

Die Verantwortlichen von rund 1300 Websites mit .ch-Domains haben in den letzten Wochen eine Mitteilung vom NCSC erhalten welche sie darauf hinweist, dass in den von ihnen betreuten Websites Git-Repositories mit teilweise vertraulichen oder zumindest nicht für die Öffentlichkeit bestimmten Inhalten frei übers Internet zugänglich sind.

Um was geht es?
Wenn es sich nicht gerade um eine Hobby-Webseite handelt, wird heute Struktur und Design eines Webauftritts in einem der Öffentlichkeit nicht zugänglichen Entwicklungs- und Testumfeld vorbereitet und anschliessend auf die öffentlich zugängliche Site übertragen. Dies verhindert, dass durch Umbauten während dem laufenden Betrieb Fehler beim Zugriff entstehen (also zum Beispiel Links auf der Seite plötzlich ins Leere laufen), es erlaubt auch das Ausprobieren von Designvarianten oder Navigationsoptionen, ohne dass der Normalbetrieb dadurch betroffen ist. Nicht im Entwicklungsumfeld vorhanden sind meist die eigentlichen Seiteninhalte, zumindest nicht die aktuellen (die Entwicklungsumgebung für dnip.ch enthält beispielsweise nur die Beiträge bis Sommer 2022 was aber für Designänderungen etc. völlig ausreichend ist).
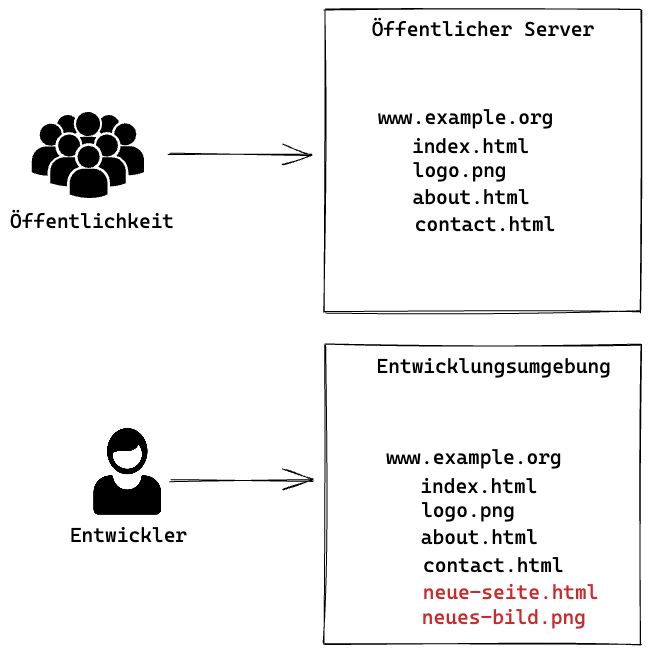
Aber egal wie lange man pröbelt und testet, irgendwann kommt der Moment wo man das neue Seitendesign der Öffentlichkeit zugänglich machen will. Diverse CMS (Content Management Systeme) bieten hierzu Standardprozesse an, man kann das aber halbautomatisch von Hand machen (was sich gerade bei kleineren und vielleicht eher statischen Seiten durchaus lohnt, wenn man sich den Aufwand für ein „grosses“ CMS sparen will). Und hier kommt nun bei einigen Websites das in der NCSC-Meldung erwähnte Git ins Spiel.
Was ist eigentlich Git?
Moderne Software besteht aus hunderten von Sourcecode-Files, an welchen zur Weiterentwicklung mehrere Entwickler gleichzeitig arbeiten um Änderungen zu implementieren. Um hierbei den Überblick nicht zu verlieren, Konflikte durch gleichzeitiges Bearbeiten des selben Sourcecode-Files zu vermeiden und Änderungen generell nachvollziehen zu können, kommt eine Software zur Versionsverwaltung ins Spiel welche genau dies erlaubt.
