

Wir trennen Abfall, recyclen; wir fahren Velo oder Zug statt Auto. Oder nehmen es uns mal wieder vor. Einige essen weniger Fleisch, auch aus Rücksicht auf die Umwelt. Gleichzeitig konsumieren wir Digitales wie Cloud, Streaming, KI etc. mehr ohne Überlegungen, was das für unsere Umwelt bedeutet. Dieser Artikel soll das Bewusstsein für unseren Digitalen Fussabdruck schärfen. Und auch aufzeigen, was wir als Individuum tun können. Und wo wir als Einzelne keinen Einfluss haben und damit Gesellschaft, Wirtschaft und Politik gefragt sind.
Dazu stellen wir uns insbesondere folgende drei Fragen:
- Wieso interessiert uns der Digitale Fussabdruck?
- Woher stammt der Ressourcenbedarf der „grossindustriellen“ Komponenten der Digitalisierung – Cloud, RZ und KI – und wie entwickelt er sich?
- Was können wir tun? Was müssen andere tun?
Digitaler Fussabdruck: Wieso interessiert er uns?
Wer in den letzten Monaten die Nachrichten verfolgt hat, ist auf Schlagzeilen wie diese gestossen. Die Nachricht: Der Energieverbrauch von Rechenzentren, insbesondere für KI, steigt und wird unsere Netze aus- oder überlasten und die Stromversorgung für Bestandskunden gefährden. Gleichzeitig sollen alte Kohlekraftwerke reaktiviert werden und neue Gaskraftwerk spriessen wie Pilze aus dem Boden.
Allenorts werden damit die Sorgenfalten noch bedenklicher:
- Für diejenigen, die auf Umweltschutz bedacht sind und denen die Folgen der menschgemachte Klimaerwärmung nicht egal sind, denen sind fossil betriebene Kraftwerktypen ein Dorn im Auge. Denn diese sind für ihren hohen CO2-Austoss bekannt.
- Wer hingegen noch fossil heizt oder ein Fahrzeug mit Auspuff fährt, dessen Bedenken sind eher finanzieller Natur: Werde ich mir angesichts der steigenden Erdöl- und Erdgaspreise noch eine warme Wohnung und Fortbewegung leisten können? Wie stark wird die höhere Nachfrage den Preis noch weiter in die Höhe treiben?
- Ähnliche Überlegungen stellen auch Industriebetriebe an, welche für die Herstellung ihrer Produkte Erdöl bzw. Kohlenwasserstoffe benötigen. Firmen für Düngemittel, Farben, Kosmetika und Kunststoffe fallen da gleich mal ein. Und ihre Kundinnen und Kunden.
Gleichzeitig gibt es Prognosen der Internationalen Energieagentur (IEA), nach denen der Stromverbrauch von Rechenzentren sich zwischen 2024 und 2030 rund verdoppeln soll. Und wenn KI wirklich der grosse Renner wird und nicht als platzende Blase endet, ist laut IEA noch mit einem weiteren Wachstum zu rechnen.

Kurz vor Jahresende 2025 hat Googles KI-Infrastruktur-Chef seine Mitarbeiter aufgefordert, dass sie die verfügbare Kapazität alle 6 Monate zu verdoppeln hätten.
| Monate | 6 | 12 | 18 | 24 | 30 | 36 | 42 | 48 | 54 | 60 |
| Faktor | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 |
| Jahr | 2026 | 2027 | 2028 | 2029 | 2030 |
Wenn Google dieses Tempo wirklich vorlegen kann, dann wird der Energiebedarf durch die Decke gehen. Ganz besonders, wenn man annimmt, dass die Konkurrenz nicht schläft, wie im folgenden Bild. Und selbst wenn sie schläft: Dann geht es 1–1½ Jahre später durch die Decke (Annahme: Google hat ⅛ bis ¼ der gesamten KI-Kapazität).

Eigentlich sollte schon eine Verdoppelung des Energieverbrauchs in den nächsten 5 Jahren ein Alarmsignal sein. The Atlantic berichtet in seiner kommenden April-Ausgabe ausführlich über die Entwicklungen im US-amerikanischen Data Center Valley bei Washington. Dort spriessen Rechenzentren gerade wie Pilze aus dem Boden, der Stromverbrauch soll in den nächsten Jahren um 20 GW steigen. Dazu werden unzählige Gaskraftwerke in Betrieb genommen, z.T. ohne die notwendigen Genehmigungen, was die Luftqualität in der Gegend weiter verschlechtert. Daneben werden auch alte Kohle- und Kernkraftwerke wieder in Betrieb genommen, beispielsweise der 2019 abgeschaltete Schwesterreaktor des 1979 teilweise geschmolzenen Reaktors in Three Mile Island bei Harrisburg, der jetzt als „Crane Clean Energy Center“ umgelabelt wird.
Laut desselben Atlantic-Artikels wurden in den USA in der KI-Boom-Phase seit 2022 Rechenzentren für 600 Milliarden USD gebaut. Und schon ein einzelnes dieser frisch geschlüpften Rechenzentren brauchte 50 Millionen Liter Kühlwasser, Alleine im September.
Energiebedarf und Funktion von Cloud, Rechenzentren und KI
Cloud
In den 1970er-Jahren hatten die Computernutzer eigentlich alles: In dedizierten, lauten Rechnerräumen standen die grossen, schweren Computer, die man mit Daten ab grossen Bändern oder Lochkartenstapeln füttern konnte. Und Software hatte man selbst geschrieben oder ebenfalls auf Bändern per Post mit Kollegen geteilt.



Dummerweise musste man immer zu den Rechnern hingehen. Und es gab sie nur an einigen Unis und Grossfirmen. Wie schön wäre es doch, dachte man sich damals, wenn nicht nur der Strom für die Rechner, sondern auch die Daten, die Rechenleistung und auch die Software aus der Steckdose käme! Und so entstanden über mehrere Schritte u.a. das Internet, das Web, Appstores und «die Cloud».

Grafik aus Wo genau geht es in die Cloud? Ein Wegweiser durch den Dschungel (2024-10-24).
Doch auch diese «Cloud» ist kein einheitliches Konstrukt. Darin laufen viele Anwendungen mit unterschiedlichen Eigenschaften und Bedürfnissen:

Aber es gibt nicht nur verschiedene Anwendungen in der Cloud, «die Cloud» wird auch als Begriff für modulares IT-Outsourcing genutzt. Am Vergleich mit einem Schrebergarten kann man die verschiedenen Stufen von Outsourcing gut erkennen: Auf der einen Seite haben wir eigene Beete auf eigenem Land, auf welchem wir selbst die Tomaten säen, pflegen und ernten. In verschiedenen Schritten beginnen wir das Land zu mieten und Services vom Hauswart oder Gärtner dazuzubuchen. Am anderen Extrem kaufen wir das Tomatensugo im Supermarkt. Also eigentlich ist «Cloud» gar kein Hexenwerk.

Also: Wenn jemand «Cloud!» sagt, kann er ganz unterschiedliche Dinge meinen, mit verschiedenen technischen Eigenschaften, verteilt über das ganze Spektrum von Outsourcing-Levels und unzähligen Varianten an Einflussmöglichkeiten durch die Kund:innen (oder auch dem vollständigen Mangel an Einfluss).
Mehr dazu in meinem früheren Artikel Wo genau geht es in die Cloud? Ein Wegweiser durch den Dschungel (2024-10-24).
