dramatische Schicksal der Menschen in diesen KI-Testschleifen hat beispielsweise der Guardian beschrieben. Die riesigen benötigten Datenmengen wurden hier thematisiert. Einige Beispiele, wo das Training (z.T. peinlich) versagt hat, finden sich hier.
Lernschritt 3: Aus Fehlern lernen

Nicht immer werden die richtigen Muster angewandt. Beim «Schwangerschaftstest» oben wurde fälschlicherweise das «Dreisatz lösen»-Muster erkannt und damit nach diesem Muster vervollständigt.
Das hat natürlich damals unter den Geeks Gelächter verursacht und bei OpenAI ein paar rote Köpfe. Entsprechend wollte man dafür sorgen, dass solche Antworten zukünftig nicht mehr auftauchten.
Der KI-Ansatz dafür ist: Wir müssen die Muster zu Schwangerschaften stärken, damit bei solchen Fragen das Muster «Schwangerschaftsdauer» Oberhand gewinnt über «Dreisatz lösen». Natürlich könnte OpenAI nun die Menschen links oben in der Grafik dafür bezahlen, mehr Muster zu Schwangerschaften zu produzieren und den Lernschritt 2 (RLHF) zu durchlaufen. Das wurde wahrscheinlich auch gemacht. Das war aber mutmasslich nur ein Teil der Lösung.
Denn Menschen, die schon tausende von solchen Pärchen produziert haben, sind irgendwann in einem Trott angekommen: Sie liefern keine vollständig neuen, innovativen Muster mehr. Viel interessanter wird es, wenn eine KI-Firma solche Pärchen „crowdsourcen“ kann, also die Ideenvielfalt der gesamten Menschheit ausnutzen kann.
Oder, in diesem Fall, ihrer Nutzerbasis. Die KI-Chatbot-Nutzer:innen haben viele Ideen; stellen Dreisatz- oder Schwangerschaftsfragen auf viele verschiedene Art und Weise. Und deshalb sind Chats zu Dreisatz und/oder Schwangerschaft eine wertvoller Schatz an möglichen Fragestellungen, welche der Chatbot in der nächsten Version zuverlässig richtig beantworten können sollte.
Deshalb ist zu erwarten, dass die KI-Firmen dann die Chats ihrer Nutzer — sofern das in ihren AGBs vorgesehen war — nach solchen Dialogen durchkämmt haben und — wie schon in den Lernschritten 1 und 2 — einen Teil davon als Trainingsmaterial und einen Teil davon zum Testen genutzt haben, ob auch zuverlässig die richtige Fragestellung käme.
Mehr wissen: Dass die Ausgaben zufällig sind, wird im Rahmen der Erklärung der ChatGPT-Funktionsweise erklärt, aber auch beim Thema «Zufall» nochmals aufgegriffen und stärker motiviert. Wieso man Fehler (u.a. aufgrund dieses Zufalls) nie ganz eliminieren kann, erkläre ich im Artikel über das «Recht auf Vergessenwerden», welches sich mit KI-Systemen beisst. Die Herkunft dieser Nutzerdaten wird im Artikel über die dunkle Datenherkunft thematisiert.
Zusammenfassung

- Grundlagen und Konzept
- Im Gegensatz zu früheren Ansätzen verwenden moderne, LLM-basierte Chatbots heute keine expliziten — durch Softwareentwickler vorgegebenen — Regeln mehr.
- Es werden nur noch statistische Zusammenhänge zwischen den verschiedenen Textstellen erfasst und genutzt.
- Von allen Datensätzen wird vor dem Training ein Teil abgetrennt, der nur für Tests und Qualitätskontrolle verwendet wird («Testdaten»).
- Lernschritt 1: Training der Fakten und Sprachmuster
- Alle Muster, nach denen das Sprachmodell funktioniert, werden vom System selbst auf Basis von Trainingsdaten erstellt.
- Diese Muster sind nicht klar lokalisiert. Es gibt also kein Teil, auf den man zeigen könnte und sagen, „hier drin ist das Muster für «Dreisatz» gespeichert“. Alle Muster sind jeweils über das ganze Sprachmodell „verschmiert“.
- Um die Muster für (Satz-)strukturen und grundlegende Fakten überhaupt extrahieren zu können, sind für diese Trainings riesige Datenmengen nötig (grosse Anteile des gesamten Internet).
