

User-Tracking im Internet ist seit Jahren ein Dauerbrenner. Es liefert die notwendigen Daten für das Ausspielen von zielgruppengerechter Werbung, es bietet Sicherheitslücken und Angriffsmöglichkeiten, es erlaubt das detaillierte Tracking des Surf-Verhaltens einzelner Benutzer über zig Webseiten hinweg. Kein Wunder, dass es in Form von Tracking- und Ad-Blockern, Cookie-Filtern etc. einige Gegenmittel gibt, Gegenmittel deren Verbreitung in den letzten Jahren stark zugenommen hat. Browser wie Firefox oder Safari verfügen heutzutage sogar in der Grundkonfiguration über einige Einstellungen, welche User-Tracking erschweren oder sogar unterbinden.
Eine Schlüsselrolle in dieser Thematik hat dabei sicher Google inne. Einerseits gehen über 40% des digitalen Werbekuchens von fast 300 Milliarden USD an Google, andererseits mischt man mit Chrome auch auf dem Browser-Markt mit. Die bereits vorletztes Jahr kommunizierte Absicht, die fürs Tracking relevanten 3rd party cookies nicht mehr zu unterstützen, eine Privacy Sandbox einzuführen und fürs Tracking auf eine datenschutz-freundlichere Lösung namens Google FLoC zu setzen, lies daher aufhorchen. Unterdessen liegen Details zum Vorgehen und zur alternativen Lösung vor, eine gute Gelegenheit also, einen Blick draufzuwerfen. Um es gleich vorneweg zu sagen: das Bild welches sich beim Blick zeigt, ist eher ernüchternd.
Wie funktioniert User-Tracking im Internet heute?
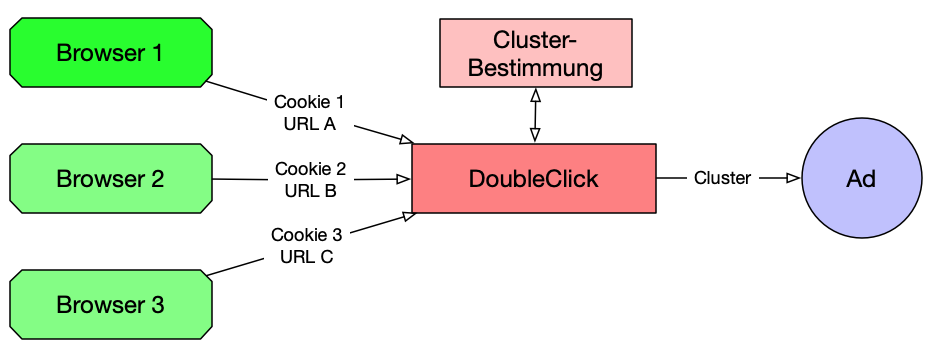
Jede Webseite welche Werbung anzeigt trägt auch zum Tracking der User im Internet bei. Dazu werden in der jeweiligen Webseite Aufrufe (URLs) auf Trackingseiten wie das Werbenetzwerk Doubleclick (gehört zu Google) oder dessen Schweizer Pendant Admeira integriert, bei diesen Aufrufen wird jeweils ein den User identifizierendes Cookie gesetzt bzw. übertragen. Konkreter
- Beim ersten Aufruf einer Webseite wie www.nzz.ch mit eingebettetem Doubleclick-Tracking-Link wird auf Lisas Computer ein zu Doubleclick gehörendes Cookie angelegt. Der Cookie-Wert von z.B. zHE4wYORuC23vJPm identifizert Lisa (bzw. ihren Browser auf diesem Computer) eindeutig
- Bei jedem weiteren irgendeiner Webseite (zB. www.20min.ch) mit eingebettetem Doubleclick-Tracking-Link wird der Cookie-Wert zHE4wYORuC23vJPm vom Browser an Doubleclick geschickt, zusammen mit der vollständigen URL der Seite in welcher der Tracking-Link enthalten ist (also zB www.20min.ch/story/bombenbastler-absolvierte-ausbildung-in-offener-abteilung-407205123957)
Da sich der Wert dieses Cookie also über die Zeit nicht ändert, kann das Werbenetzwerk über den Tracker also erkennen, welche Artikel Lisa Fischer während ihrem Morgenkaffee in der NZZ las, an welchen Schlagzeilen sie am Mittag auf 20 Minuten hängenblieb und für welche Artikel sie am Abend bei einem grossen Online-Händler aktiv war. Diese Surf-History ergibt über die Zeit ein recht gutes Bild über die Interessen eines Users, für das zielgruppengerechte Platzieren von Werbung werden User mit ähnlicher Surf-History in Clustern zusammengefasst über welche dann Werbung ausgespielt werden kann. Aufgrund ihrer Lese- und Artikel-Interessen landet Lisa Fischer hier nun vielleicht im Cluster „jung, weiblich, politisch konservativ, konsumfreudig“, für Werbetreibende mit entsprechenden Produkten also eine ideale Kundin. Ob Doubleclick (oder eines der anderen Tracking-Netzwerke) die gesammelten Daten auch noch für andere Zwecke nutzt, ist zumindest unklar.
