

In den 1½ Wochen seit Publikation der ersten beiden Teile hat sich einiges getan. Microsoft liess es sich nicht nehmen, die Schuld am Vorfall der EU in die Schuhe zu schieben, wie das Apple mit ihrer KI ja auch schon frech versuchte. Andererseits haben die Diskussionen zum Vorfall viele Hinweise darauf gegeben, wie IT-Verantwortliche ihre Systeme zukünftig sicherer und ausfallsicherer zu gestalten. Hier erklären wir die Massnahmen, die sie treffen sollten und die Fragen, die sie stellen sollten.
Dies geht uns alle an. Weil unsere IT-Systeme zu unverzichtbaren Schlagadern unseres Lebens geworden sind. Und ihr Ausfall unsere Wirtschaft, unser Privatleben und unsere Gesellschaft unwiederbringlich schädigt.
Dies ist Teil 3 der CrowdStrike-Serie. Wer die letzten beiden Wochen auf einer einsamen Insel verbracht hat, findet die ersten beiden Artikel mit Hintergründen, Zusammenfassungen und Empfehlungen hier:
Teil 1: «CrowdStrike oder: Wie eine Closed-Source-Firma fast die Welt lahmlegte»
Teil 2: Wie können wir ein zweites «CrowdStrike» vermeiden?
Updates an den beiden bisherigen DNIP-Artikeln
Wer die ersten beiden CrowdStrike-Artikel vorbildlich kurz nach der Veröffentlichung gelesen hat, hat zwei wichtige Updates an den Artikeln verpasst. Kein Problem, die kann man ganz einfach nachholen:
[neu 2024-08-07] CrowdStrike hat ihre finale Analyse veröffentlicht. Fazit: Das Dateiformat wurde nicht genügend überprüft. Damit das nicht mehr auftritt, wird jetzt u.a. mehr getestet, auch bevor ein neues Erkennungsmuster ausgerollt wird. Dies sind wichtige Schritte in die richtige Richtung (siehe u.a. meine Bemerkungen zum Testen.)
Wie kam es zu diesem Problem mit dem Dateiformat? Seit Februar konnten Erkennungsmuster — mit denen die CrowdStrike-Software bösartige Aktivitäten auf dem Rechner zu erkennen versucht — neu ein zusätzliches, optionales 21. Datenfeld haben (davor waren es maximal 20). Am 19. Juli wurde per Zwangsupdate das erste Mal eine Regel für ein Erkennungsmuster verteilt, welche auf Informationen in diesem 21. Datenfeld zugreifen wollte. In der Datei mit den Erkennungsmustern waren aber nur 20 Felder definiert. Der Zugriff auf das 21. Datenfeld führte deshalb „ins Leere“ und verursachte den bekannten Absturz.
Ist die EU schuld?
Zwei Tage nachdem CrowdStrike über 8 Millionen Windows-Firmenrechner weltweit lahmlegte, schrieb das Wall Street Journal:
A Microsoft spokesman said it cannot legally wall off its operating system in the same way Apple does because of an understanding it reached with the European Commission following a complaint. In 2009, Microsoft agreed it would give makers of security software the same level of access to Windows that Microsoft gets.
Auf Deutsch etwa: «Ein Microsoft-Sprecher sagte, Microsoft seien rechtlich die Hände gebunden, sein Betriebssystem gleich gut abzuschotten wie Apple. Dies wegen einer Einigung, die Microsoft nach einer Beschwerde mit der EU-Kommission erzielte. 2009 hätte Microsoft zugestimmt, dass es Herstellern von Sicherheitssoftware dieselben Zugriffsmöglichkeiten auf Windows ermögliche, wie es sich selber gäbe.»
Zitat aus: Blue Screens Everywhere Are Latest Tech Woe for Microsoft von Tom Dotan und Robert McMillan, Wall Street Journal, 2024-07-21.
Macht die Behauptung Sinn?
Nehmen wir diese Aussage erst einmal für bare Münze: Microsoft könne den Windows-Betriebssystemkern nicht besser schützen, weil es Drittherstellern von Sicherheitsprodukten dieselben Funktionen offenlegen müsse, wie es selbst nutze.
- Eine solche Aussage wäre noch lange kein Versprechen, die Funktionen nicht irgendwann sicherer machen zu dürfen. So lange gleich lange Spiesse gewahrt bleiben. So hätte Microsoft eine Betriebssystemschnittstelle vorsehen können, welche Sicherheitssoftware von Dritten die Möglichkeit gegeben hätte, nach verdächtigen Aktivitäten zu horchen und evt. sogar diese zu unterbinden. Dies machen Apple mit ihrem Endpoint Security Framework oder Linux u.a. mit der modernen eBPF-Schnittstelle, auf der fast alle Cloud-Security-Produkte aufsetzen (siehe Kasten weiter unten) mit Erfolg.
- Wenn Microsoft damals (oder später; sie liessen sich ja über ein Jahr Zeit, wie wir weiter unten noch erfahren werden) eine geeignet abstrahierte Schnittstelle angeboten hätte, wäre dieser Schritt nicht nötig geworden.
- In den Nullerjahren war es für Softwarehersteller noch gang und gäbe, eigene Kernelmodule zu schreiben, die dann tief ins Betriebssystem eingriffen: Für Sicherheitsfunktionen, aber auch für Dateisysteme oder Gerätetreiber uvam., sowohl für Windows, MacOS als auch Linux.
- Falls Microsoft irgendwann—aufgrund dieser Einigung—konkret Angst um die Stabilität seines Betriebssystems gehabt hätte: Wieso haben sie dann nicht zumindest das Gespräch mit der EU-Kommission gesucht?
- In der Zwischenzeit haben wir viel gelernt: Minimierung dessen, was im Betriebssystemkern selbst abläuft. Und vor allem: Wie sorgen wir dafür, dass möglichst nur noch fehlerfreier Code zu den Nutzer:innen kommt.
Es hätte also keinen Grund für Microsoft gegeben, die Situation nicht schon damals (oder dann aber in den 1½ Jahrzehnten dazwischen) zu verbessern. Oder das zumindest zu versuchen. Dafür gibt es aber keine Hinweise.