Rechenzentrum
Also, hinter «der Cloud» (und auch jeder Webseite oder App) stehen Rechner, die einfach jemand anderem gehören. Und die mit einem Satz an Dienstleistungen gebündelt werden. Doch irgendwo müssen diese Computer stehen. Und diese Computer stehen in klimatisierten Gebäuden, sogenannten Rechenzentren.
Wie sieht denn so ein Rechenzentrum aus? Das erzählen die folgenden vier Bilder.




1. Ein Gang in einem Rechenzentrum, mit abschliessbaren Schränken zu beiden Seiten.
2. Einer der Schränke, mit offenen Türen; darin sind 17 Rechner mit je 12 Festplatteneinschüben zu sehen.
3. Luftströmung mit alternierenden Kalt- und Warmgängen: In die Kaltgängen strömt kalte Luft von unten, wird mittels Ventilatoren durch die Rechner gezwängt, wo sie sich erwärmt; in den benachbarten Warmgängen wird die warme Luft noch oben abgeführt.
4. Blick von oben auf einen Rechnerraum im CERN; die Kaltgänge sind oben abgedeckt (in normalen Rechenzentren hat es oberhalb der Racks kaum Platz, siehe Bild 1).
Wichtig zu wissen: Der gesamte Strom, der als Energie in einen Server hineingesteckt wird, wird als Wärme abgegeben (bis auf kleine Ausnahmen wie die blinkenden Lichter und das Geräusch der Luftströmung). Aus energetischer Sicht ist ein Server daher eigentlich ein teurer Heizlüfter, bei dem zufälligerweise noch Daten oder Rechenergebnisse rausplumpsen.
Bei Geräten mit Bildschirm (Fernseher, Tablet, Smartphone) ist das Licht des Bildschirms ein wichtiger Faktor für den Energieverbrauch, zumindest, solange dieser an ist. Bei Mobilgeräten (Tablet, Smartphone) hat auch das WLAN- oder Mobilfunkmodul einen Anteil am Energieverbrauch. Beides fällt aber bei Servern weg.
Klassische Künstliche Intelligenz und Maschinelles Lernen
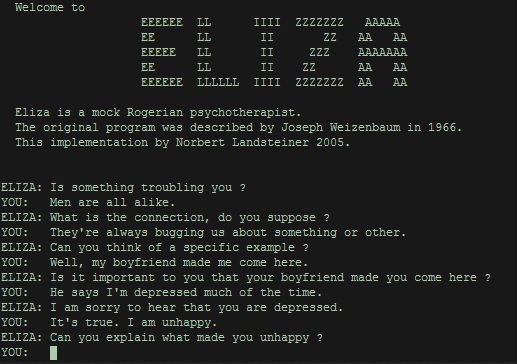
Der Name «Artificial Intelligence» wurde in den 1960er-Jahren geprägt. Eine erste Ausprägung war das Computerprogramm ELIZA von Joseph Weizenbaum, das eine Psychotherapeutin nachzuahmen versuchte. Durch die Wahl der klientenzentrierten Psychotherapie, die sich vor allem durch Rückfragen auszeichnet, war es einfach, einen Gesprächsverlauf zu simulieren. Das ELIZA-Programm suchte in den Eingaben der Nutzer:innen nach einzelnen Stichwörtern und stellte dann dazu eine Rückfrage. Als Computerantwort auf die Erwähnung von Familienmitgliedern wie Vater, Mutter, Bruder, Schwester kam dann ein Satz wie «Erzähl mir mehr über deine Familie.», den es in verschiedenen Formulierungen gab, damit die Automatismen nicht so auffielen. Doch obwohl es nur etwa 600 verschiedene Antwortmuster gab, fühlten sich einzelne Personen von dieser vorgeblichen Psychotherapeuting „verstanden“. Wer will, kann hier mal mit ELIZA chatten, in einer modernen Version der Hardware von damals.
Später versuchte man, solche Frage-Antwortmuster gezielter zu bauen. Das Ziel war, mit sogenannten Expertensysteme Menschen in komplexen Themengebieten wie Reparatur von Industrieanlagen oder Krankheitsdiagnose zu unterstützen. Doch die grossen Erfolge blieben aus. Zum einen war es schwierig, Satzverständnis (Verb/Subjekt/Objekt, Hauptsatz/Nebensatz etc.) zu programmieren, andererseits erwiesen sich diese Themengebiete als sehr schwierig abzubilden. Auch war die Erfassung der Zusammenhänge sehr komplex, zeitaufwändig und fehleranfällig.
Parallel entstand deshalb ein weiterer Zweig der KI: Die Maschine sollte selbst die Zusammenhänge erkennen können, selbst lernen. Der dazu verwendete Mechanismus, sogenannte neuronalen Netze, sollte das menschliche Gehirn mit seinen Neuronen nachbilden.
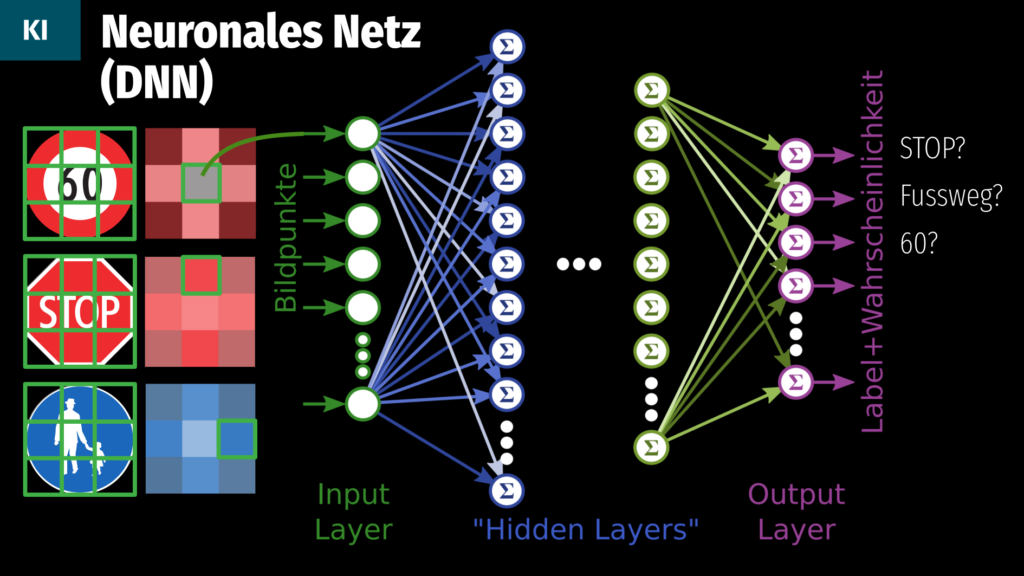
Ein neuronales Netz zur Verkehrszeichenerkennung könnte wie folgt aufgebaut sein: Links nimmt eine (für dieses Gedankenexperiment sehr einfache) Kamera ein 3×3 Pixel grosses Bild auf. Wenn man drei Verkehrsschilder nacheinander vor diese 3×3-Kamera hält, nimmt die Kamera ein 3×3 Pixel grosses Bild auf Jedes dieser 3×3 Pixel „sieht“ den Durchschnittswert (Farbe, Helligkeit) des entsprechenden Schilderbereichs. Diese 9 Inputs werden in den Input Layer des neuronalen Netzes gefüttert, das ähnlich wie ein mehrstufiges Mischpult aufgebaut ist, wobei die Mischstufen die sogenannten „Hidden Layers“ darstellen. Am Schluss gibt es dann für jedes zu erkennende Schild eine Lampe, die mit dem Namen eines Schildes angeschrieben ist. Das Ziel ist es, dass die Ausgangslampe heller oder dunkler leuchtet, je ähnlicher das Eingangsschild dem Namen am Ausgang ist.