Noch besser (und das erklärt zum Beispiel wieso die Schweizer Verleger seit geraumter Zeit ihre Webseiten-Besucher mehr oder weniger aggressiv zu einem Login überreden wollen) ist es natürlich, wenn man diese nach wie vor anonymen Cookies mit weiteren identifizierenden Daten abgleichen kann. Im Vorteil sind da sicher Anbieter wie Facebook und Google, da viele User auf beiden Plattformen einen Account haben und so ein einfacher Abgleich der Cookies mit den Account-Daten möglich ist. Entsprechend wertvoller (und für den Werbenden teurer) sind dann Ads welche unter Nutzung solcher User-Trackings ausgespielt werden können.
Wie funktioniert Google FLoC?
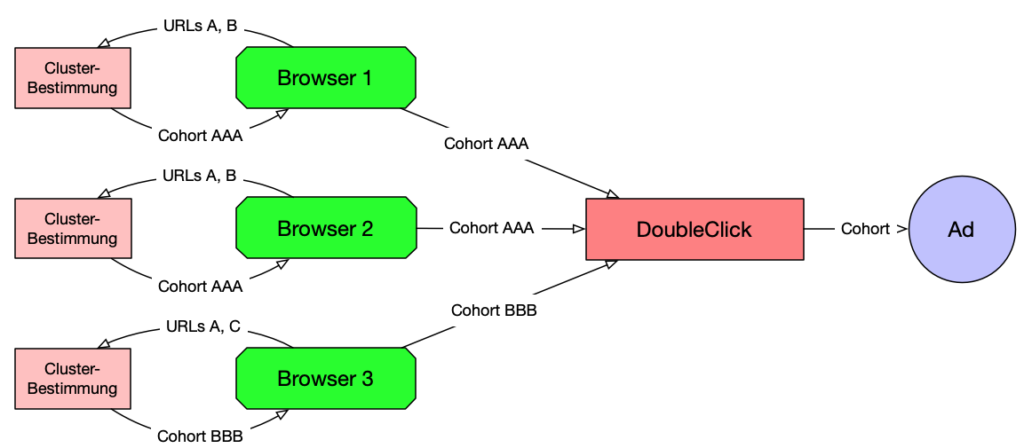
FLoC steht für „Federated Learning of Cohorts“, erfreulicherweise hat Google einige Dokumente veröffentlicht, welche ihre Ideen zu einem datenschutz-freundlicheren User-Tracking beschreiben (insbesondere hier und hier). Es gibt sogar ein Github-Repository mit einer etwas technischeren Beschreibung. Vereinfacht gesagt geht es darum, das Clustering von individuellen Benutzern (welches heute wie beschrieben bei den Tracking-Unternehmen vorgenommen wird) direkt im Browser zu erledigen (Google nennt die Cluster Cohorts). Wie schon beim Ad Targeting via Cookie-Informationen werden hier also Personen mit vergleichbarer Webhistory zu Gruppen zusammengefasst.
Nach heutigem Wissensstand erfolgt dieses Clustering auf Basis der in den letzten Tagen besuchten Webseiten, ist also relativ grob (aus dem Umstand, dass ich jeden Tag die Webseite desselben Online-Anbieters besuche, lassen sich noch keine spezifischen Produktinteressen ableiten). Es ist zu erwarten, dass Google hier noch experimentieren wird um die Aussagekraft des Clusters zu verbessern. Konkret erwähnt werden im FLoC-Grundlagendokument
- Verwenden der besuchten Sites (also www.nzz.ch)
- Verwenden der vollständigen URLs (also https://www.nzz.ch/schweiz/kantonale-handelskammern-setzen-den-bundesrat-unter-druck-um-den-eu-rahmenvertrag-abzuschliessen-ld.1612873)
- Kategorisieren von Seiten aufgrund von Logik innerhalb des Browsers (also „News“, oder „News/Schweiz“)
sowie, bisher ohne weitere Details, Lernmodelle welche aufgrund des bisherigen Nutzerverhaltens dessen zukünftiger Clustercode voraussagen sollen.