Das ist aber nur die halbe Wahrheit. Wenn überhaupt.
Zum Glück gibt es Leute, die sich noch an diese Nullerjahre erinnern können, wenn auch mit etwas Nachforschen im eigenen Artikelarchiv. Genau das hat Paul Thurrott getan: Er hat sich auf die Suche nach dieser angeblichen EU-Microsoft-Einigung aus 2009 gemacht.
Und sie nicht gefunden. Dafür Artikel von ihm aus 2006 und 2007 (damals erschienen in Papierform), in denen er über die damaligen Antitrust-Verhandlungen des Windows-Konzerns gefunden. Zur Erinnerung: Damals war Microsoft auf dem PC-Markt so dominant wie Google inzwischen im Werbemarkt ist.
In einem grossartigen Artikel zerlegt Paul Thurrott die Microsoft-Anschuldigung mit zeitgenössischen Aussagen:
- Es ging nicht um Kernelmodule an sich (die mutmassliche Ursache dieses Fehlverhaltens). Die Frage war, ob Kernelmodule nicht nur zusätzliche Funktionen hinzufügen sollen (wie z.B. die Ansteuerung einer Sound- oder Netzwerkkarte), sondern ob sie bereits existierende—von Microsoft vorgegebene—Funktionalität einfach so verändern dürften.
- Microsoft hatte damals seine dominante Stellung an verschiedener Stelle ausgenutzt (Internet Explorer als Standardbrowser vorgegeben, seine eigene Suchmaschine vorbelegt, …) und war deshalb unter Druck. Dann kam eine Bitte der Sicherheitssoftwarehersteller, dass die für die neuen 64-Bit-Prozessoren vorgesehenen Sicherheitsfunktionen (Unterbinden der Veränderung bestehender Funktionalität im Kernel) nicht nur für Microsoft umgehbar zu machen.
- Microsoft kam selbst mit dem (dann 2007 umgesetzten) Vorschlag. Natürlich wussten sie, dass ein einfaches Microsoft-„Nein!“ in der angespannten Situation nicht akzeptiert worden wäre. Aber es hätte sicher auch andere Optionen gegeben.
- In den Release Notes zur Service Pack 1 von Windows Vista, der ersten Version, welche diese neue Möglichkeit vorsah, war folgender Text zu finden:
Service Pack 1 includes supported APIs by which third-party security and malicious software detection applications can work alongside Kernel Patch Protection on 64-bit versions of Windows Vista. These APIs have been designed to help security and non-security ISVs develop software that extends the functionality of the Windows kernel on 64-bit systems, in a documented and supported manner, and without disabling or weakening the protection offered by Kernel Patch Protection.
Auf Deutsch etwa: «Mit Service Pack 1 unterstützen wir neu Software-Schnittstellen (API), mit welchen Dritthersteller Sicherheits-Software und Software zur Erkennung von bösartiger Software auch mit der Kernel Patch Protection von 64-Bit-Versionen von Windows Vista zusammenarbeiten können. Diese APIs wurden so gestaltet, dass unabhängige Softwarehersteller aller Art die Funktionalität des Windows-Kernels auf 64-Bit-Systemen erweitern können. Und zwar auf eine dokumentierte und unterstützte Weise, ohne den Schutz der Kernel Patch Protection zu deaktivieren oder abzuschwächen.»
Microsoft: Notable Changes in Windows Vista Service Pack 1, 2007.
Microsoft hatte damals den eigenen Vorschlag umgesetzt und ihn 2007 auch als sehr sichere Lösung angepriesen. Die Aussage des Microsoft-Pressesprechers von letzter Woche ist also völlig aus der Luft gegriffen. Microsoft sah diese Option damals nicht als Einschränkung der Sicherheit und hatte die Umsetzung selbst gewählt.
War Microsoft schuld?
Eine andere These, die schnell einmal auftauchte: Fühlt sich Microsoft eigentlich (mit-)schuldig an den CrowdStrike-Ausfällen? Immerhin hat Microsoft eine (auch von CrowdStrike verlinkte) ausführliche Recoveryanleitung geschrieben und diverse automatisierte Tools für das Recovery der lahmgelegten Windows-Rechner veröffentlicht.
Bisher wissen wir noch zu wenig, was die genaue Absturzursache war, auch wenn sowohl CrowdStrike als auch Microsoft erste Einblicke veröffentlicht haben.
Die Erklärung dürfte vermutlich aber viel einfacher sein: Viele der CrowdStrike-Kunden dürften auch gute bis sehr gute Kunden von Microsoft sein; schliesslich war da auch mindestens eine Firma mit 150’000 Windows-Rechnern betroffen. Und Microsoft kennt den genauen Ablauf des Windows-Bootprozesses sowie alle Tricks darum herum wohl besser als die meisten anderen Firmen, CrowdStrike und andere Sicherheitsfirmen inklusive.
In so einem Fall würde ich als Entscheidungsträger bei Microsoft keine Sekunde zögern und sofort eine möglichst benutzerfreundliche Hilfestellung für meine besten Kunden zusammenstellen.
Also wahrscheinlich einfach eine gute Businessentscheidung, ganz im Sinne der einfachsten Erklärung («Occam’s Razor»).
Sind die Ratingagenturen schuld?
Wieso aber haben Firmen Abermillionen von CrowdStrike-Falcon-Lizenzen gekauft und installiert? Dafür gibt es mehrere Gründe:
- Ratingagenturen wie Gartner «empfehlen» das Produkt.
- Kaum jemand kann die Sicherheit eines Produkts wirklich beurteilen; weder Analysten noch Kunden.
Die Rolle der Ratingagenturen
Wenn es um IT-Lösungen geht, ist Gartner die Agentur, die vielen als Erste in den Sinn kommt, wenn sie eine Marktübersicht zu einer Produktkategorie suchen. Auch 14 Tage nach dem CrowdStrike Millionen von Rechnern crashen liess, listet Gartner CrowdStrike Falcon (gemeinsam mit SentinelOne Singularity Platform) mit der höchsten Bewertung auf, 4.7 Sternen. Keine einzige negative Bewertung oder sonstige Anmerkung.