Um das neuronale Netz zu trainieren, werden die Schalter am Mischpult anfänglich auf zufällige Positionen eingestellt. Welche Lampe bei welchem Schild wie hell aufleuchtet, ist damit auch völlig zufällig und in den allermeisten Fällen völlig falsch. Um das zu korrigieren, werden jetzt – sehr vereinfacht – der Reihe nach folgende Schritte ausgeführt:
- Eine der Tafeln wird vor die Kamera gehalten.
- Ein zufälliger Drehregler am Mischpult wird ausgewählt.
- Dieser wird leicht nach links oder nach rechts gedreht.
- Wenn danach die zur Tafel passende Lampe heller leuchtet (bzw. die anderen Lampen weniger hell) wird diese Position beibehalten, ansonsten wird der Regler wieder in seine Ursprungsposition zurückbewegt.
Dieser Prozess wird so lange wiederholt, bis die richtige Lampe sich bei jedem Schild deutlich von den falschen Lampen abhebt. Das sind schon bei sehr einfachen Aufgaben Abertausende von Wiederholungen.
Damit kann unser neuronales Netz nun die drei Schilder erkennen. Wenn aber ein unbekanntes Schild vor die Kamera kommt oder das Schild verschmutzt oder beklebt ist, kann das Resultat völlig falsch sein. Für viele Fälle ist das aber trotzdem gut genug.
Mehr zu neuronalen Netzen, Bildererkennung und den Fehlermöglichkeiten in meinem Artikel Machine Learning: Künstliche Faultier-Intelligenz (2022-08-16).
Moderne Künstliche Intelligenz: Grosse Sprachmodelle und Chatbots
Seit der Verfügbarkeit von ChatGPT Ende 2022 werden vor allem die Chatbots als „KI“ bezeichnet. Hinter diesen Chatbots stecken sogenannte Grosse Sprachmodelle, im Englischen als „Large Language Model“ (LLM) bekannt. Drei wichtige Schritte auf dem Weg von den oben beschriebenen KI-Systemen zu ChatGPT möchte ich hier nennen:
- Die Abkehr vom Versuch des strukturierten Satzverständnisses (also der Erkennung von Verb, Subjekt oder Objekt bzw. der Erkennung von anderen Satzmerkmalen wie Haupt- oder Nebensatz). Stattdessen werden einfach automatisiert unzählige statistische Zusammenhänge zwischen Zeichen und Zeichenketten erfasst. Diese Zusammenhänge haben keine für uns Menschen verständliche Struktur. Dazu werden riesige Mengen an Texten gebraucht. Moderne Sprachmodelle benötigen dazu riesige Datenmengen, mehr, als das gesamte Internet freiwillig hergibt.
- Die (relativ) kompakte Codierung dieser Zusammenhänge. Dies ist etwa vergleichbar mit der Bildkompression: Wenn man das Bild stärker komprimiert, wird die Datei viel kleiner. Trotzdem sind die wichtigsten Teile des Bildes weiterhin zu erkennen. Sehr vereinfacht gesagt ähnelt das auch der Kompression dieser riesigen Statistiken mit Zeichenabhängigkeiten, bei Sprachmodellen Transformer genannt.
- Neben den Texten aus dem Internet wurde ChatGPT und seine Kollegen (Gemini, Claude, Mistral, DeepSeek, Apertus, …) auch mit Frage-Antwort-Paaren trainiert. Dadurch verhalten sie sich interaktiv.
Mehr dazu in meinen früheren Artikeln Wie funktioniert eigentlich ChatGPT? (2023-01-30: Technik), Die KI ChatGPT und die Herausforderungen für die Gesellschaft (2023-01-28: Funktionsweise und Fehler), Die dunklen Daten-Geheimnisse der KI (2024-01-12: Datenquellen) und Petzt die KI? Schlimm? (2024-09-26: Interaktion und Korrektur-/Trainingsvorgänge).
Der Zuwachs
Bis in 5 Jahren ist laut der Hauptprognose der IEA mit einem Zuwachs des Strombedarfs von Rechenzentren um insgesamt rund 500 TWh pro Jahr zu rechnen. Das entspricht in etwa einer Verdoppelung. In der gleichen Zeit wachsen aber andere Industriebereiche noch stärker (in absoluten Zahlen).
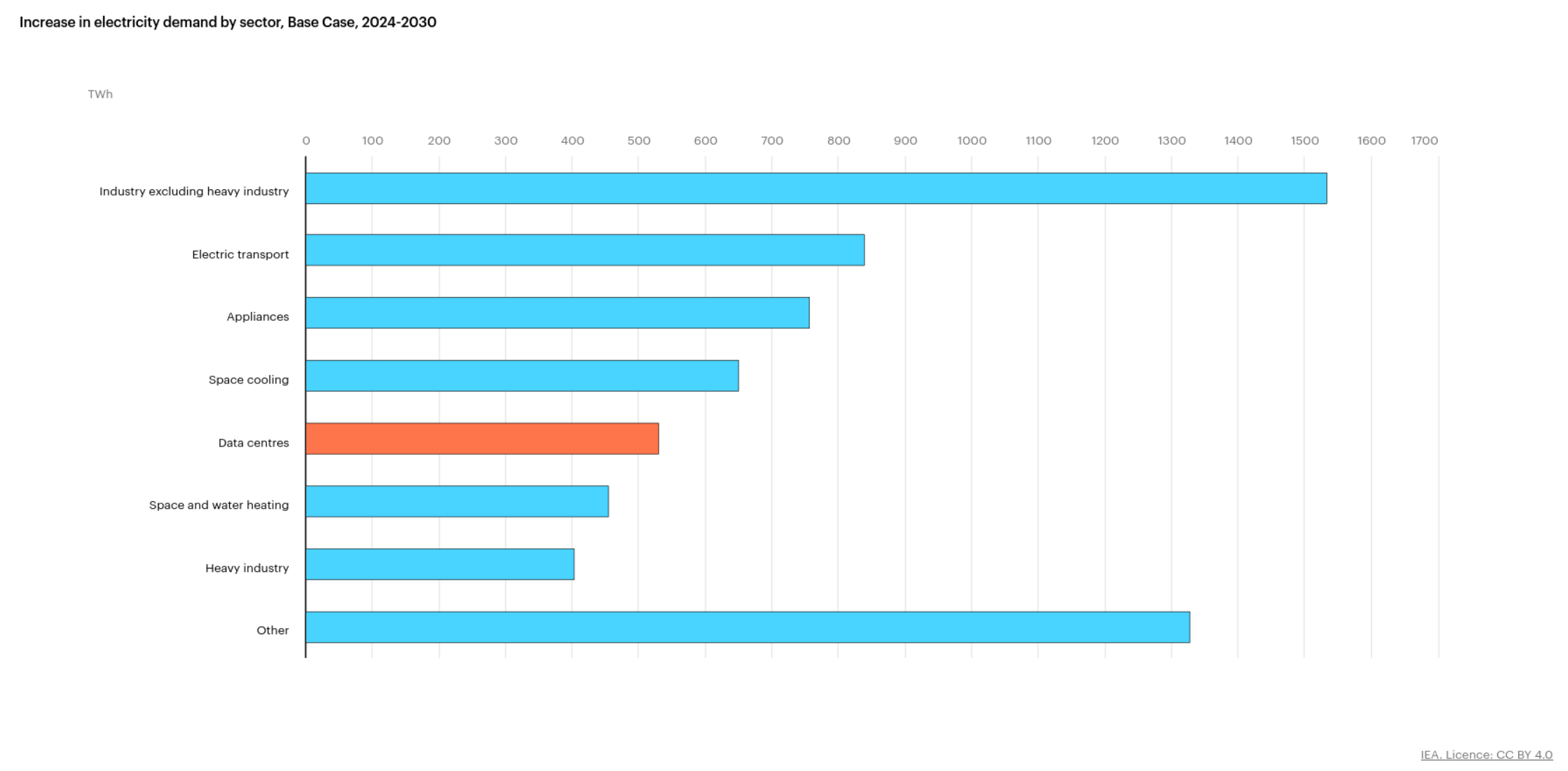
Insgesamt ist mit einem Zuwachs bis 2030 von rund 6500 TWh zu rechnen, oder über 700 GW Dauerlast.
