

„Nun ist nicht nur Petra Gössi erstaunt, auch die beiden NZZ-Journalisten sind baff. Sie sind gerade Zeugen eines Datenklaus geworden, der ihre berufliche Existenz infrage stellt. Wer soll noch für Zeitungsabonnemente zahlen, wenn man gratis oder für eine Gebühr von etwa 20 Dollar pro Monat jede Zeitung auf der Welt durchforsten kann?“
Diese dramatischen Zeilen klingen alarmierend.
Die beiden NZZ-Journalist:innen lassen sich von FDP-Ständerätin Petra Gössi vorführen, wie ein Artikel eines Medienhauses rund um eine politische Diskussion um des Verwaltungs- und Sicherheitsgebäude Kaltbach im Kanton Schwyz von einem KI-Modell angeblich „geklaut“ worden sei.
Worum geht es aber? Der Einsiedler Anzeiger, eine unabhängige Lokalzeitung, ist hinter einer sogenannten «harten Paywall» (dazu später mehr) auch aus dem Internet abrufbar. Der besagte Artikel thematisiert die Frage, ob sich der Kanton Schwyz diesen Neubau für fast 140 Millionen Franken leisten solle.
Nun hat aber das Textgenerator-KI-Tool Perplexity offenbar die Vor-und Nachteile dieser Debatte in wenigen Klicks zusammengefasst. Die NZZ-Journalist:innen suggerieren, dass die KI-Antwort nicht anders habe zustanden kommen können als durch Training auf Basis des Artikels des Einsiedlers Anzeigers:
„Doch beinahe der gesamte Inhalt des Artikels ist in der Antwort von Perplexity zu lesen.“
Alle Zitate aus: Christina Neuhaus und Barnaby Skinner: Petra Gössi macht den Chatbot-Test: Klaut sich die KI ihre Inhalte aus Zeitungen zusammen?, NZZ, 2024-09-21.
Sie schreiben zudem: „Ausser den lokalen und regionalen Medien berichtet niemand darüber.„
Bei DNIP sind wir uns gewohnt, Fragen zu stellen. Und bei diesem Artikel drängen sich uns etliche Fragen auf. Fragen, bei denen wir auch von einer Qualitätszeitung wie der NZZ erwartet hätten, sie zu stellen. Wie kann es sein, dass Gössis Behauptung unwidersprochen stehen gelassen wurden? Dass sie weder nachvollziehbar dokumentiert noch irgendwie eingeordnet worden sind?
Wir versuchen das für unsere Leser:innen nachzuholen.
Zeitliche und örtliche Einordnung des Artikels
- Der publizierte NZZ-Artikel stammt vom 21. September.
- Das Treffen mit Gössi in der NZZ-Redaktion fand „im Spätsommer“ statt.
- Der Artikel im Einsiedler Anzeiger wurde am 9. August publiziert.
Der Artikel im Einsiedler Anzeiger ist allerdings bei Weitem nicht der Einzige, der das umstrittene Bauprojekt thematisiert. Alleine aus dem Zeitraum Juli bis September fanden wir im Medienarchiv SMD insgesamt sechs Artikel. Einer davon stammt von der Agentur SDA, eines vom Kurznachrichtenportal nau.ch, eines sogar von SRF Audio.
Die Aussage, nur lokale Medien würden berichten, ist also falsch. Der SRF Audio-Beitrag handelte explizit vom Pro und Contra der Vorlage. Er erschien am 2. September (vielleicht noch vor dem Treffen mit Gössi, genau wissen wir das nicht).
Erstaunliches Erstaunen
Erstaunlich ist aber vor allem das Erstaunen, das dem Sammeln der Trainingsdaten durch KI-Bots zwei Jahre nach dem ChatGPT-Hype entgegengebracht wird. Denn zum Kerngeschäft der Online-Zeitungen gehört seit Jahrzehnten auch die detaillierte Steuerung, welche Kundengruppe welche Artikel sehen darf; inklusive, was die Datensammler («Crawler») der Suchmaschinen zusammentragen dürfen.