- Lernschritt 2: Training der Interaktion
- Dialog- und sonstige Interaktionsmuster sowie grundlegende Umgangsformen (der «Knigge», in der Fachsprache «Alignment»; die grünen Pfeile in den Datenflussgrafiken oben) werden über weitere Trainingsdaten für diese Muster erstellt.
- Um auch da genügend Trainingsdaten zu haben, werden die Frage-Antwort-Beispielmuster automatisiert vervielfacht und jedes Mal leicht abgeändert oder rekombiniert.
- Tests
- Auf allen Stufen werden immer Tests durchgeführt, ob auf die Testdaten sinnvolle Antworten gegeben werden. Erst dann wird das Training als abgeschlossen bezeichnet.
- Diese LLM-Tests unterscheiden sich von normalen Tests bei der Softwareentwicklung dadurch, dass sie meist nicht 1:1 reproduzierbar sind, sondern jede Antwort einmalig ist. Damit ist Korrektheit nicht einfach automatisiert zu prüfen.
- Lernschritt 3: Fehlerkorrektur
- Im Verlauf der obigen Trainings-/Testphasen oder im Livebetrieb werden Fehler bekannt.
- Um diese Fehler auszumerzen, werden möglichst viele Muster gesucht oder erzeugt, welche korrekte bzw. akzeptable Antworten verstärken.
- Dazu werden, wenn das die AGB entsprechend vorsehen, auch Daten aus Chats der Nutzer:innen verwendet.
- Zwischen den Erkennen des Fehlers und der Behebung vergehen häufig Wochen oder Monate.
Beim initialen Training, also bevor ein Sprachmodell an die Öffentlichkeit kommt, besteht vor allem aus den obigen Punkten 1-4. Sobald es im Einsatz ist, finden üblicherweise auf allen Stufen Nachbesserungen statt. Dazu sind möglichst viele menschliche Trainingsdaten nötig, die langsam aber sicher ausgehen, insbesondere wenn immer mehr Webseiten zumindest teilweise KI-generierten Text beinhalten.
Schlussfolgerungen
Wir wissen nun, wie Fehler entstehen und dass immer irgendwelche (zumeist systematische) Restfehler übrig bleiben. Daraus ergeben sich eigentlich auch zwei Schlussfolgerungen:
1. Die 80%-Regel
Meine Empfehlung an alle Anwender:innen von KI-Lösungen:
KI, gleich welcher Art, sollte nur für Dinge eingesetzt werden, die man zu mindestens 80% selbst versteht.
KI kann dafür eingesetzt werden, um uns repetitive Aufgaben abzunehmen. Aber — sobald wir KI nicht nur zum Spass einsetzen — sollten wir sie überwachen können. Das bedeutet auch, dass man sowohl die Zeit als auch auch die Fähigkeit haben muss, das zu tun.
Mehr wissen: Menschen sind sehr leichtgläubig, wenn Maschinen etwas behaupten; dies ist auch als «Automation bias» (Neigung, dem Automaten zu glauben) bekannt. Was passieren kann, wenn Menschen Entscheidungen von Maschinen zu sehr vertrauen (oder keine Zeit zur eigenen Meinungsbildung haben), haben wir auch schon beschrieben.
2. Automatische Entscheidungsfindung
KI-Systeme werden oft als Teil von Systemen zur automatischen Entscheidungsfindung («automated decision making», ADM) eingesetzt: D.h. der Rechner löst aufgrund von Übereinstimmungen mit irgendwelchen Mustern (scheinbare oder wahrhaftige) eine Entscheidung aus.
KI, gleich welcher Art, sollte automatisiert nur für Dinge eingesetzt werden, bei denen die automatische Reaktion kein Schäden auslösen kann (auch keine Imageschäden oder Benachteiligungen).
Ganz besonders fatal kann es sich auswirken, dass eine einmal entdeckte Schwachstelle beliebig oft ausgenutzt werden kann. D.h. wenn jemand einmal herausgefunden hat, wie man das System zu einer Fehlentscheidung übertölpelt, man beliebig viele ähnliche Fehlentscheidungen auslösen kann. Dies kann zugunsten des Angreifers oder zuungunsten des Systembetreibers oder eines Dritten sein.
Mehr wissen: Schon automatische Verkersschildererkennungen in Autos konnten ausgetrickst werden oder Sesam-Öffne-Dich-artige Reaktionen unentdeckbar in Bilderkennungssoftware versteckt werden. Auch Videoanalyse-Software, welche Stellenbewerber:innen psychologisch einschätzen sollte, liess sich einfach austricksen.