Watt (und Mega-, Giga-, Terawatt) gegen Wattstunden?
Die Leistung eines Verbrauchers (eine Lampe, ein Heizlüfter oder eben ein Rechenzentrum) wird in Watt gemessen. Das entspricht dem Resultat von Spannung (in Volt) mal Strom (in Ampere). Ein Heizlüfter, der bei 230 Volt 10 Ampere Strom zieht, heizt also mit 230*10=2300 Watt und ist wahrscheinlich auch so angeschrieben. Die Leistung ist also etwas, was zu jedem Zeitpunkt gemessen werden kann.
(Der Einfachheit halber gehen wir bei allen Rechnungen von Gleichstrom aus, auch wenn unsere Wohnungen mit Wechselstrom gespiesen werden und dort die Berechnungsformel aufgrund der wellenförmigen Ströme und Spannungen zu leicht anderen Resultaten führen.)
Wenn unser Heizlüfter aber eine bestimmte Zeitdauer läuft, dann summiert sich seine Leistung über die Zeit zu einer Gesamtenergie, die er umwandelt (also Strom, den er bezieht und Heizleistung, die er liefert). Wenn unser Heizlüfter eine Stunde lang die Leistung von 2300 Watt liefert, entspricht das einer Energie von 2300 Wattstunden (Wh) oder 2,3 Kilowattstunden (kWh). Das ist auch das, was unser Stromzähler zählt. Bei einem Stromtarif von 30 Rappen pro kWh kostet eine Stunde Wärme unseres Heizlüfters also 2,3*30=69 Rappen.
Natürlich kann man das auch umrechnen: So entspricht eine Wattstunde 3600 Wattsekunden, auch bekannt als ein Joule.
Und wenn ein Kraftwerk (wie z.B. Gösgen) dauerhaft 1 GW ins Netz einspeist, speist das Kraftwerk im Jahr (1 Jahr=8766 h) 8766 GWh (oder 1 Gigawattjahr, aber diese Einheit ist nicht üblich) ins Netz ein.
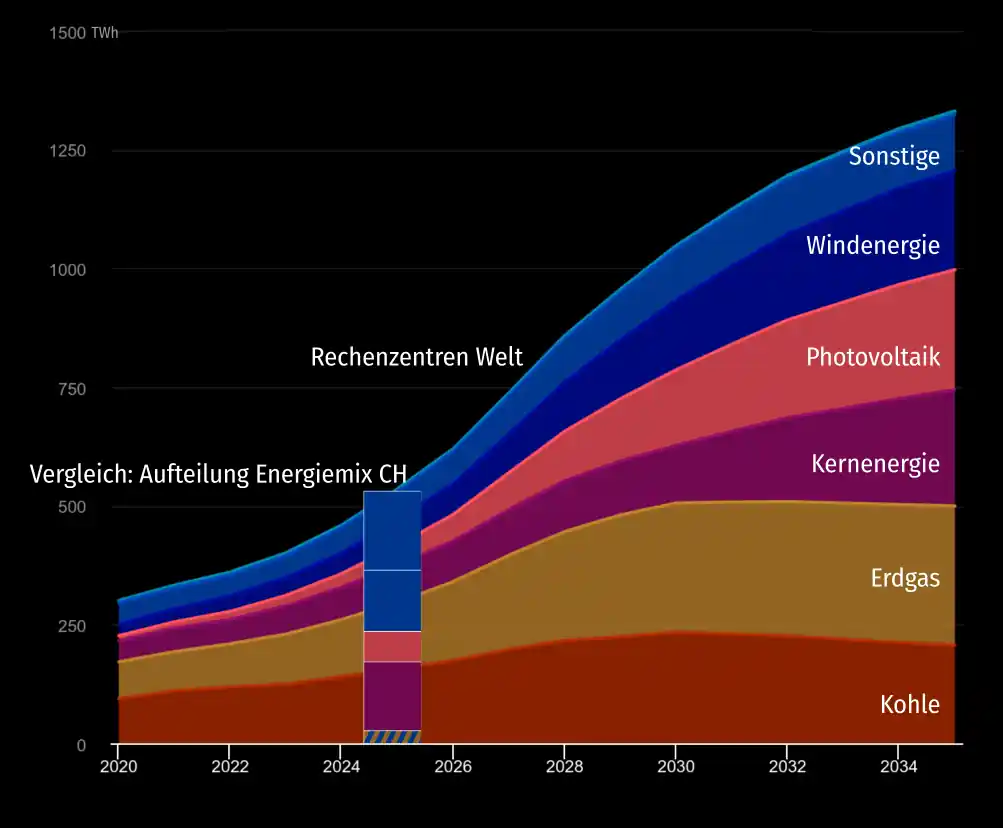
Zum Vergleich: Der Strombedarf bis 2030 steigt laut IEA um rund 6500 TWh, d.h. im Jahr 2030 werden 6500 TWh mehr verbraucht als 2024. Das entspricht rund 700 GW Dauerlast oder 700 Kraftwerken der Gösgen-Klasse (Gösgen liefert ziemlich genau 1 GW, wenn es in Betrieb ist; neuere Kernkraftwerke wie z.B. Flamanville liegen bei rund 1½ GW). Davon stammen rund 500 TWh (oder rund 60 Gösgen) für Rechenzentren, also eine Verdoppelung laut der Basis-IEA-Prognose. Wenn wir die angekündigte Google-Verdoppelungsrate als Massstab nehmen, wächst der Rechenzentrumsbedarf aber nicht auf das Doppelte, sondern um das 100- bis 1000-Fache, also um 50’000 oder 500’000 TWh, entsprechend 6’000 bis 60’000 Gösgen.
Zum Vergleich: Der weltweite Gesamtstromverbrauch 2024 lag bei rund 30’000 TWh, würde also – je nach Prognosemodell – um 6 % bis Faktor 15(!) zunehmen.
Der Gesamtenergieverbrauch 2024 (inklusive Brenn- und Treibstoffe) lag bei rund 180’000 TWh, also 6x höher als der Stromverbrauch.