Der so ermittelte Cluster-Code kann dann innerhalb der Webseite mittels JavaScript abgefragt und zum Ausspielen von Werbung verwendet werden. Jeder User (bzw. jeder Browser) hat dabei jeweils zu einem Zeitpunkt genau einen Cluster-Code welcher das Surfverhalten der letzten Tage abbildet. Google beabsichtigt diesen Cluster-Code regelmässig (z.B. wöchentlich) neu zu bestimmen, damit er sich an sich änderndes Surfverhalten des Benutzers anpasst.
Nehmen wir nochmals Lisa Fischers Tagesablauf zur Hilfe:
- Sie liest zum Morgenkaffee einige NZZ-Artikel. Deren URLs werden von Chrome auf Lisas Computer gespeichert
- Sie blättert über Mittag durch den neusten Klatsch auf 20min. Auch hier werden die besuchten URLs von Chrome gesammelt
- Am Abend sucht sie auf dem Online-Händler ihres Vertrauens nach einem neuen Snowboard, natürlich werden auch hier die URLs gesammelt.
Auf Wochenbasis wird aus den so gesammelten URLs ein Cluster-Code gebildet, dieser kann dann durch den Programmcode der Webseite abgefragt und für die Auswahl von Werbung verwendet werden. Die besuchten URLs bleiben den Werbetreibenden dabei verborgen, was auf den ersten Blick den Datenschutz deutlich stärkt. Dieses Argument streicht Google in all seinen Dokumenten am Thema immer wieder und wieder heraus. Schon auf den ersten Blick wird aber klar, dass hier vor allem die algorithmische Hoheit über die Clusterbildung (die hell-rote Box) von den Werbetracking-Sites zu Google verschoben wird.
Genauer betrachtet wirkt Googles Argumentation des erhöhten Datenschutz‘ aber auch aus anderen Gründen etwas allzu dreist.
Google FLoC gut, alles gut?
Vereinfacht gesagt: Schön wär’s, aber leider nicht. Warum?
- Bereits heute werden User nicht mehr nur über Cookies identifiziert sondern auch über sogenannte Browser-Fingerprints. Dabei wird die Tatsache ausgenutzt, dass die Kombination von Browser-Typ und -Version, Fenstergrösse, Zeitzone, Liste der unterstützten Fonts und weiterer Attribute einen Benutzer unter Umständen eindeutig identifiziert (bei einem Test mit dem entsprechenden Tool der EFF wurde mein Browser als „appears to be unique among the 294,253 tested in the past 45 days.“ erkannt. Nun gibt es natürlich Milliarden von Internet-Nutzenden in der Welt, daher wird mit Fingerprinting oft keine eindeutige Identifikation möglich sein. Aber der von FLoC generierte Cluster-Code stellt ein weiteres Identifikationsmerkmal jedes Browsers dar, die Möglichkeit der eindeutigen Identifikation steigt damit sogar an!