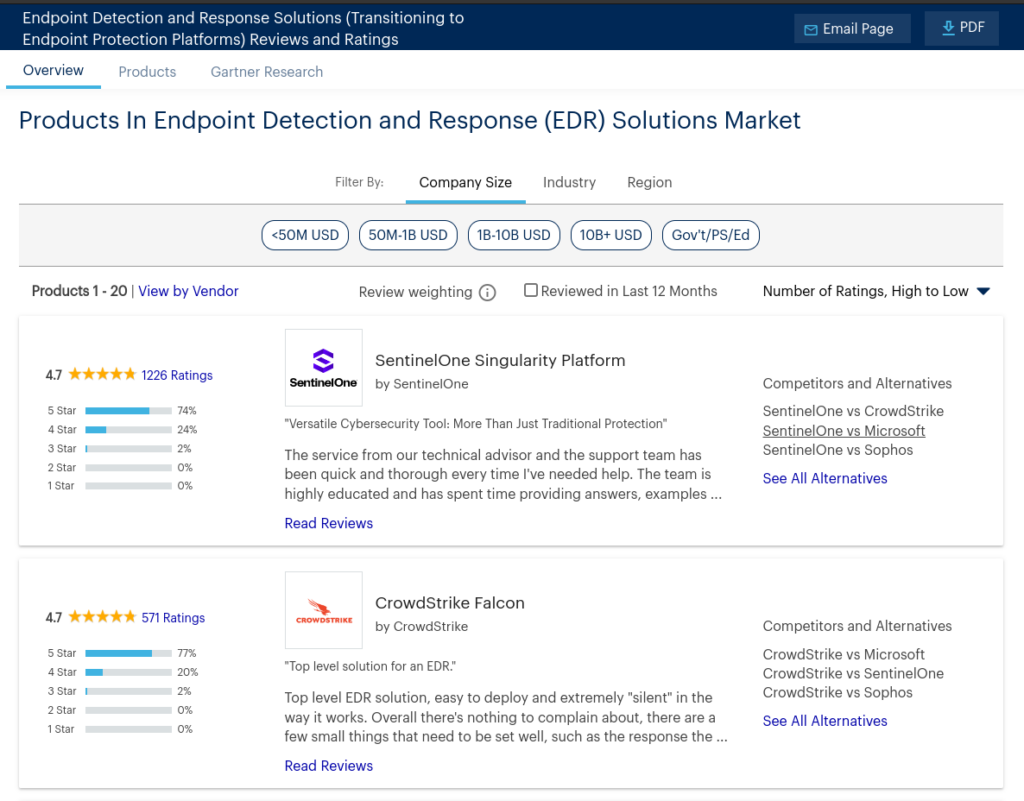
Fehlende Aktualität oder Vernachlässigung von Risiken hat für Gartner keine Auswirkungen, da sie sich darauf beruhen, dass ihre Bewertungen nur «pure opinion» seien, also nur eine unverbindliche Meinungsäusserung und keine Empfehlung. Viele Kunden und sonstige Leser fällen aber darauf Entscheidungen.
Bewertungen sind immer auch ein bisschen Glückssache, wie es auch bei Finanz-Ratingagenturen bekannt ist, spätestens seit dem Bankencrash vor gut 15 Jahren, bei dem Ratingagenturen ähnlich wie mittelalterliche Alchemisten Blei zu Gold gemacht hätten.
Bewertung ist schwierig — Sicherheitsbewertung doppelt
Ja, zuverlässige Bewertungen sind nicht einfach. Wohl alle kennen den Fall aus ihrer Schul- oder Ausbildungszeit, wo sie dachten, sie hätten eine bessere Note verdient. Aber Lehrer:innen haben es noch relativ einfach: Sie müssen nur den aktuellen, nach aussen gezeigten Wissensstand beurteilen.
Bei IT-Sicherheit muss man aber hinter die Kulissen blicken. Und in die Zukunft blicken können: Wie wahrscheinlich ist es, dass uns das mal auf die Füsse fällt? (Und es kann uns auf tausend verschiedene Arten auf die Füsse fallen!)
Entsprechend entstehen viele Ratings auf Basis von Äusserlichkeiten: Wie einfach ist es zu bedienen? Wie gut passt es für meinen Anwendungszweck? Wie nett und kompetent sind die Verkäufer auf der anderen Seite?
Oder wie es der CEO von Delta, der am stärksten in Mitleidenschaft gezogenen Fluggesellschaft ausdrückte: Das ganze Umfeld der Tech-Giganten sei nur auf Wachstum ausgelegt, nicht auf Dienst am Kunden.
Falsche Prioritäten bei CrowdStrike?
Berichten zufolge hat CrowdStrike im letzten Jahr viele Ingenieure und Leute aus der Qualitätssicherung verloren (u.a. weil diese den z.T. sehr langen Weg ins Büro nicht (wieder) auf sich nehmen wollten). Vermutlich war das aber nicht die Hauptursache.
Fehlende Softwarequalität (oder in anderen Fällen mangelnde IT-Sicherheit) ist nur selten das Resultat einer einzelnen Aktion eines einzelnen Mitarbeiters. In den allermeisten Fällen herrscht ein Klima, das Verbesserung von Softwarequalität oder IT-Sicherheit nicht fördert oder sogar aktiv hemmt.
Dass Autos bei 120 km/h spontan auseinander fallen oder Brücken und Gebäude einfach so einstürzen ist in unseren Breitengraden zum Glück eine Seltenheit. Das war aber nicht immer so, sondern ist die Folge von etlichen „Sicherheitsnetzen“, die in den letzten Jahrzehnten und Jahrhunderten eingeführt wurden: Von Planung, Design, Herstellung bis Service. Diese Sicherheitsnetze fehlen in der IT häufig.
Die Verantwortung des Managements bei IT-Vorfällen
Grössere IT-Sicherheitsvorfälle wie Datenklau oder Ransomwareangriffe beruhen häufig darauf, dass die IT-Infrastruktur ungenügend geschützt war; dass genau diese grundlegenden Sicherheitsnetze fehlten.