Lösungsoption 1: Zusätzliche Kraftwerke
Die offensichtlichste Lösung ist natürlich der Neubau bzw. die Reaktivierung von Kraftwerken.
Angesichts des Klimawandels und der Abgase müssten fossile Kraftwerke (als Gas- und Kohlekraftwerke) die Ausnahme bleiben und können auf keinen Fall als Standardlösung in Betracht gezogen werden.
Erneuerbare Energiequellen haben ein sehr grosses Potenzial, sie haben aber keine garantierte Verfügbarkeit, sind abhängig vom Sonnenlicht oder Wind. Glücklicherweise sind Sonne und Wind relativ unabhängig bzw. ergänzen sich sogar: In 150-200 m über Boden ist der Wind grundsätzlich konstanter und in der Nacht sogar stärker als tagsüber.
Trotzdem sind Sonne und Wind (wie aber auch der Regen und damit der Füllstand von Speicherseen oder das Laufwasser im Fluss) nicht kontrollierbar. Eine sogenannte „Dunkelflaute“ (also ein Zeitpunkt, in dem weder Solar- noch Windkraftwerke Energie liefern) ist also durchaus möglich. Wie wir aber gerade an der Blockade der Strasse von Hormus und den steigenden Erdölpreisen sehen, gibt es Ähnliches wie Dunkelflauten auch bei Erdöl und Erdgas.
Solar- und Windkraftwerke benötigen also immer auch Speichermedien, um die Leistung mindestens ein paar Stunden zu verschieben. Für die eigenen Solarpanels auf dem Hausdach mag das ein Batteriespeicher sein, für grössere Zeiten eignen sich bei uns Pumpspeicherwerke.
Kernkraftwerke
In letzter Zeit geistert immer wieder die Idee von neuen Kernkraftwerken durch den Blätterwald. Insbesondere Politiker mit Beziehungen zu grossen Energiekonzernen denken zunehmend darüber nach. Neben den althergebrachten Kernkraftwerken wie Beznau, Gösgen oder Leibstadt kommen auch vermehrt sogenannte „Small Modular Reactors“ (SMR) ins Spiel, die angeblich in naher Zukunft unsere Energieprobleme lösen sollen. Doch davon gibt es bisher weder Prototypen noch ist es wahrscheinlich, dass die in der Nachbarschaft beliebter sein werden als die klassischen KKWs.
Bei Kernkraft wird argumentiert, dass sie die Lücke beim Ausbau von erneuerbaren Energien decken könnten. Doch die zwei letzten in Europa gebauten Kernkraftwerke, Flamanville und Olkiluoto, brauchten rund 18 Jahre Bauzeit, Planung und andere Vorbereitungen nicht eingerechnet. Und Flamanville muss nach knapp einem Jahr Betrieb schon in die erste grössere Revision, da der Reaktordeckel noch ausgetauscht werden muss. Bis zur stabilen Inbetriebnahme vergehen also mindestens 20 Jahre und es wird über 23 Milliarden € gekostet haben.
Kernkraftwerke liefern Bandenergie, sie können kaum geregelt werden und ihre Energieproduktion lässt sich nur in einem schmalen Band regeln. In einer Zeit, in der erneuerbare Energien Realität sind, kann solche Bandenergie aufgrund ihrer mangelnden Regelbarkeit nicht zur Ergänzung der Erneuerbaren herangezogen werden.
Und davon, dass die notwendigen Uranbrennstäbe alle aus geopolitisch kritischen Regionen stammen und das Entsorgungsproblem immer noch nicht gelöst ist, wollen wir gar nicht erst sprechen.
Mehr zur Illusion von baldigen magischen Kernkraftwerken bei Bert Hubert (Nuclear power: no, yes, maybe, but not like this; 2024-08-10) oder einem 6-Minuten-Interview von Prof. Dr. Volker Quaschning in der deutschen Tagesschau (Sehr teuer und riskant; 2026-03-11). Aus diesen beiden Beiträgen stammen auch viele der Informationen in diesem Abschnitt.
Lösungsoption 2: Rechenzentren im Weltraum
Eine weitere Idee, die im letzten Jahr von Big-Tech-Milliardären aufgebracht wurde: Hey, packen wir die Rechenzentren doch in den Weltraum!
Auf den ersten Blick erscheint das wie eine gute Idee: Auf der einen Seite strahlt die im erdnahen Weltraum rund doppelt so stark wie auf der Erde, da die Atmosphäre (und die Ozonschicht) mit ihrer Licht- und UV-Absorption wegfällt. Und auf der anderen Seite ist es im Weltraum sehr kalt, also müsste Kühlung doch kein Problem sein.
Doch genau diese Kühlung ist im Weltraum viel schwieriger als auf der Erde. Wann kühlen wir im Winter am stärksten aus? Wenn wir etwas Kaltes berühren, beispielsweise ein Metallgeländer. Oder wenn uns eine kalte, feuchte Bise um die Ohren zieht. Im Weltraum haben wir aber bekanntermassen weder kühle Geländer noch Wind. Anders gesagt: Es gibt weder (unbegrenzte) Wärmeleitung noch Wärmetransport. Es bleibt nur die Abstrahlung von Hitze in den Weltraum. Und ihre Effizienz ist abhängig von der Oberflächentemperatur des Strahlers. Aufgrund ihrer vielfach höheren Temperatur (ca. 6500 K) ist die Sonne aber viel effizienter, etwas aufzuheizen, als das fliegende Rechenzentrum (rund 30° C oder 300 K) in der Lage ist, sich abzukühlen.
Daher ist nicht nur eine riesige Solarfläche notwendig (ca. 1 Fussbalfeld für einen einzelnen KI-Rechenzentrums-Schrank), sondern nochmals eine mindestens so grosse abgeschattete Fläche zur Kühlung. Zumindest kann die Kühlfläche im Schatten der Solarpanels aufgebaut werden.
Weitere Probleme betreffen die Kommunikation (es sind wohl keine wirklich hohen Bandbreiten möglich). Ein beinahe unlösbares Problem dürfte auch die kosmische Strahlung und ihr schädlicher Einfluss auf die Chips sein. Die Chips, die bisher im Weltraum genutzt werden, haben „Leiterbahnen“ und Transistoren auf dem Chip, die Dutzende Male dicker sind, als was heutige KI-Chips und ihre RAM-Speicher einsetzen. Entsprechend ist die Chance, dass eines der tausende Kilometer pro Sekunde(!) schnellen geladenen Teilchen der kosmischen Strahlung dort irgendein durcheinander anrichtet, noch um ein mehrfaches höher (die Strukturen sind in alle drei Dimensionen dünner, was die Verwundbarkeit noch viel stärker steigen lässt).
Mit einem einzelnen Rack voller KI-Rechenleistung kommt man heute nicht weit. Die KI-Rechenzentren, die aktuell gebaut werden, haben hunderte bis tausend Racks. Ebenfalls sind KI-Rechenzentren sind bei der aktuellen Technologieentwicklung innert 2–3 Jahren veraltet. D.h. um auch nur ein modernes Rechenzentrum auf der Erde zu ersetzen, müssten 1000 solcher Racks in den Weltraum geschossen werden, jedes mit fussbaldfeldgrossen Solar- und Kühlanlagen. Und nach 2-3 Jahren würden sie „entsorgt“ werden, möglicherweise durch Eintritt in die Erdatmosphäre. Damit bei einer Lebensdauer von 3 Jahren immer 1000 Racks im Weltraum wären, müsste täglich ein neues in eine Erdumlaufbahn geschossen werden.