- Während bei Verwendung von 3rd party cookies die generierte Cluster-Zuordnung nur den Werbeanbeitern als Platzierungsparameter zur Verfügung steht, kann im Fall von Google FLoC auch die Webseite selbst (also zB die NZZ oder 20min) auf den Cluster-Code zugreifen. Dadurch kann sie einen Abgleich zwischen den besuchten Seiten und dem Cluster-Code vornehmen und mit der Zeit Rückschlüsse auf die Bedeutung des Clusters machen (also zum Beispiel erkennen, dass Cluster-Code 0xAC12 häufig junge Frauen mit Interesse für Schweizer Politik und Cluster-Code 0x93FC eher ältere Männern mit Interesse für Sport enthält). Mit diesen Informationen kann die Zeitung bei neuen Seitenbesuchern (die ja bereits einen via Google FLoC berechneten Cluster-Code haben) dann von vorherein mit einer gewissen Wahrscheinlichkeit auf deren Interessen schliessen. Je nach Cluster-Grösse und Nutzung sonstiger Merkmale kann das bis zu einer individuellen Identifikation führen
- Noch einfacher wird es, wenn die Seite einen personalisierten Login anbietet. Das vereinfacht primär schon mal die Zuordnung von Cluster-Codes zu klar definierten Benutzermerkmalen aus dem Account. Darüber hinaus erlaubt es auch, Veränderungen im sich wöchentlich ändernden Cluster-Code eindeutig einem Login zuzuordnen und so ein Tracking über mehr als eine Woche aufrechtzuerhalten. Da kann man dann schon mal aus dem Umstand, dass der bisher als „junger Mann mit Interesse an Parties und schnellen Autos“ klassifizierte Nutzer neu als „junger Mann mit Interesse an Innenausstattung und Babykleidern“ daherkommst, schliessen, dass sich hier im Privatleben etwas geändert hat. Und dann zum Beispiel Werbung/Inhalte konkret auf diesen Umstand hin platzieren (also vielleicht Werbung welche zu einer Verkaufsplattform für das jetzt nicht mehr benötigte schnelle Auto führt)
- Der userseitige Opt-Out könnte, zumindest wenn man mit Chrome im Internet unterwegs ist, schwieriger werden als heute. Die Problematik von Tracking-Links ist heute vielen bewusst, entsprechend sind Plugins wie uBlock Origin oder Ghostery recht verbreitet. Bei einer innerhalb des Browsers angesiedelten Funktion zur Cluster-Bildung ist dies ungleich schwieriger. Defacto ist man darauf angewiesen, dass Google eine entsprechende Option anbietet (oder man steigt auf einen anderen Browser um).
- Sinnvollerweise (und das sieht Google auch so vor) steht der Cluster-Code nicht zur Verfügung wenn man den Inkognito-Modus benutzt, schliesslich will man im Inkognito-Modus möglichst wenige Spuren hinterlassen und auch nicht identifizierbar sein. Nur: man will ja auch nicht, dass eine Webseite überhaupt erkennt, dass man momentan inkognito unterwegs ist (weil sie einem dann zum Beispiel andere Inhalte anzeigen oder Zugang zu gewissen Teilen verbergen könnte). Wie kann Google also im Inkognito-Modus mit dem Cluster-Code umgehen, ohne gleichzeitig preiszugeben, dass sich der Browser in diesem befindet?
- Falls die FLoC-Funktion einen Zufallswert zurückgibt, reichen zwei Aufrufe derselben (gleiches Ergebnis -> normal, unterschiedliches Ergebnis -> inkognito)
- Falls die FLoC-Funktion einen konstanten Wert zurückgibt, ist eine Teilidentifikation des Browsers auch im Inkognito-Modus möglich
- Falls die FLoC-Funktion im Inkognito-Modus schlicht fehlt, kann die Webseite die Fehlermeldung beim Aufruf auswerten
Was heisst das nun?
Es war von Anfang an mutig von Google, als Hauptprofiteur des globalen Internet-Werbekuchen einen neuen Weg für das Tracking vorzuschlagen. Zu nahe liegt die Vermutung, dass Google mit FLoC primär sich selbst bevorteilen wird, werden durch den Verzicht auf 3rd party cookies doch primär alle übrigen Werbeanbieter von Detailinformationen abgeschnitten und müssen sich neu mit den von Google aufbereiteten Cluster-Daten zufriedengeben. Auf den ersten Blick wirken die Spiesse aller Werbeanbieter dann zwar gleichlang, defacto verlieren die Google/Doubleclick-Konkurrenten (also all die Unternehmen welche, siehe ganz am Anfang, die übrigen 60% des globalen Internetwerbekuchens ausmachen) aber mögliche Alleinstellungsmerkmale da sie ja keinen Zugriff mehr auf Rohdaten (besuchte URLs) haben und keine eigene Clusterbildung vornehmen können.
Auch war und bleibt es unwahrscheinlich, dass Apple/Safari und Mozilla/Firefox mit ihrem starken Fokus auf User-Privacy bereit sind, neue Tracking-Funktionalitäten in ihre Produkte einzubauen, und sich erst noch in eine nur teilweise analysierte Abhängigkeit zu Google zu begeben.
So erscheint die Google FLoC-Initiative als Versuch, das einträgliche Geschäftsmodell der gezielt platzierten Internet-Werbung in eine Zeit zu retten in welcher der durchschnittliche Internet-Benutzer gegenüber dem Tracking im Internet kritischer eingestellt ist. Und, man darf ja noch hoffen, vielleicht führt die ganze Diskussion um Google FLoC früher oder später dann doch mal zu einer Diskussion über den Bedarf von gezielt platzierter Werbung und deren Nachteile für die Nutzer an sich.