Lange Leitung
Grosse KI-Sprachmodelle («LLM», Large Language Model) haben meist einen Wissensstand, der dem Internet um mehrere Monate hinterherhinkt. Gewisse KI-Modelle, wie dasjenige von Bing (inzwischen unter dem nicht ganz eindeutigen Namen «Microsoft Copilot») oder eben das im NZZ-Artikel zitierte Perplexity, versuchen das durch Kombination mit Livesuche abzukürzen:
- Aufgrund der Benutzeranfrage («Prompt») wird eine Websuche generiert
- Die in den Ergebnissen dieser Websuche referenzierten Webseiten werden heruntergeladen
- Diese Inhalten werden — neben den bereits im LLM vorhandenen Daten — temporär als Zusatzinformationen für die Beantwortung dieser Benutzeranfrage nutzbar gemacht
- Mit Basiswissen plus temporären Zusatzinformationen wird nun die Frage beantwortet
Sowohl Bing als auch Perplexity geben die für die Zusatzinformationen herangezogenen Webseiten an. Hier beispielsweise eine aktuelle Antwort von Perplexity auf die Frage «Nenne mir die Vor- und Nachteile des Verwaltungs- und Sicherheitsgebäudes Kaltbach im Kanton Schwyz»:
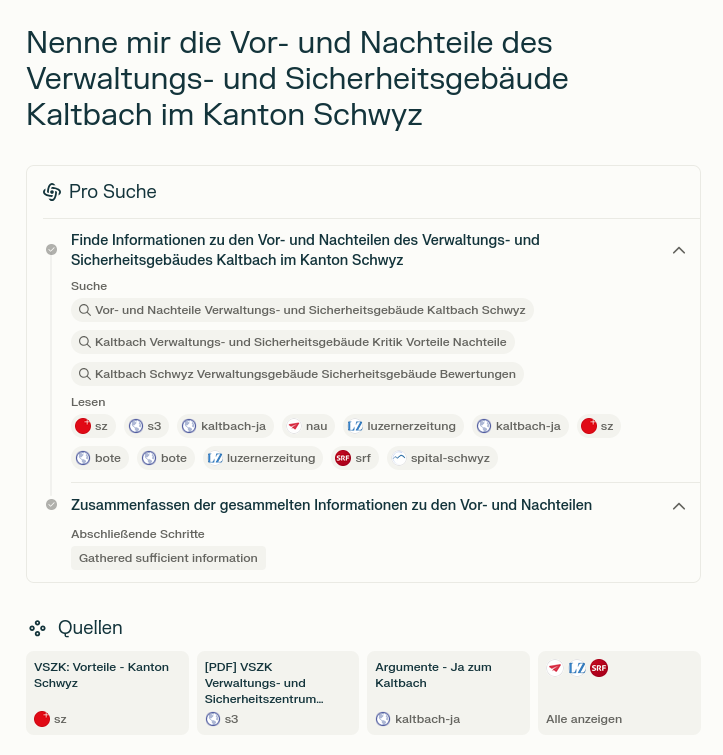



Benutzt wurden drei offizielle Quellen des Kantons Schwyz, zwei Seiten des Befürworterkomitees, drei Seiten des «Bote der Urschweiz» (eine davon ein PDF einer Zeitungsseite auf der Webseite des Spital Schwyz), je eine Seite der Luzerner Zeitung, von Nau.ch und von SRF. Hier fehlt der Einsiedler Anzeiger. Natürlich wird eine Suche im Spätsommer andere Resultate geliefert haben und andere Quellen benutzt haben. Aber schon im April war auf Nau.ch ein Artikel von Keystone-SDA zum Thema publiziert worden und Nau.ch scheint KI-Crawlern keinerlei Einschränkungen aufzuerlegen.
Wie wirken Paywalls?
Rund um die Funktion von Paywalls herrscht viel Unklarheit, u.a. auch, weil sich die Zeitungen nur ungern in ihre Karten schauen lassen wollen. Schauen wir uns deshalb ein paar typische Beispiele an:
- Harte („hard“) Paywall: Der Artikelinhalt ist zahlenden Leserinnen vorbehalten. Deshalb schickt der Webserver der Zeitung nur die ersten paar Sätze des Artikels überhaupt mit, um sonstige Besucherinnen „gluschtig“ zu machen, die beispielsweise via Suchmaschinen auf die Seite gefunden haben.