Das alles erscheint kaum realistisch. Ausser in den Träumen von Tech-Milliardären, die sich über Umweltschutzregeln auf der Erde ärgern und denen jedes Mittel recht ist, um ihren Willen zu bekommen.
Die Informationen im obigen Abschnitt stammen zu einem grossen Teil von Taranis: Datacenters in space are a terrible, horrible, no good idea, 2025-11-28. Dort finden sich weitere Informationen und Hintergründe.
Lösungsoption 3: Weniger Nutzung
Damit bleibt uns eigentlich nur weniger Nutzung von Elektrizität, also die Reduktion unseres «Digitalen Fussabdrucks». Hier einige Möglichkeiten dafür.
Weniger Streamen
Fraunhofer Fokus hat sich im Projekt «Green Streaming» den Energieverbrauch von Streaming angesehen. Erstaunlicherweise ist der gar nicht so hoch. Bei der Nutzung eines grossen Fernsehers beispielsweise ist der Stromverbrauch des Fernsehers höher, als die Daten von den Servern bis zum Fernseher zu transportieren.
Interessant aber der Stromverbrauch von den verschiedenen Technologien, mit denen die Filme in die heimische Stube transportiert werden: So ist das Schauen von Live-TV nicht unbedingt energieeffizienter als das Streaming. Wer beispielsweise Kabelfernsehen live schaut, benötigt fast doppelt so viel Energie, wie jemand, der via Glasfaser streamt. Dafür ist Live-TV ab der heimischen Satellitenschüssel rund doppelt so sparsam wie Streamen über Mobilfunk oder einen DSL-Anschluss, wie die folgende Grafik zeigt:
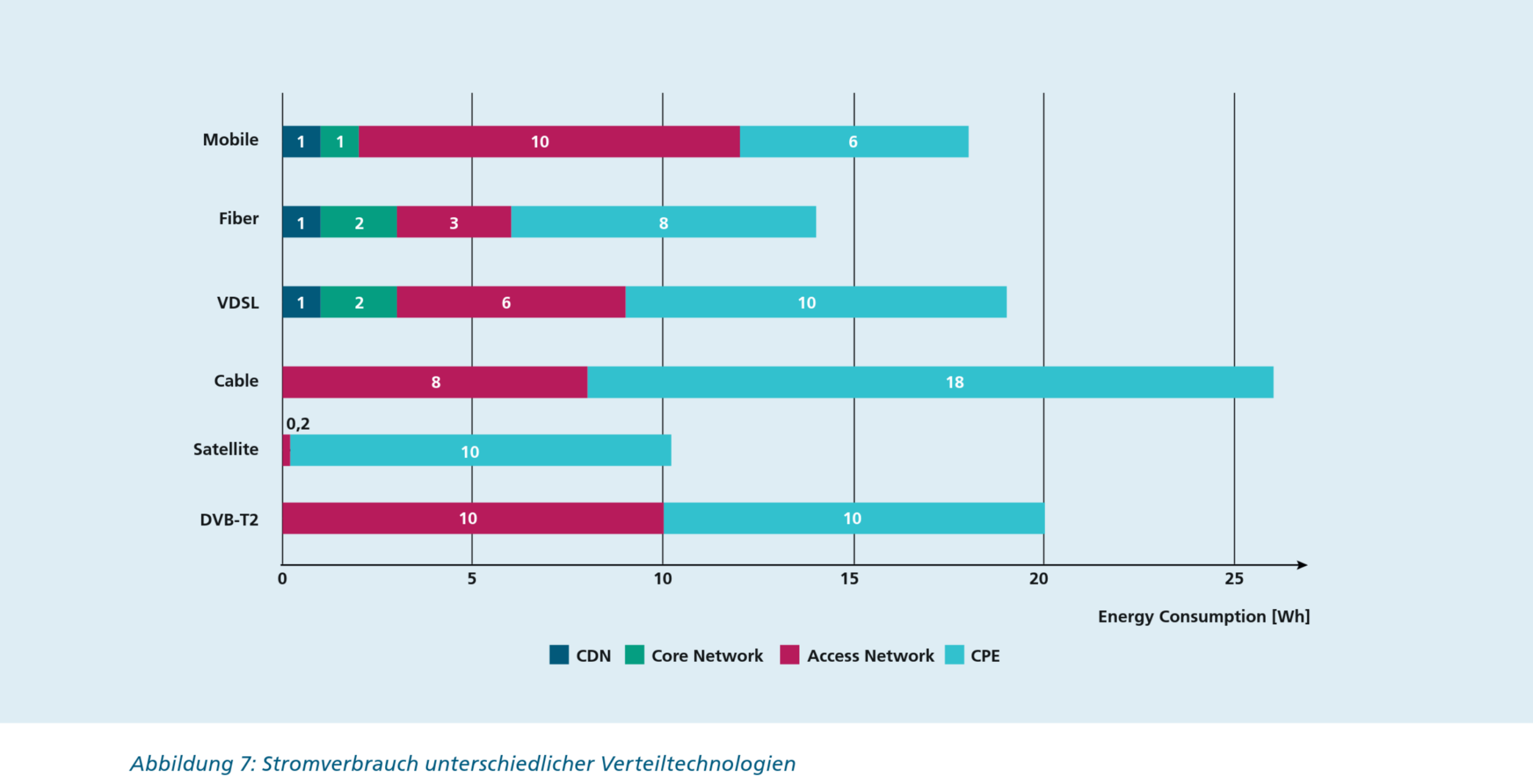
Zu beachten ist, dass der Stromverbrauch der terrestrischen Ausstrahlung von Fernsehprogrammen (roter Balken bei „DVB-T2“) unabhängig davon ist, wie viele Personen gerade fernsehen. Er verteilt sich dann einfach auf mehr oder weniger Personen. Ähnliche Überlegungen treffen – in reduziertem Ausmass – auch auf die anderen zentral erbrachten Dienste zu.
Interessant auch die Feststellung, dass in vielen Fällen die Geräte in unserem Heim (die hellblauen Striche, als „CPE“, „Customer Premises Equipment“, in etwa „Geräte am Ort des Kunden“ bezeichnet), einen Grossteil des Stromverbrauchs ausmachen. Cloud (dunkelblau) und Internet (grün) sind auch beim Streaming nur ein Bruchteil dessen, was das Netzwerkequipment beim Internetanbieter (rot) und bei uns zu Hause (eben hellblau) ausmachen.
Also: Streamen über Glasfaser auf das Handy oder Tablet ist vorbildlich.
Cloudspeicher aufräumen
Eine weitere Idee, die oft auftaucht: Räumt doch euren Cloudspeicher auf, dann braucht es weniger Festplatten!
Beginnen wir dazu mit dem Speicherbedarf üblicher Mediendateien:
- Ein 500 Seiten langes Buch ohne Illustrationen belegt ca. 2 kB (Kilobyte) pro Seite, also insgesamt rund 1 MB (Megabyte). Text lässt sich aber etwa um den Faktor 10 komprimieren, oft noch mehr. D.h. ein Buch benötigt ca. 100 kB.