LLMs zu übertölpeln hat noch eine Stufe zugelegt und sich zu einer Art „Volkssport“ entwickelt: Manipulierte Webseiten, welche das Sprachmodell des Benutzers überlisten oder Lebensläufe, die der KI der Personalabteilung einen exzellenten Kandidaten vorgaukeln. Wer will, kann LLMs auch mal selbst spielerisch selbst zu übertölpeln versuchen (erste Tipps dazu).
U.a. aus diesem Grund haben rund 50 zivilgesellschaftliche Organisationen einen Appell an den Bundesrat gerichtet, dass er sich bitte gegen (absichtliche oder unabsichtliche) Diskriminierung via KI einsetzen solle. Den auch du mitunterzeichnen kannst.
Weitere Links [neu 2024-08-27]
- Gabriele Svelto: Not Left Handed AI Images by Asa Dotzler, Fediverse, 2024-02-14.
Ein Beispiel für Vorurteile durch (einseitige/zu wenig) Trainingsdaten: Der KI-Prompt, linkshändige Menschen bei Aktivitäten zu zeigen führt zu rechtshändigen Menschen. - Arsenii Alenichev, Patricia Kingori, Koen Peeters Grietens: Reflections before the storm: the AI reproduction of biased imagery in global health visuals, The Lancet, 2023-08-09 (PDF).
Während Bildgeneratoren kein Problem haben, kranke weisse Kinder oder schwarze Ärzte zu zeigen, schaffen sie es nicht, kranke weisse Kinder auf demselben Bild wie schwarze Ärzte zu zeigen.


4 Kommentare
Danke für den Artikel. Er beschreibt in einfachen Worten, was sich hinter den komplexen LLMs verbirgt. Er müsste für alle Pflicht werden, die die Tools verwenden, denn es bleibt dabei: Da ist kein Verständnis für die stochastischen Zusammenhänge, sondern nur das Erkennen von Korrelationen. Ich benutze immer das Beispiel, wie gut AI die neusten Forschugserkenntnisse über Covid-19 entdecken könnte. Wäre ja ein toller Usecase für unsere Policy-Maker. Nur, sind a) die neusten Erkenntnisse nicht in den Trainingsdaten enthalten, b) wenn sie extra hinzugefügt werden, sind sie sehr selten in den Daten zu finden, und c) wenn die Trainingsdaten sehr breit angelegt sind und z.B. Reddit, Telegram Gruppen oder ähnliches auch enthalten, dann Prost-Mahlzeit, denn dann überwiegen die nicht wissenschaftlichen Quellen und dann kommen eben die „Erkenntnisse“, die eben Meinungen von Heinz oder Gabi sind und nicht die peer-reviewed Fakten aus Journals. Wenn man böse ist, sind LLMs dann so gut wie gewisse Politiker, die lieber auf laute, aber kleine Minderheit der Aufschreier hört als auf Wissenschaft oder die schweigende Mehrheit, deren Daten ja nicht existieren. LLMs sind in diesem Sinne auch populistisch. Keine schöne Vorstellung.
Das Thema Quelle sprecht ihr auch gut an. Ich kann z.B. eine sehr spezifische Frage über Geschäftsmodelle stellen und dann kommt die Zusammenfassung eines Blogpost von mir. Natürlich ohne Quellenangabe.
Hallo Patrick,
Regeln zur Nutzung (oder Nichtnutzung) von Systemen aufzustellen funktioniert erst, wenn die Nutzer:innen wissen, wie diese Systeme funktionieren. Erst dann können sie sich die Regeln merken und die Sinnhaftigkeit davon beurteilen. Ich denke, das trifft aber auf jede neue Technologie zu. Nehmen wir das Feuer: Da wird es auch die Leute gegeben haben, die das gehypt haben und auf der anderen Seite die Leute, die gesagt haben, das komme ihnen nicht in die Höhle. Im Verlauf der Zeit hat man dann die Vorteile und Gefahren von Feuer kennengelernt und es nutzbringend eingesetzt.
Wenn wir nicht wissen, wie Chatbots funktionieren, können wir Nutzen und Risiken nicht richtig einschätzen. Und es gibt beides.
Dankeschön für den treffenden Kommentar!