Ob es diese Sicherheitsnetze gibt und wie gut sie sind, ist vor allem eine Managemententscheidung. Bei IT-Sicherheitsvorfällen sollte deshalb immer auch die Rolle des Management und des von ihm geschaffenen IT-Sicherheitsklimas genau betrachtet werden.
Die Ziele des CrowdStrike-Managements
Wenn wir uns die letzten 5 Jahre ansehen, ist im Rückblick eine klare Expansionsstrategie zu auszumachen, eine vor 5 Jahren 1500 Personen umfassende Firma zuerst an die Börse zu bringen und durch Akqusitionen in den S&P 500 aufgenommen zu werden:
- 2019: Börsengang an der Nasdaq
- 2020: Kauf von Preempt Security
- 2021: Kauf von Humio und SecureCircle
- 2023: Kauf von Bionic.ai und Kollaboration mit Cribl.io
- 2024: Kauf von Flow Security und Aufnahme in S&P 500
Eine Entwicklung der Mitarbeiterzahl von rund 1500 (2019) zu knapp 8000 (2024) absorbiert viel Zeit im Management, die sich um allerlei Integrations- und Wachstumsschmerzen kümmern müssen. Da kann es dann gut passieren, dass der Fokus auf Sicherheit und Stabilität verloren geht, wenn plötzlich neue Akquisitionen und neue Features Priorität haben.
Ein rasches Wachstum einer Firma muss also nicht unbedingt ein gutes Zeichen sein.
Vorwurf der Falschaussagen
Der CEO von CrowdStrike hatte vor wenigen Monaten die eigene Software als «validated, tested, and certified» bezeichnet («geprüft, getestet und zertifiziert»). Auf Basis dieser Aussage wollen nun einige Aktionäre eine Sammelklage starten. Es geht nicht um den Schaden, den die CrowdStrike-Falcon-Kunden davon getragen haben, sondern um den Kursverlust, den die Aktionäre ausbaden müssen.
Das ist definitv ein interessanter (und in den USA bei börsenkotierten Firmen beliebter) Ansatzpunkt. Er geht aber in die falsche Richtung. Es wird irgendwo irgendwelche Prüfungen, Tests und Zertifizierungen geben. Und darauf wird es wohl beim Gerichtsverfahren hinauslaufen.
Das wahre Problem ist aber, dass «irgendwelche» Papiere nicht ausreichen. Die Tests müssen genügend gut sein. Und da hilft es nicht, ob diese eine Aussage belegbar ist oder nicht.
Eigentlich müsste untersucht werden, ob sich die Firma genügend um die Qualitätssicherung gekümmert habe. Aber das dürfte viel schwieriger nachzuweisen und einzuklagen sein.
«Schuld war DOCH der Linux-Kernel!»
Kasten: Betriebssysteme, Kernelmodule und Abstürze [neu 2024-08-08]
Normale Abstürze von Programmen sind zwar unerfreulich, ihre Auswirkungen beschränken sich aber meist darauf, dass die Arbeit der letzten Minuten oder Stunden verloren ist. Ein Absturz des Betriebssystemkernels selbst ist schlimmer, er bedingt einen Reboot des gesamten Rechners. Noch eine Stufe schlimmer ist, wenn das Betriebssystemkernels jesemal beim Booten reproduzierbar abstürzt, weil dann auch der Reboot das Problem nicht löst.
Das Risiko eines Betriebssystemabsturzes kann man auf verschiedene Arten reduzieren:
- Die Anzahl Funktionen im Betriebssystemkern zu reduzieren (z.B. Microkernelarchitektur; gibt es in Reinform aber in keinem verbreiteten Betriebssystem)
- Als abgeschwächte Form davon: Möglichst viel Funktionalität aus dem Kernel in ein „normales Programm“ auszulagern
- Bei der Softwareentwicklung auf Einfachheit zu achten („KISS-Prinzip„)
- Bei der Software Fehler zu vermeiden (Code-Review, Pair Programming, 4-Augen-Prinzip; testen, testen, testen)
Bei der Betriebssystementwicklung wird deshalb auf möglichst einfachen und gut getesteten Code geachtet. Und man versucht die Funktionen im Betriebssystemkernel zu minimieren und komplexe Entscheidungen in „normale“ Programme auszulagern. Wenn die Aufgaben geschickt aufgeteilt werden, ist der Code im Kernel so klein und so gut getestet, dass er nie abstürzt. Und die Aufgabenteilung zwischen Kernel und der Steuerungsanwendung so organisiert, dass die Steuerungsanwendung abstürzen kann und der Rest des Systems weiter funktioniert, wenn auch evt. mit reduzierter Funktionalität.
Insbesondere von Drittanbietern entwickelte Kernelmodule sind den Betriebssystementwicklern schon länger ein Dorn im Auge, da sie die Komplexität erhöhen, meist schlechter getestet werden wie der Kernel selbst und bei Updates Kompatibilitätsprobleme verursachen können. Der CrowdStrike-Vorfall wird diese Vorurteile weiter zementieren.
Gesucht war also die eierlegende Wollmilchsau als Lösung des Dilemmas: Wie können bestehende Funktionen des Betriebssystems ohne zusätzliche Kernelmodule von Drittanbieter dynamisch überwacht, eingeschränkt oder verändert werden?
Kasten: eBPF als Lösung des Dilemmas [neu 2024-08-08]
Seit Jahrzehnten hatten Betriebssysteme wie Linux und MacOS schon ein leicht anderes Problem gelöst: Wie können Netzwerkpakete, beispielsweise bei einer Firewall, flexibel behandelt werden? Also dynamisch überwacht, eingeschränkt oder weitergeleitet werden?
Entstanden war eine Art Programmiersprache, der sogenannte Berkeley Packet Filter, kurz BPF. Je flexibler und mächtiger Programmiersprachen sind, desto mehr Möglichkeiten für Fehler gibt es. BPF war absichtlich sehr stark eingeschränkt, damit die Programme in dieser Programmiersprache gar keine schlimmen Fehler machen konnten: Sie konnten nicht abstürzen, sie konnten das System nicht langsam machen und sie konnten sich nicht aufhängen.