- Ein Bild meines Handys ist im Durchschnitt etwa 2 MB gross. Das dürfte bei vielen Feld-Wald-Wiesen-Handys ähnlich aussehen.
- Ein Film auf DVD belegte oft 5 GB (Gigabyte), manchmal auch 9. HD-Filme haben zwar eine höhere Auflösung, verwenden aber auch bessere Kompressionstechniken. Bleiben wir mal bei der Schätzung von 5 GB. Ein 1-Minuten-Ferienvideo dürfte etwa ein Hundertstel davon sein, also ca. 50 MB.
Wer jetzt eine USB-Festplatte kauft, dürfte mit einer Festplatte von rund 3 TB (Terabyte) Speicher gut beraten sein. Es gibt aber auch Festplatten mit der zehnfachen Kapazität (30 TB), die für grosse, selten benutzte Speichermengen ideal sind. Im Ruhezustand (einfach drehen, kein Lese- oder Schreibzugriff) benötigen beide etwa 5 W.
Hier ein Überblick über die Anzahl Dateien jeden Typs, die auf unsere zwei Beispielfestplatten passen:
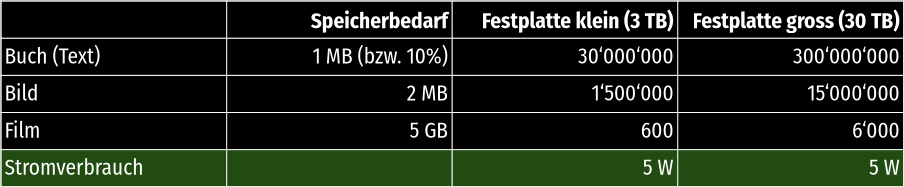
Um also eine Festplatte oder 5 W zu sparen, müsste man Abermillionen von Büchern löschen, Millionen von Bildern entsorgen oder rund Hunderttausend Ferienfilme aus seinem Online-Gedächtnis verbannen.
Sehr viel Aufwand für ein Resultat, was man auch mit Ausziehen des Steckers des Fernsehers erreichen kann (also Wechsel vom Standby in den Stromlos-Zustand).
Übrigens: Rechenzentrumsbetreiber sind froh, wenn nicht alle Daten auf ihren Festplatten und Datenträgern dauernd gelesen und geschrieben werden. Denn je „aktiver“ die Daten genutzt werden, desto mehr aktive Nutzer:innen müssen sich die relativ geringe Geschwindigkeit und Bandbreite der Festplatte teilen. Wenn der Rechenzentrumsbetreiber also den Kund:innen eine akzeptable Geschwindigkeit bieten möchte, muss er mehr Festplatten kaufen. Die Anzahl der Festplatten und ihre Stromaufnahme hängt also nur teilweise von der Menge der darauf gespeicherten Daten ab; mindestens so wichtig ist im Serverumfeld, wie viele Anfragen an die Platten kommen. Deshalb nutzen datentransferintensive Speichersysteme viele kleine Festplatten anstelle von wenigen grossen.
Weniger KI nutzen
Wir haben gesehen, dass KI-Rechenzentren sehr viel Strom fressen und demnächst wahrscheinlich noch ein Vielfaches davon. Alleine für die konservativ prognostizierte Zunahme des KI-Energiebedarfs wäre bis 2030 die Inbetriebnahme von über 20 Gösgen notwendig. Das klingt doch noch einem Ansatzpunkt. Was verbrauchen denn unsere KI-Anfragen so etwa? MIT Technology Review hat das letztes Jahr analysiert.
| Anfrage | Energiebedarf | Umgerechnet |
|---|---|---|
| Eine Textanfrage (Chatbot) | 0,2 – 3 Wh | < 1 km Autofahrt |
| Eine Bilderzeugung | 0,3 – 1 Wh | < 1 km Autofahrt |
| Ein 5 s-Video erstellen | 1000 Wh | 200 km Autofahrt, 20 Schnitzel |
Für jede kleine Anfrage könnte mal also ein paar Minuten mit dem Benziner im Quartier herumkurven; schon für ein kurzes Video kann man mit dem Diesel in die Ferien fahren oder die ganzen guten Vorsätze zur Reduktion des CO2-Fussabdrucks bei der Ernährung der letzten Wochen zunichte machen. Und meist bleibt es ja nicht bei einem Text, einem Bild oder einem Video. Bis man zufrieden ist mit dem Resultat sind oft etliche Versuche notwendig. Und bei jeder könnte man wieder mit dem Auto um den Block fahren.
Zusammenfassung
Es bleibt also recht wenig, was man als Einzelne:r so tun kann. Und gerade beim Hype-Thema KI soll man verzichten? Dabei brauchen wir das dringend, um die Komplexität unserer Gesellschaft zu verstehen und zu managen. Was sollen wir also tun?

KI wird aber nicht nur zur Vereinfachung von Prozessen eingesetzt, sondern auch absichtlich zur Platzierung von wertlosen oder gar vollständig falschen Informationen. Um mit der daraus resultierenden Flut klar zu kommen, sind wir wieder auf KI angewiesen. Eine Schleife.
Um aus dieser Schleife auszubrechen, wären folgende Schritte nötig, im Interesse unserer gesamten Wirtschaft und Gesellschaft:
- Prozesse und Abläufe, die wir nutzen wollen (oder müssen), sollten von Anfang an so einfach und klar definiert sein, dass sie auch von jemandem ohne Vorerfahrung verstanden werden und fehlerfrei genutzt werden können.
- Wir brauchen mehr zuverlässige, vertrauenswürdige Informationsquellen und -kanäle.
- Weil die beiden anderen nicht so schnell kommen (wenn überhaupt), müssen wir unbedingt in allen Gesellschaftsschichten auch für mehr Medien- und Informationskompetenz sorgen.

Der Nutzen von Digitalem Cleanup
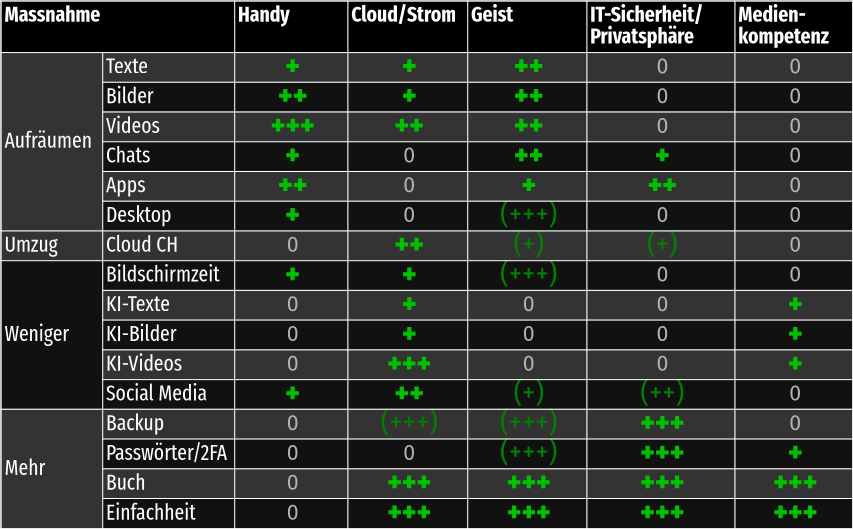
Das Aufräumen von Texten, Bildern und Apps, bringt aber nicht nur Vorteile bezüglich Stromverbrauch, sondern hilft auch, den Überblick über unsere Daten und unser Leben wiederzuerlangen. Insbesondere die Reduktion von unnötigen Applikationen kann auch zu mehr IT-Sicherheit und Privatsphäre beitragen. Hier ein Versuch, die verschiedenen Vorteile tabellarisch zusammenzufassen.