- Harte Paywall mit Ausnahmen: Eine harte Paywall hat den Nachteil, dass weniger Verbreitung via Suchmaschinen und soziale Medien erfolgt. Entsprechend gibt es Varianten der harten Paywall, die Suchmaschinen zu erkennen versuchen und sie wie zahlende Leserinnen behandeln, ihnen also trotzdem den vollen Artikel ausliefern. (Andere — in der Tabelle nicht erwähnte — Ausnahmen sind, dass der Artikel die ersten paar Stunden für alle lesbar ist oder dass der Artikel nach einigen Wochen für alle lesbar wird. Diese Techniken zielen auf die Verbreitung in sozialen Medien und/oder Suchmaschinen.)
- Weiche („soft“) Paywall: Der gesamte Artikeltext wird vom Webserver zurückgeliefert. Der Webbrowser versteckt aber nach Erhalt des Textes den grössten Teil davon, falls die Leserin nicht eingeloggt ist, z.B. mittels JavaScript.
- Keine Paywall: Der gesamte Artikeltext wird zurückgeliefert. Dies ist oft bei werbefinanzierte oder kostenlosen Online-Angeboten der Fall, beispielsweise hier bei DNIP. Beim Online-Magazin Republik wurde eine Variante davon gewählt: Wer den Link zu einem Artikel kennt, kann diesen lesen; aber die Einstiegsseite zeigt nicht alle Artikel an.
| Harte Paywall | Hart mit Ausnahmen | Weiche Paywall | Keine Paywall | |
|---|---|---|---|---|
| Mit Login zurückgeliefert | Ganzer Artikel | Ganzer Artikel | Ganzer Artikel | Ganzer Artikel |
| Für Suchmaschinen-Crawler zurückgeliefert | Nur Kurzversion | Ganzer Artikel | Ganzer Artikel | Ganzer Artikel |
| Ohne Login zurückgeliefert | Nur Kurzversion | Nur Kurzversion | Ganzer Artikel, mit JavaScript-Code, der das meiste verdeckt | Ganzer Artikel |
| Für KI-Crawler zurückgeliefert | Nur Kurzversion | Nur Kurzversion | Ganzer Artikel | Ganzer Artikel |
Optionales Stoppschild (robots.txt) | Wenig sinnvoll | Wenig sinnvoll | Möglich | Möglich |
| Beispiele | Tages-Anzeiger | New York Times | NZZ | DNIP, Republik |
robots.txt-Optionen auf den Zugriff auf Inhalte. Die oberen drei Zeilen sind in diesem Kapitelchen erklärt, die unteren beiden im nächsten.Beispiel: Keine Paywall (DNIP)
Wenn man eine URL im Webbrowser eintippt oder einem Link folgt, führt der Browser im Wesentlichen folgende Schritte aus:
- Er lädt den Inhalt der angegebenen URL herunter.
- Wenn dies eine HTML-Seite ist (also, eine normale Webseite), hat es darin weitere Verweise, beispielsweise auf nachzuladende Bilder, Beschreibungen über das Aussehen der Seite („style files„) oder JavaScript-Code, der interaktive Funktionen auf der Seite definiert (z.B. zur Überprüfung der Formulareingaben oder für ein Spiel auf der Seite). Diese Dokumente lädt der Browser nach.
- Aufgrund dieser gesammelten Informationen stellt der Browser dann die Seite dar.
- Zu diesem Zeitpunkt kann auch bereits geladener JavaScript-Code der Webseite ausgeführt werden. Dieser kann z.B. auch den Inhalt oder die Darstellung der Webseite verändern.