Insbesondere aus dem Cloudumfeld kam irgendwann auch das Bedürfnis auf, dass man gewissen Programmen noch mehr auf die Finger schauen wollte als normalen Programmen. Beispielsweise, um zu verhindern, dass sie Dinge taten, die sie nicht tun sollten: Also, dass sie gewisse Betriebssystemfunktionen gar nicht oder nur unter bestimmten Bedingungen aufrufen durften. Oder dass ihre Aktivitäten von anderen Programmen überwacht werden konnten.
Als Lösung wurde eine Art „Firewall für Betriebssystemfunktionen“ gesucht. Und entstanden ist eine Erweiterung von BPF, bekannt als eBPF, die im Cloudumfeld zum Standard für die Umsetzung von Sicherheitsfunktionen geworden ist.
Ursache der CrowdStrike-Linux-Crashes
Im ersten Teil dieser Serie wurden auch CrowdStrike-Abstürze beim Booten unter Linux zwischen April und Juni diesen Jahres erwähnt. Und im zweiten Teil, dass die Nutzung von Techniken wie das beim Linux-Kernel häufig genutzte eBPF das Risiko von solchen Crashes reduziert hätte. Das ist eine sehr schöne Geschichte, aber — wie sich in der Zwischenzeit herausstellte — ist sie nur teilweise korrekt.
Die genannten Abstürze des Linux-Kernel wurden nämlich verursacht, weil CrowdStrike Falcon die eBPF-Funktionen des Linux-Kernels nutzte. Entsprechend war auch die kurzfristige Abhilfe, auf den betroffenen Geräten CrowdStrike zu verbieten, eBPF zu nutzen und stattdessen wieder zum Falcon-Kernelmoduls zurückzukehren.
Trotz dieser negativen Erfahrung ist die Nutzung von Betriebssystemfunktionen — so weit irgend möglich — immer vorzuziehen, bevor man sie selbst nachbildet. Denn die vom Betriebssystem selbst zur Verfügung gestellten Funktionen sind fast immer besser getestet als der selbst entwickelte Code.
Abgesehen davon: Wenn man den eigenen Code konsequent mit allen von der eigenen Software unterstützten Betriebssystemversionen testen würde, würden auch (die durch eigenen Code ausgelösten) Fehler im Betriebssystem rechtzeitig erkannt werden.
Das heisst: Dies ändert nichts an den bereits im ersten Artikel erwähnten Schlussfolgerungen.
Positive Entwicklungen
Der globale Aufschrei wurde zum Glück auch zu einem globalen Weckruf. So sehen wir einige positive Entwicklungen seit dem Vorfall.
Mehr Transparenz in der Branche
Vielleicht eine der besten Entwicklungen: In der gesamten Branche kam es zu mehr Transparenz. Firmen erklären, wie ihre Sicherheitsfunktionen ins Betriebssystem eingreifen und wie die Software getestet wird:
- FortiNet hat am 23. Juli ihre Update-Release-Prozesse für Software und Erkennungsregeln für FortiEDR publiziert.
- Am 1. August hat Sophos die Funktionen ihrer Kernelmodule erläutert und wie sie dem Kunden die Kontrolle über den Rollout-Prozess ermöglichen.
Es ist davon auszugehen, dass hinter den Kulissen wahrscheinlich überall etliche der von den Experten an CrowdStrike gerichteten Empfehlungen umgesetzt oder zumindest verbessert werden.
Das soll die Kunden aber nicht davon abhalten, kritische Fragen an die Hersteller zu stellen. Hier eine Zusammenfassung der Punkte, die Sicherheitsforscher Kevin Beaumont einbrachte, ergänzt durch weitere Empfehlungen aus dem dazugehörigen Fediverse-Thread:
- Die Fragen von Kevin Beaumont (allgemein anwendbar):
- Wie laufen die verschiedenen Update-Prozesse ab?
- Wie werden sie getestet?
- Testet ihr sie auch an euch selbst? («Dogfooding»)
- Werden Updates in Wellen ausgerollt? Wie genau (also z.B. in welche zeitlichen und anteilmässigen Schritten)?
- Überwacht ihr Fehlschläge bei den Updates? Welche Massnahmen werden getroffen, wenn Fehler auftauchen (z.B. automatische Rückkehr zur Vorgängerversion)?
- Die vertiefenden Fragen von Callionica (vor allem auf Sicherheitsprodukte bezogen):
- Beschreibt die Vorgehensweise der verschiedenen Update-Prozesse im Detail
- Werden alle Updates signiert und validiert?
- Beschreibt eure erweiterten Testmethoden (Fuzzing, Fault Injection, …)
- Testet ihr auch die korrekte Funktionsweise von anderer (Dritthersteller-)Software auf euren Geräten? (Dies stellt sicher, dass auch übliche Software wie z.B. Text-/Bildverarbeitung oder Buchhaltungssoftware nachher noch korrekt funktioniert.)
Dies sind Fragen, die man — möglicherweise in leicht angepasster Form — allen Herstellern von Produkten stellen sollte, die wichtige Prozesse in einer Firma lahmlegen können. Nicht nur Sicherheitsfirmen.
«BSI entwickelt Folgemaßnahmen»
10 Tage nach dem CrowdStrike-Vorfall verkündete das deutsche Bundesamt für Sicherheit in der Informationstechnik, dass es Folgemassnahmen entwickelt hätte. Auf der Liste stehen ganz viele Punkte, die in der Schweiz wohl mit «der Bund steht im Austausch mit allen Beteiligten und beobachtet die Lage, zählt aber auf die Eigenverantwortung aller» zusammengefasst worden wäre.
In der Liste stehen keine konkreten Forderungen. Die Punkte, die das BSI mit den verschiedenen Herstellern diskutieren will, sind allesamt schon aufgebracht worden; und CrowdStrike hat vieles davon schon versprochen.
Es ist also fraglich, was diese Pressemitteilung erreichen will: Neues Konkretes findet man — im Gegensatz zu den Versprechen auf Social Media — nicht. Ich hätte mir vom BSI hier mehr Biss erwartet.