Take Home Message
Für eine nachhaltige Gesellschaft, nicht nur in Bezug auf den Digitalen Fussabdruck, sollten wir folgende Themen mit nach Hause (oder an die Arbeitstelle und in die politischen Prozesse) nehmen:
| Streaming | Cloud, Speicher | KI | Weniger ist besser | Klarheit |
|---|---|---|---|---|
| Über Glasfaser | USB-Festplatte | Reduzieren, Alternativen nutzen | Keine Selbstkasteiung | Einfache Abläufe |
| Auf kleinen Bildschirm | In der Schweiz | Keine Videos generieren | Ausbau erneuerbarer Energiequellen | Zuverlässige Informationsquellen |
Wenn jeder sich nur einigen wenigen Punkten annimmt, wird unsere Gesellschaft besser. Für uns und unsere Nachkommen.
Auch wenn die Wirtschaft und ihre Bosse eigentlich die Verantwortung tragen müssten.
Weiterführende Literatur
Wer mehr zum Thema wissen will: Hier sind weiterführende Texte; viele davon dienten auch als Quelle für diesen Artikel oder zumindest als Inspiration.
Digitale Nachhaltigkeit
- Eine kurze Anleitung zur nachhaltigen Digitalisierung/digitalen Nachhaltigkeit, Ratgeber, Digitale Gesellschaft und WOZ, 2021-10-29
- Erik Schönenberger: Eine kurze Anleitung zur Nachhaltigkeit im Digitalen, Digitale Gesellschaft, 2021-10-29
- Rahel Estermann: Weg von Microsoft 365 und der Amazon-Cloud: Wie wir digitale Souveränität schaffen, Digitale Gesellschaft, 2025-11-07
- Digital Independence Day, di.day
- Free Software Foundation Europe, fsfe.org
- Marcel Waldvogel: Hype-Tech, 2023-05-03
Energiebedarf durch (KI-)Rechenzentren
- Stefan Krempl: Das KI-Energie-Dilemma: Wenn der digitale Boom die Netze überlastet, Heise, 2025-12-01
- Sarah-Indra Jungblut: Rechenzentrumsausbau auf Kosten der Stromkunden? Das Energieproblem hinter dem KI-Hype, Algorithmwatch, 2025-11-25
- Jennifer Elias: Google must double AI serving capacity every 6 months to meet demand, AI infrastructure boss tells employees, CNBC, 2025-11-21
- Matteo Wong (Text) und Landon Speers (Bilder): Inside the Dirty, Dystopian World of AI Data Centers, The Atlantic, 2026-04
- Michael Andai: Musks Supercomputer frisst so viel Strom wie der Kanton Aargau, 20 Minuten, 2026-01-22
Statistiken und Prognosen Energieproduktion und -verbrauch
- Energy and AI, Internationale Energieagentur (IEA), 2025-04-10
- Elektrizitätsstatistik, Bundesamt für Energie (BFE)
- Energiedashboard, Bundesamt für Energie (BFE)
- Energy Production and Consumption, Our World in Data
- Sinken die Strompreise auch in Ihrer Gemeinde?, SRF, 2024
- Kostenstruktur Wasserkraft, BFE, 2014
- Berechnungsfaktoren Wasserkraft, BFE
Cloud-Technologie erklärt
- Marcel Waldvogel: «Die Cloud» gibt es nicht, DNIP, 2022-09-30
- Marcel Waldvogel: Wo genau geht es in die Cloud? Ein Wegweiser durch den Dschungel, DNIP, 2024-10-24
- Marcel Waldvogel: Die Cloud als Spielball der Winde, DNIP, 2025-02-27
- Bert Hubert: Die Cloud, der unkündbare Subunternehmer, DNIP, 2025-05-01
Rechenzentren
- Taranis: Datacenters in space are a terrible, horrible, no good idea, 2025-11-28
- DNIP Briefing #52: Datencenter im Weltall, DNIP, 2025-12-02
(Generative) Künstliche Intelligenz
- ELIZA Talking, Masswerk (ELIZA mit Sprachein- und -ausgabe)
- Marcel Waldvogel: Machine Learning: Künstliche Faultier-Intelligenz, 2022-08-16
- Marcel Waldvogel: Wie funktioniert eigentlich ChatGPT?, DNIP, 2023-01-30
- Patrick Seemann: Warum trotz ChatGPT Schlagzeilen über den Tod des Internets verfrüht sind, DNIP, 2023-02-24
- Marcel Waldvogel: Marcel pendelt: «KI» und «Vertrauen», DNIP, 2023-12-11
- Marcel Waldvogel: Die dunklen Daten-Geheimnisse der KI, DNIP, 2024-01-12
- Patrick Seemann: ChatGPT besteht den Turing-Test, gilt KI jetzt als intelligent?, DNIP, 2024-07-15
- Marcel Waldvogel: KI zwischen Genie und Wahnsinn: Fehler und ihre Elimination in Chatbots, 2024-09-25
- Marcel Waldvogel: Petzt die KI? Schlimm?, DNIP, 2024-09-26
- Patrick Seemann: Wie gut verstehen LLMs die Welt?, DNIP, 2024-10-29
- Patrick Seemann: KI ersetzt (noch) keine Journalisten, DNIP, 2025-04-14
- DNIP Briefing #51: Baue, baue Rechenzentrum, DNIP, 2025-11-25
- DNIP Briefing #53: Die Blase, DNIP, 2025-12-16
KI und Effizienz
- 2025 State
of AI code quality, Qodo
609 Freiwillige, kurze, wenig reproduzierbare Studie, Eigeninteresse: 78% fühlen sich schneller, 14% sogar 10x - Joel Becker, Nate Rush, Elizabeth Barnes, and David Rein: Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity, Model Evaluation and Threat Research (METR), 2025-07-10
16 Freiwillige, längere, solide Studie: Die Entwickler fühlten sich 20 % schneller, waren aber gemessen 19 % langsamer - Mike Judge: Where’s the Shovelware? Why AI Coding Claims Don’t Add Up, 2025-09-03
1. Wenn alle Entwickler 10x produktiver seien, müsste sich doch das im Zuwachs bei Open-Source-Projekten zeigen; dieser ist aber nicht sichtbar.
2. Selbstexperiment über 1½ Monate: Morgens Zeitschätzung für das Tagesprojekt und erst dann (Münzwurf) entschieden, ob er die Aufgabe mit oder ohne KI-Unterstützung durchführt. Mit KI-Unterstützung war er 21 % langsamer als ohne.
Fussabdruck
- MIT Technology Review: In a first, Google has released data on how much energy an AI prompt uses, 2025-08-21
- MIT Technology Review: We did the math on AI’s energy footprint. Here’s the story you haven’t heard, 2025-05-20
- Tagesspiegel: Der Klimarechner für deine Küche
- Billionaires emit more carbon pollution in 90 minutes than the average person does in a lifetime, Oxfam, 2024-10-28
- Rebecca Solnit: Big oil coined ‘carbon footprints’ to blame us for their greed. Keep them on the hook, The Guardian, 2021-08-23