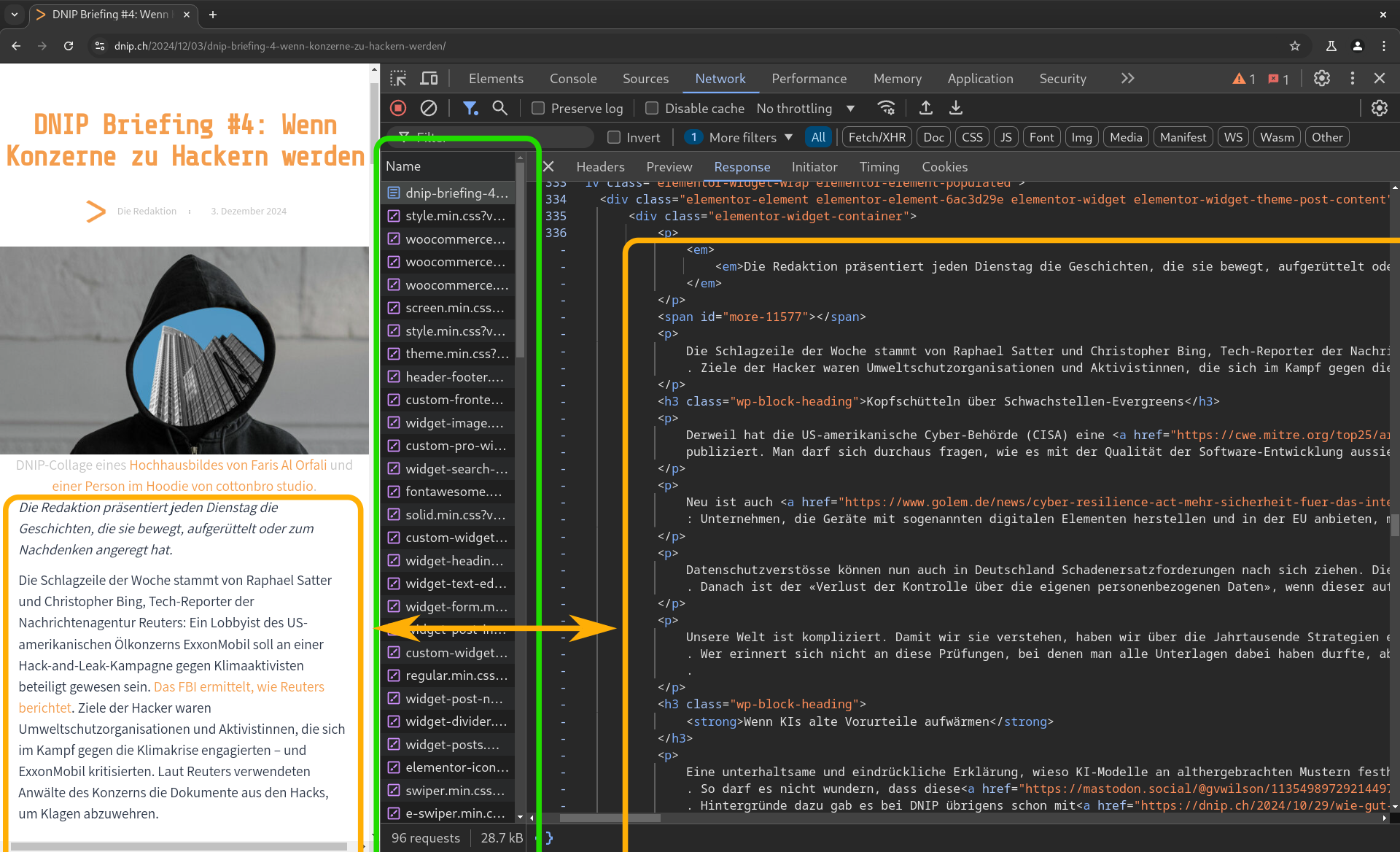
Dies sieht man sehr schön im unten stehenden Screenshot, der die Webseite mit geöffneten Entwicklertools zeigt. Diese Werkzeuge sind bei jedem Browser dabei; ohne sie wäre das Erstellen von Webseiten (und das Finden von Fehlern) unendlich viel schwieriger.
- Der grüne Rahmen umfasst die Namen der nachgeladenen Dokumente
- Die beiden orangen Rahmen zeigen den Text der Webseite: links, so wie wir die Webseite sehen; rechts, so wie er vom Webserver geliefert wird. Beispielsweise umfassen die
<p>…</p>-Paare rechts jeweils einen Absatz (engl. „paragraph“) des Artikels.
Bei DNIP und anderen Angeboten ohne Paywall wird allen Leserinnen derselbe Text zurückgeliefert, egal ob eingeloggt oder nicht.