Aber das ist immer noch viel mehr, als die offizielle Schweiz dazu bisher verlautbaren lassen hat.
Notstart
Viele IT-Entwicklungen der letzten Jahrzehnte haben zum Ziel, es nach einer fehlgeschlagenen Änderung möglichst einfach zu machen, wieder zu einem «bekannt guten Zustand» («last known good state») zurückzukehren:
- Für komplette Dateisysteme oder ganze virtuelle Maschinen
- Backups
- Snapshots
- «Restore points»
- Für „normale“ Dateien (z.B. Textverarbeitung)
- Undo
- Automatische Speicherung
- Versionierte Cloudspeicher
- Für Quellcode und Konfigurationsdateien
- Versionsverwaltungen wie git
- Die ganze Entwicklung hinter «Move fast and break things»
- Bei der Entwicklung von Cloudanwendungen
- Replication
- Infrastructure as Code (IaC)
Etliche Betriebssysteme bieten manuelle oder automatische Möglichkeiten an, von früheren Versionen zu booten:
- Solaris — wie Linux eines der Mitglieder der grossen Unix-Familie von Betriebssystemen — bietet schon seit unzähligen Jahren alternative «Boot Environments» an. Diese Boot Environments können sehr einfach, schnell und speicherplatzsparend erstellt werden, z.B. vor jedem Softwareupdate. Danach kann davon gebootet werden.
- Auch die beliebte Linux–Distribution Ubuntu kann seit vier Jahren automatisch vor jedem Systemupdate einen Snapshot eines Systemzustands erstellen, von dem dann auch gebootet werden kann. Dazu muss keine Systemadministratorin vor Ort gehen.
- GrapheneOS, «das private und sichere Betriebssystem für Mobilgeräte mit Android-App-Kompatibilität», macht wohl die komfortabelsten automatisch sichere Updates: Wenn das Betriebssystem beim ersten Boot im neuen Zustand nicht richtig bootet, wird automatisch mit der vorherigen Version neu gebootet.
- Auch Windows hat sogenannte Systemwiederherstellungspunkte. Sie sind aber aus dem Bootmenü heraus nur schwer zu erreichen und hätten in diesem Falle auch nicht geholfen. Eine stärkere Automatisierung nach einem der obigen Vorbilder wäre zu empfehlen. Microsoft wird sich diesen Themas sicher annehmen.
Einige dieser Systeme hätten die von CrowdStrike generierten Ausfälle minimieren oder gar verhindern können. Oder könnten sehr einfach darauf angepasst werden. Um so erstaunlicher ist, dass Windows bisher keinen automatischen oder manuellen Start des letzten funktionierenden Zustands bietet.
Lessons Learned
Fassen wir doch noch einmal die wichtigsten Punkte zusammen:
… für Softwareingenieure und Projektleiter
Softwareentwicklern (und ihren Projektleitern) seien die folgenden Punkte ans Herz gelegt, damit genügend Sicherheitsnetze aufgebaut werden:
1. Nutzung von Betriebssystemfunktionen
Betriebssysteme sind dazu da, Funktionen zur Verfügung zu stellen, die hoher Privilegien bedürfen. Diese Funktionen sollten daher allgemeingültig und sicher vom Betriebssystem zur Verfügung gestellt werden. Und Applikationen sollten wenn immer möglich die Funktionen des Betriebssystems nutzen, als sie selbst zu implementieren. Auch wenn das bedeutet, über den eigenen Schatten zu springen.
U.a. deshalb, weil Betriebssystemfunktionen meist besser getestet sind als die eigene Applikation.
2. Testen, testen, testen
Die tollste Software nützt nichts, wenn sie nicht ausreichend getestet ist. Die Tests sollten auch auf verschiedenen Umgebungen ausgeführt werden, nämlich denen, die auch die Kunden einsetzen (oder zumindest diejenigen, zu welchen man Kompatibilität verspricht).
Bei Sicherheitssoftware sollten die Tests zusätzlich auch wiederholt werden, wenn Updates des Betriebssystems vorliegen.
Wenn dies so umgesetzt worden wäre, wären sowohl die Fehler im Linux-Kernel rechtzeitig erkannt worden als auch die Abstürze vom 19. Juli vermieden worden.
3. Staged Rollouts
Das haben wir schon mehrfach durchgekaut. Dazu gibt es hier nichts Neues zu sagen.
4. Die Systemumgebung ist so aufgebaut, dass ein Fehler einfach abgefangen werden kann
Diesem Thema haben wir mit „Wieso wir «Move fast and break things» falsch verstehen — und wie wir Software besser machen können,“ einen eigenen Artikel gewidmet. Schon lange vor dem CrowdStrike-Problem.
Deine Software und Prozesse darum herum sollten so aufgebaut sein, dass (a) die Software automatisiert getestet wird, bevor sie eingesetzt wird und (b) falls doch Fehler erst beim Einsatz bekannt werden — egal welcher Art! — diese mit einfachen Mitteln rückgängig gemacht werden kann.
… für IT-Verantwortliche
Es gibt wenig, was man als Kunde bei der Einschätzung IT-Produkten tun kann. Es bleiben fast nur zwei Möglichkeiten:
- Das Produkt in Sicherheitstests aktiv zu testen und anzugreifen (Red Teaming, Pentesting, …). Wenn man aber nicht sehr viel Zeit und Geld in diese Sicherheitstests investiert, wird das trotzdem nur ein sehr oberflächliches Bild bleiben. Das Produkt kann trotzdem noch Dutzende von unentdeckten Schwachstellen aufweisen, die den Testern einfach entgangen sind. Oder aber — wie bei CrowdStrike — wird ein schwerwiegendes Problem erst durch eine Änderung in der Zukunft aktiv. (Auch dies ist bereits im «Move fast and break things»-Artikel thematisiert worden.)