PS: Das Internet stand während dem Schreiben des Artikels nicht still, und es gibt bereits eine Reihe von Möglichkeiten, sich gegen FLoC zu wehren
- DuckDuckGo bietet ein Plugin zum Blockieren von FLoC an
- Sofern man Chrome nicht mit Firefox ersetzen will oder kann, hat man mit Vivaldi und Brave zwei Chromium-basierte Alternativen welche die FLoC-Funktionalität nicht enthalten werden.
- Chrome-Benutzer haben mit diesem EFF-Tool die Möglichkeit zu prüfen ob die Funktionalität bei ihnen bereits aktiviert wurde.
- WordPress-Betreiber können mit einem Plugin verhindern, dass der Seitenbesuch in die für FLoC relevante URL-History aufgenommen wird
- Dasselbe können auch alle anderen Webseiten-Betreiber erreichen indem sie den entsprechenden Header im HTTP-Request setzen.
Korrigenda
- In der ersten Version des Artikels wurde das FLoC-Repository auf Gitlab beschrieben, das Repository befindet sich allerdings auf Github. Der Link war korrekt, die Beschreibung wurde korrigiert


2 Kommentare
Feiner Text. Meine Fragen, die vielleicht auch noch weitere Lesende interessieren könnten:
1.) Wenn die Kohorten dann auf Basis einiger Tage gebildet werden und Google aber stets Anpassungen macht, wie kann die Kohorten dann „verbessert“ werden? Wendet dann Google/Chrome trotz selbstauferlegter zeitlicher Limite (für die Speicherung der URLs von wenigen Tagen) dennoch Machine Learning an?
2.) Was bedeuten die FloC-Kohorten für die installierten FB Pixel und -Tracker und wenn ich FB/Google-Login/Authentifzierung NICHT nutzen will andere Webseiten? Welche Daten kann FB dann zurückgewinnen für die personalisierte Werbung auf der Plattform?
Zu 1) Es gibt eine ganze Reihe von Dokumenten dazu (zB https://github.com/WICG/floc und https://github.com/WICG/floc/issues/58), diese (er)klären das aber nicht abschliessend (nicht unbedingt weil Google etwas verheimlichen möchte sondern weil man schlicht noch am Experimentieren ist). Grundsätzlich sollte die Semantik/Bedeutung einer Kohorte über die Zeit stabil bleiben, sonst könnten Werbeanbieter die Kohorten-ID ja nicht fürs Adressieren von Werbung verwenden. Google selber sagt aber momentan klar, dass die Algorithmen zum Bestimmen der Kohorte noch im Fluss sind, und empfiehlt die Kohorten-ID immer in Kombination mit der Version des im Browser implementieren Berechnungsmodels zu verwenden. Der aktuelle Algorithmus verwendet die URL (bzw. den Domain-Namen) der besuchten Seiten, in den Unterlagen finden sich auch Hinweise auf Kohorten-Bestimmung basierend auf den Inhalten der besuchten Seiten. Dazu müssten lokal (im Browser) dann vermutlich ML-Algorithmen zum Einsatz kommen.
Zu 2) Mit dem Unterdrücken von 3rd party cookies funktionieren FB-Pixel/Tracker in Webseiten ausserhalb des FB-Universums nicht mehr, entsprechend auch nicht mehr wenn Google Chrome sie gar nicht mehr unterstützt. Die Möglichkeit zu personalisierter FB-Werbung basierend auf Surf-Verhalten ausserhalb FB ist dadurch sicher eingeschränkt, ich würd aber davon ausgehen dass sich FB da schon die eine oder andere Alternative überlegen wird um trotzdem an mehr Daten ranzukommen. Und natürlich kriegt es FB weiterhin mit wenn man auf Drittseiten mit dem FB-Login einloggt (und kann dabei vermutlich auch die Kohorte abfragen, aber bei einem Login ist man prinzipbedingt nicht anonym).
Zu personalisierter Werbung gibt es im FLoC-Umfeld einen weiteren Vorschlag (https://github.com/WICG/turtledove/blob/main/FLEDGE.md) bei dem Webseiten quasi deklarieren, welche Interessengruppen sie adressieren, und Browser sich für diese Interessensgruppen registrieren können. Ich hab das verlinkte Dokument nur überflogen, aber offenbar ist dann die Idee dass Werbeanbieter in ihren Ads solche Interessengruppen adressieren und der Browser dann entscheidet, welche spezifische Werbung angezeigt werden soll.