Beispiel: Soft Paywall (NZZ)
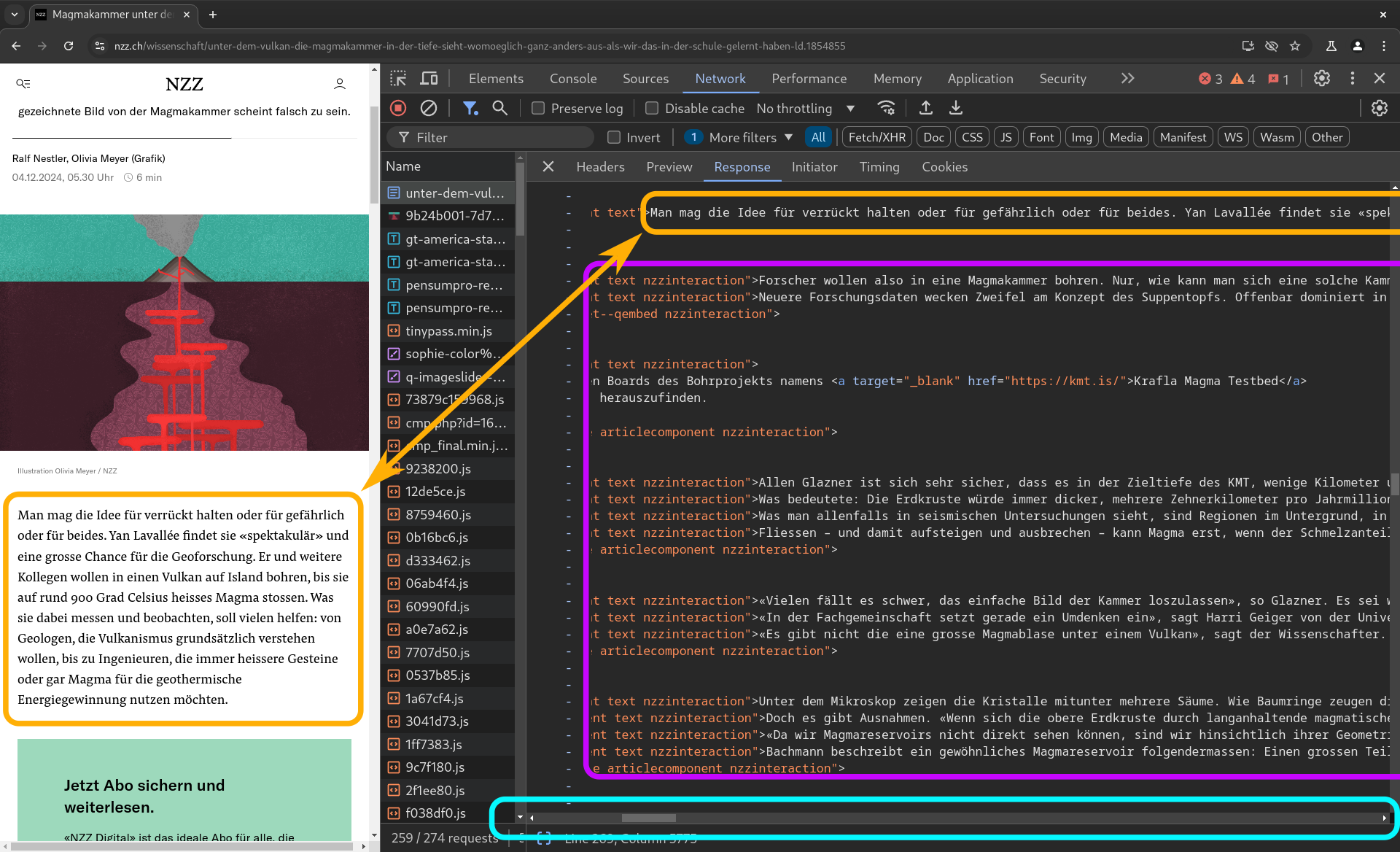
Bei einer Soft Paywall, wie sie beispielsweise die NZZ einsetzt, wird auch allen Nutzerinnen der gesamte Text des Artikels zurückgeliefert. Aber der ebenfalls beim Laden der Seite zurückgelieferte JavaScript-Code blendet dann allen Text nach den ersten paar Sätzen aus, wenn man nicht fürs Abo bezahlt hat.
- Die orangen Rahmen zeigen wieder den Text des ersten Abschnitts.
- Der violette Rahmen umfasst den Text nach dem ersten Abschnitt. Dieser wird vom NZZ-Webserver ebenfalls allen Nutzerinnen bereitwillig und ungefragt zurückgeliefert.
- Der Scrollbalken im hellblauen Rahmen weist darauf hin, dass die Inhalte weitergehen. Die Abschnitte sind also nur auf dem Screenshot abgeschnitten.