- Deshalb braucht es für ein detailliertes Urteil auch eine intensive Auseinandersetzung von Experten auf beiden Seiten. Auf Seiten des Kunden braucht es dazu erfahrene Leute mit Kenntnissen des Kundenumfelds; am besten eigene Experten, ersatzweise aber auch unabhängige Externe:
- Ein erfahrener Softwareentwickler mit IT-Sicherheitsbackground des Kunden befragt sein Gegenüber beim Lieferanten, wie sie zuverlässige und sichere Softwareentwicklung umsetzen (einige Vorgehensweisen sind z.B. in unserem «Move fast and break things»-Artikel aufgelistet).
- Ein erfahrener IT-Sicherheitsexperte des Kunden befragt sein Gegenüber beim Lieferanten, wie sie IT-Sicherheitsmechanismen umsetzen und wie diese ins Umfeld des Kunden integriert werden würden. (Dieser Schritt ist besonders dann wichtig, wenn der Lieferant auch IT-Dienstleistungen erbringen soll.)
- Zusätzlich schaut man sich — wenn vorhanden — an, wie der Lieferant in der Vergangenheit mit Problemen umgegangen ist. Ob der Umgang effizient, offen und ehrlich war. Oder ob versucht wurde, anderen die Schuld zu geben und Dinge unter den Teppich zu kehren.
Kenne deine Umgebung und sei dir der Risiken bewusst, die einzelne Software, Hardware oder Kombinationen davon in deinem Betrieb anrichten können. Wenn du es nicht selbst beurteilen kannst: Ziehe geeignete Fachkräfte hinzu. Denn es ist dein Geschäftsprozess, den du am Laufen lassen willst.
… für die Politik
1. Keine Verzettelung bei der Qualitätssicherung
Die oben genannte Qualitätssicherung beim Einkauf von Produkten ist mit viel Aufwand und kann von vielen Kunden gar nicht gemacht werden. (Und auch dann verbleibt noch eine Restunsicherheit.)
Deshalb wäre es wichtig, wenn es — ähnlich wie bei Tests von Staubsaugern oder Medikamenten — unabhängige, tiefgehende Tests gäbe. Infolge der notwendigen Spezialisierung und der entstehenden Kosten wäre eine Einrichtung einer entsprechenden Testorganisation auf nationaler oder supranationaler Ebene sinnvoll.
2. Haftung bei kommerziellen Produkten
Die CrowdStrike-AGBs lauten im Kern ja in etwa: «Wenn du unser Produkt einsetzt, bist du selber schuld.» Das mag OK sein für eine Software, die ohne kommerzielle Interessen kostenlos zur Verfügung gestellt wird. Wenn Firmen ihre Produkte für viel Geld und riesige Gewinne verkaufen, dürfen sie sich nicht auf diese Weise aus der Verantwortung ziehen können.
Aus gutem Grund haben wir Gesetze, die verbindliche Mindeststandards beispielsweise bei Lebensmitteln, Fahrzeugen und Bauwerken fordern. Und die bei Missachtung empfindliche Konsequenzen nach sich ziehen. Wieso haben wir keine solchen Gesetze in der IT?
Weiterführende Informationen
- Marcel Waldvogel: Unnützes Wissen zu CrowdStrike, 2024-08-04.
Weitere (z.T. spassige, z.T. ernste) Hintergrundinformationen zu CrowdStrike. - Bruce Schneier und Tarah Wheeler: Let’s start treating cyber security like it matters, Defense One, 2024-08-02.
«Wenn wir IT-Sicherheit ernst nehmen wollen, dann sollten wir das auch ähnlich gut machen wie z.B. nach Flugunfällen. Und nicht alle im Ungewissen lassen, ob jetzt Wasser abkochen oder Hufeisen am Hauseingang besser gegen Cholera helfen.» (sehr frei übersetzte Zusammenfassung). - Leslie Josephs und Ece Yildrim: Delta CEO says CrowdStrike-Microsoft outage cost the airline $500 million, CNBC, 2027-07-31.
Trotz riesiger Investitionen in Redundanz fielen 40’000 Windows-Server(!) gleichzeitig aus und mussten händisch entsperrt werden. In dieser Zeit fielen 5000 Flüge aus. Der Delta-CEO gibt die Schuld der Kultur hinter den Big-Tech-Unternehmen, für die nur Börsenkurse relevant seien und Kundenzufriedenheit unwichtig sei. - David Weston: Windows Security best practices for integrating and managing security tools, Microsoft, 2024-07-27.
Einblick, wie Fehler in Kernelmodulen gesucht werden. Und dass die Microsoft-Überprüfung von Kernelmodulen Fuzzing einsetzt. Und wie Microsoft jetzt und in Zukunft ihr Ökosystem sicherer machen will (aber keine der aufgelisteten Funktionen hätte den CrowdStrike-Incident verhindert oder einfacher reparierbar gemacht). Scheint vor allem Marketingziele zu erfüllen? - Windows Compatible Product List, Microsoft, Abfragewebseite.
Dort kann man nach «Falcon Sensor» suchen und findet Dutzende von Zertifikaten von Microsoft für dieses Produkt, auch für uralte Windowsversionen wie Windows 7 oder Windows Server 2012. - Nach globalen IT-Ausfällen – BSI entwickelt Folgemaßnahmen, BSI, 2024-07-29.
Die oben erwähnte Pressemitteilung mit BSI-Massnahmen. - Alex Ionescu: Tech Analysis: Channel File May Contain Null Bytes, CrowdStrike, 2024-07-24.
Erklärung, wie die anfänglich entdeckten Channel Files aus lauter Nullbytes entstanden sind. Diese wurden anfänglich fälschlicherweise für die eigentliche Crashursache gehalten. (Diese Beschreibung deckt sich mit meinen Vermutungen.) - Paul Thurrot: Not a great look (paywall), Thurrot.com, 2024-07-22.
Ein Rückblick auf die Microsoft-EU-Verhandlungen 2006/2007 von jemandem, der damals Artikel in Papierzeitschriften darüber schrieb. Wahrscheinlich die beste (politische) Aufarbeitung des damaligen Ereignisses. - Tom Dotan and Robert McMillan: Blue Screens Everywhere Are Latest Tech Woe for Microsoft, Wall Street Journal, 2024-07-21.