Der Vorteil einer Soft-Paywall ist, dass die Crawler der Suchmaschinen „automatisch“ den gesamten Text erhalten und so problemlos nach allen im Artikel genannten Stichworten gesucht werden kann. (Solange man keine weiteren Massnahmen ergreift, erhalten natürlich alle Crawler den Text, nicht nur die der Suchmaschinen.)
Beispiel: Hard Paywall (Tages-Anzeiger)
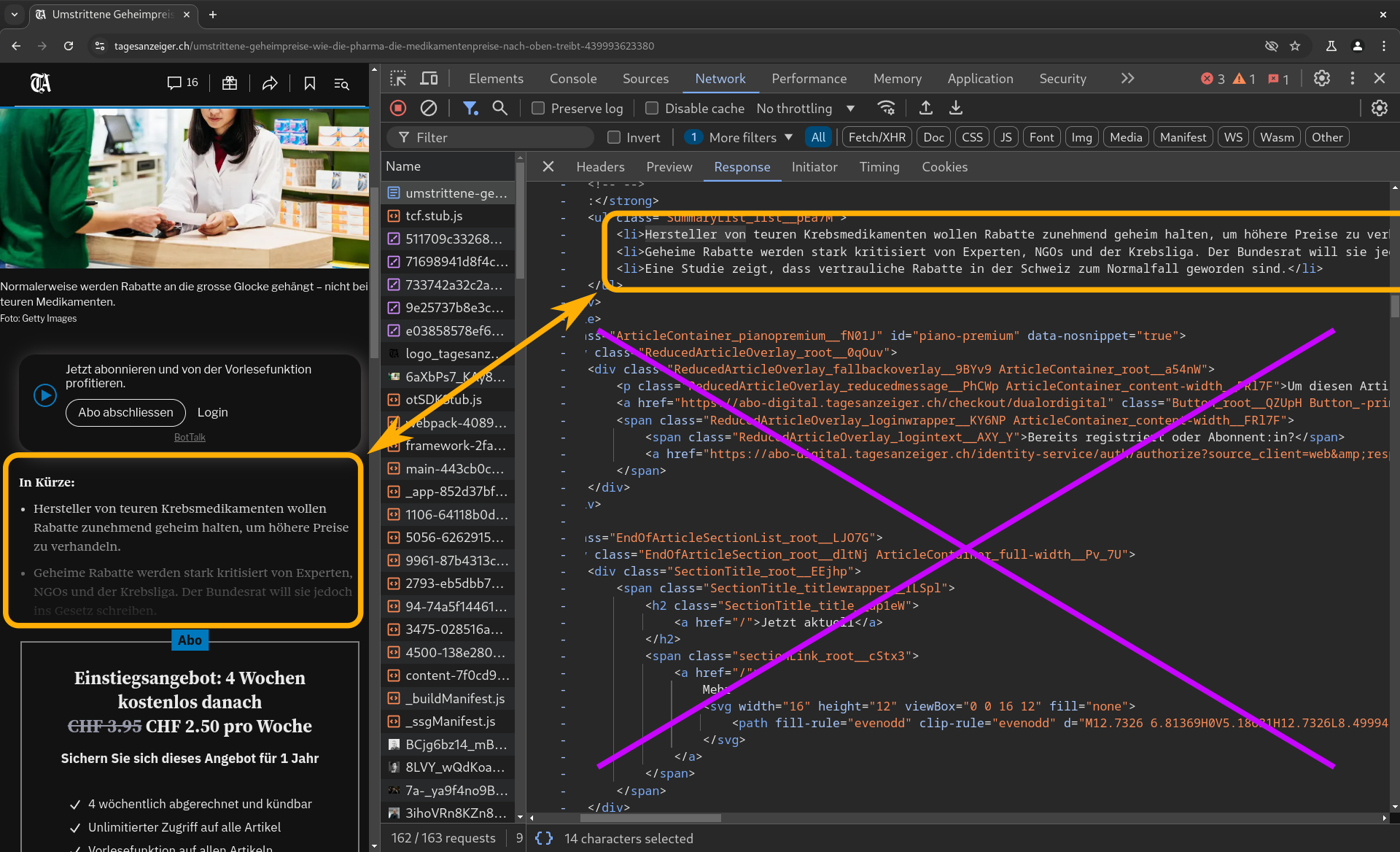
Die Tamedia-Blätter setzen auf eine Hard Paywall: Das heisst, es werden wirklich nur die ersten paar Sätze zurückgeliefert. Hier sehen wir im orangen Rahmen rechts zwar drei Punkte der Aufzählung, sichtbar sind aber nur die ersten 1½ (links; unten ausgeblendet).
Wir sehen aber insbesondere, dass der Rest des Artikeltexts überhaupt nicht zurückgeliefert wird, symbolisiert durch das violette Kreuz über dem HTML-Code.
Beim Tages-Anzeiger bekommen also nur die Abonnentinnen den gesamten Text zugestellt.
Der „In Kürze“-Block zu Beginn ist nicht nur für uns Leser:innen gedacht, sondern soll mutmasslich auch möglichst viele Stichworte für die Suchmaschinen liefern. (Ob der Tagi gewissen Crawlern von Suchmaschinen auch den gesamten Text zurückliefert, haben wir nicht überprüft.)
Wie blockiert man KI-Crawler?
KI-Crawler wie auch alle andere Crawler blockiert man am einfachsten mit einer harten Paywall: Dann kommt niemand an den eigentlichen Artikelinhalt, ausser natürlich den zahlenden und eingeloggten Abonnent:innen.
Wer aber eine weiche (oder gar keine) Paywall hat, hat immer noch Möglichkeiten:
robots.txt, das «Fahrverbotsschild für Webcrawler»: Vor 30 Jahren waren Webserver noch deutlich schwachbrüstiger als heute. Einige Webcrawler überlasteten diese ersten Webserver mit der Anzahl ihrer Abfragen. Dies war einer der Gründe, wieso der sogenannte «robots exclusion standard», ein Gentlemen’s Agreement zwischen Webservern und Crawlern, ins Leben gerufen wurde, mit denen man Crawlern signalisieren kann, wie sie sich auf dem Webserver zu verhalten hätten. Die meisten Crawler halten sich an diese Hinweise, auch KI-Crawler. Aber die Details sind etwas komplizierter (auch Perplexity soll sich gemäss einigen Medienunternehmen früher nicht daran gehalten haben).- Aktive Crawler-Abwehr: Die meisten Crawler laufen mit einem öffentlich sichtbaren Namensschild durchs Web; Webserver könnten ihnen also ganz einfach das digitale Äquivalent eines Hausverbots erteilen. Auch diejenigen, die ohne Namensschild herumlaufen, kann man meist anhand ihres Verhaltens oder der verwendeten IP-Adresse erkennen. Es gibt mehr oder weniger ausgeklügelte Filterlisten im Internet, anhand derer man diese Webcrawler identifizieren und sperren kann.
Kurz: Mit einer harten Paywall hält man sich alle Crawler zuverlässig vom Leib; bei weicher Paywall oder ganz ohne ist es immer noch sehr einfach, die meisten Crawler fernzuhalten.
Was macht der Einsiedler Anzeiger?
Der Einsiedler Anzeiger verwendete scheinbar eine weiche Paywall: Beim Laden eines Artikels ist oft erst kurz der gesamte Artikeltext zu sehen, bevor dieser dann von einer Aufforderung zum Login oder Abonnement ersetzt wird.
Der einfachste Weg für den Einsiedler Anzeiger wäre gewesen, mittels dem oben erwähnten robots.txt ein «Fahrverbotsschild» für KI-Crawler aufzustellen. Mit dem essenziellen Online-Forschungstool Wayback Machine des Internet Archive haben wir herausgefunden, dass der Einsiedler Anzeiger zwischen 9. Oktober und 10. November 2024 ein solches eingerichtet hat, also nach Erscheinen des NZZ-Artikels.

Zum Vergleich: Die Republik.ch zum Beispiel hat alle wichtigsten KI-Crawlern (Meta, OpenAI, Anthropic etc) zu verstehen gegeben: Don’t look, don’t touch. Hingegen dürfen sich Suchmaschinen-Bots weiterhin bei den Republik-Artikeln bedienen und diese indexieren.