Der Artikel, in dem ein Microsoft-Sprecher den Vorwurf gegenüber der «EU-Entscheidung aus 2009» aufbrachte. - Rafael Zeier: War die EU schuld am globalen IT-Ausfall? (paywall), Tagesanzeiger, 2024-07-23.
Hinterfragen der Microsoft-Aussage, deckt einige Unstimmigkeiten auf. - Weltweite Systemausfälle durch fehlerhafte Updates, BACS, 2024-07-19.
Scheinbar die bisher einzige schriftliche Reaktion der offiziellen Schweiz. - eBPF for Windows, Microsoft-Softwareprojekt auf GitHub.
Auch Microsoft arbeitet schon seit Längerem an eBPF-Unterstützung für Windows (Danke für den Tipp). - Kristian Köhntopp: 1½ decades of Booking.com databases, Fediverse thread, 2024-08-02.
Erfahrungen und Lessons learned aus dem Betrieb einer Applikation mit Tausenden von Datenbankservern. Auch wenn bei Ihnen eine Minute Downtime weniger als 15’000 Franken kostet: Viele der Erfahrungen gelten auf für kleinere Systeme, z.B. „wenn du auf die Maschine musst, um nachzuschauen, was läuft, machst du Monitoring falsch“ und „wenn du auf die Maschine musst, um etwas zu ändern, machst du Automatisierung falsch“.


4 Kommentare
Eigentlich kann ich alle Punkte im (für mich hervorragend und unaufgeregt sachlichem) Text unterschreiben.
Eine kleine Lanze für Windows muss ich aber doch brechen:
Windows kann ebenfalls „Lastknowngood“, nur hätte das im aktuellen Fall nicht geholfen, weil sich das auf die Installation neuer Treiber bezieht. Crowdstrike Falcon hatte aber keine neue Software installiert (die vorher[!] nicht da war), sondern lediglich eine Datendatei aktualisiert, die dann vom schon vorher kaputten Kernelmodul zu falschen Aktionen bei der Auswertung animiert wurde. Tatsächlich hätte wohl nur ein Snapshot geholfen, schnell und effizient aus der Pannen rauszukommen. Nur war dieses Update kein offizieller OS-Update, wo so ein Verfahren gegriffen hätte, sondern eben nur die Aktualisierung einer Datendatei. Ich denke, dieser Fehler hätte auch in allen anderen OS-Varianten wie Linux oder Solaris zu einem Problem geführt, wenn dort das entsprechende Modul einen ähnlichen Fehler enthalten hätte.
Der gestaffelte Rollout dieser Signaturdateien will vom Prinzip her auch niemand: Da geht es ja um neue Erkenntnisse zu Angriffsszenarien (die man möglichst schnell aktualisiert haben will) und nicht um den Update der Software. Dieses gestaffelte Update kann CrowdStrike wohl offenbar tatsächlich.
Ich finde es tatsächlich bedenklich, dass Crowdstrike es nicht vorgesehen hat, einen Management-Server zwischen die Geräte mit dem Service und den Crowdstrike-Webservices zu schalten. Jedes System(!) muss Zugriff auf die Crowdstrike Services haben, eine Isolierung vom Internet ist meines Wissens nicht vorgesehen. Und mit so einem Management-Server hätten Firmen zumindest eine Chance, auch Signatur-Updates kurz einem automatisiertem Test zu unterziehen. „Früher“ war das bei Antiviren-Lösungen Standard in grossen Firmen. Aber da gab es auch nur alle paar Tage ein Update und nicht mehrere am gleichen Tag (die Schnelligkeit der Signatur-Updates ist bei Tests immer auch ein Qualitätskriterium).
Schlussendlich: ich fand es nicht erschreckend, das die Datendatei einen Fehler enthielt, der trotz angeblicher Tests verteilt wurde. Erschreckend war, dass das Kernelmodul den Informationen in der Datendatei blind und offenbar ohne eigene Pausibilitätstests vertraut hat.
Danke für die wie immer wertvollen Kommentare!
Ja, genau das CrowdStrike Management, das vorher bei McAfee Antivirus für BlueScreens verantwortlich war (da wurde mal durch fehlerhafte Signaturen die Datei „krnl386.exe“ in Quarantäne gesteckt), und, nachdem die Kunden deswegen weggelaufen sind und die Firma an Intel verkauft wurde, danach CrowdStrike gegründet hat. Das Problem ist viel älter als die aktuellen Vorfälle.
Sarkasmus bitte ignorieren.
Vielen Dank für die ausführliche Darstellung und auch alle Kommentare dazu.
Ich sehe in diesem Vorfall die Überheblichkeit von „Managern“ und „Stakeholder“ – mal wieder – auf der tiefsten Lieferebene bestätigt. Mitarbeitende versuchen im Alltag die Aufträge zu erledigen, sind unterbesetzt und es gibt einfach kein 4-Augenprinzip oder Reviews mehr. Als Quality System Manager dreht sich mir der Magen um. Was ankommt: Entscheidungen über Anschaffungen und Betriebskosten stehen im Vordergrund (Sparen) und ein Risikomanagement stört nur.
Die Ursache, in den technischen Details und Abläufen, und deren Wirkung muss immer im Gesamtkontext betrachtet werden! Nur so werden wirklichen Quellen solcher Zwischenfälle eliminiert. Aber wer will heute noch „heilen/wiederherstellen/reparieren“? Und… wer will schon den Endanwender beglücken?
Auch als „Kunde“ wurde ich bis in Nord-europäische Systeme von den Auswirkungen verfolgt… Brückenpässe oder Fährtickets konnten 4 bis 7 Tage nicht online gebucht werden…Systeme wurden nicht durchgängig mit den Daten beschickt: Online Formular (Buchung) -> Datenbank (Data Storage) -> Daten Verifizierung (Kennzeichenerkennung und Abgleich mit Datenbank) -> Benutzer-Ausgabe (Anzeige, Schranke)
Schade das die berühmten Vorhersagen in Hollywood Filmen immer wieder bestätigt werden wollen…
Cathedral Pretorianer in The Net, Upgrade der Arbeits-Roboter mit anti-humanen Befehlen in I Robot, etc.
Danke noch einmal für diese Plattform, die Berichte – weiter so.