Rechtliche Lage
In Deutschland gibt das Urheberrecht (wie auch andere EU-Staaten) folgende Bestimmung vor: Theoretisch dürfen die Crawler abgrasen, ausser man wehrt sich aktiv dagegen. Es braucht einen maschinenlesbares Opt-Out, also die Regieanweisung für den Nicht-Zugriff auf Inhalte. Dies könnte theoretisch auch im Impressum festgehalten sein, doch darauf springen die Crawler meist nicht an.
Effektiver ist da das Textfile robots.txt. (Man könnte jetzt gemäss c’t auch alle Blockwörter noch irgendwie hinterlegen, wie „nackt“ oder „pinkeln“, um zu verhindern dass man im Korpus von Google landet. Denn Google filtert solche Wörter automatisch),
In der Schweiz gibt es noch keine klare Bestimmung oder Rechtsprechung, denn das Training der Modelle bedeutet noch kein unmittelbare 1:1 Verwendung von urheberrechtlich geschütztem Material. Erst eine (fast) unveränderte Reproduktion der Inhalte würde gegen das bestehende Urheberrecht verstossen. Am effektivsten beugt man wie gesagt technisch vor mit maschinenlesbaren Anweisungen.
Die Befürworter des Leistungsschutzrechts (Verlegerverband Schweizer Medien bestehend aus den Grossen wie die NZZ, CH Media, Tagesanzeiger und Ringier) möchte die KI-Modelle noch in der Vorlage integriert sehen, die offenbar immer noch ausgearbeitet wird. Jüngste Aussagen von SVP-Bundesrat Albert Rösti deuten ebenfalls darauf hin. Am 5. Forum der Westschweizer Medien sagte er, dass die private Medien nicht durch den Staat gerettet werden können, sondern durch die Regulierung der Internetgiganten (sprich: durch das Leistungsschutzrecht) und eine allfällige KI-Regulierung (inwiefern Medien von stärkeren Digitalgesetzen gegenüber Big Tech-Unternehmen direkt profitieren sollen, bleibt unklar).
Die NZZ-Journalist:innen hätten ohne Weiteres kurz innehalten können bei der «KI-Vorführung» von FDP-Ständerätin Petra Gössi. Und sich fragen können: Auf welcher Datenbasis folgt der Zugriff des Perplexity-Chatbots? Und hat der Einsiedler Anzeiger genügend technische Anweisungen gegeben an die Crawler?
Stattdessen blieben die Journalist:innen perplex ab der Perplexity-Vorführung (pun intended). Und hatten entweder keinen Instinkt, diesen Sachverhalt genauer zu recherchieren. Oder aus politisch-ideologischen Gründen dies unterlassen.
Wir fragen uns: Stehen hier die strategischen Verlagsinteressen der NZZ etwa über der Recherchequalität?
Argumentationsfutter für das Leistungsschutzrecht?
Wir können die Frage wohl nicht eindeutig beantworten, doch Fakt ist: Der Bundesrat möchte laut Schweizer Verlegerverband im ersten Halbjahr 2025 eine Leistungsschutzrechtvorlage präsentieren, die sich auch zur «KI-Frage» äussern soll.
„Auch durch KI-Systeme werden Auszüge (Snippets) aus journalistischen Inhalte genutzt, ohne die Medien dafür zu entschädigen. Um dieser Entwicklung entgegenzuwirken und die journalistischen Inhalte zu schützen, müssen bestehende Lücken des Urheberrechts konsequent geschlossen werden. Das Leistungsschutzrecht ist also auch eine essenzielle Komponente zur Regulierung von KI-Sprachmodellen.„
Schweizer Verlegerverband
Und die NZZ ist Teil dieses Verbands.
Und bei der Argumentation für ein Leistungsschutzrecht auf KI käme es doch sehr gelegen, wenn sich im Gehirn der Politiker:innen festsetzen würde, dass die KI «irgendwie magisch» technische Schutzmechanismen umgehen könnte.
Obwohl wir jetzt wissen, dass dies nicht so ist.


8 Kommentare
Danke, entlarvend, wie einfach solche Artikel «hinterfragt» werden können.
Eigentlich müsste man die NZZ sogar um eine Gegendarstellung bitten oder noch besser zwingen.
Auch erschreckend, wie wenig Wissen um die Funktion ihrer Paywalls scheinbar sogar bei den entsprechenden Medienhäusern selbst vorhanden sind.
Meinst du das da? 🐘