Eine in Open Source-Projekten weitverbreitete (aber auch von vielen kommerziellen Software-Anbietern genutzte) Software hierzu ist Git. Sie wurde ursprünglich 2005 von Linus Torvald zur Unterstützung der Weiterentwicklung des Linux-Kernels entwickelt. Bei Git handelt es es sich um eine dezentrale/verteilte Versionsverwaltung, d.h. jede Entwicklerin hat auf ihrem Rechner eine vollständige Kopie (ein sogenanntes Repository) des ganzen Sourcecodes und kann ihre Änderungen lokal erstellen und testen. Wenn die Anpassungen fertig ist, können sie gesamthaft ins Hauptrepository der Software übernommen werden. Und analog kann die Entwicklerin ihre eigene Kopie jederzeit mit den konsistenten Änderungen anderer Entwickler aktualisieren. Sie hat also ständig eine lokale Kopie der Software.
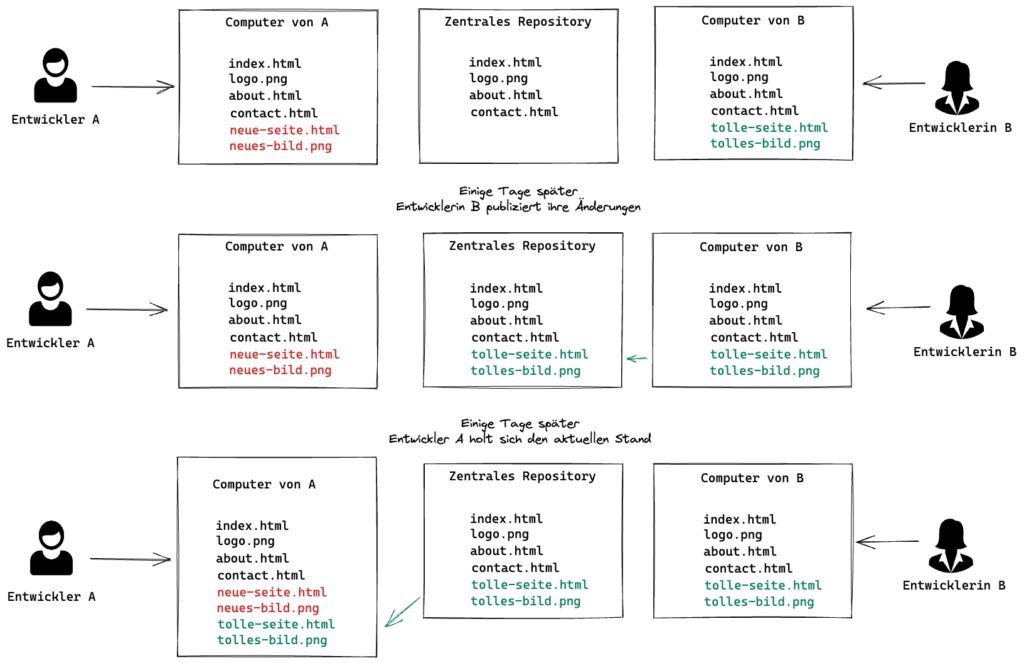
Wie kann man mit Git Websites updaten?
Die Konfiguration, das Design und allfällig verwendete Javascript-Routinen einer Website sind in Textfiles gespeichert (für einfach und eher statische Seiten oft auch die eigentlichen Inhalte). Von daher bietet es sich schon rein zum Nachvollziehen von Änderungen (und allenfalls zum Zurücksetzen auf eine frühere Version falls mal was schiefläuft) an, eine Versionsverwaltung einzusetzen. Wenn dann allenfalls (zum Beispiel in einer Web-Agentur) mehrere Designer und Entwickler beteiligt sind, kann man so auch direkt die Vorteile der dezentralen Entwicklung nutzen um unabhängig voneinander arbeiten zu können.
Und genau diese dezentrale/verteilte Funktionalität kann man dann eben auch nutzen wenn es darum geht, die im Internet sichtbare Version der Website zu aktualisieren. Dazu wird der Code der gesamten Website schlicht nicht für eine weitere Entwicklerin bereitgestellt, sondern mittels derselben Mechanismen direkt auf dem Server der Website selbst. Die Website erhält so eine vollständige Version sämtlicher für ihren Betrieb notwendigen Daten.
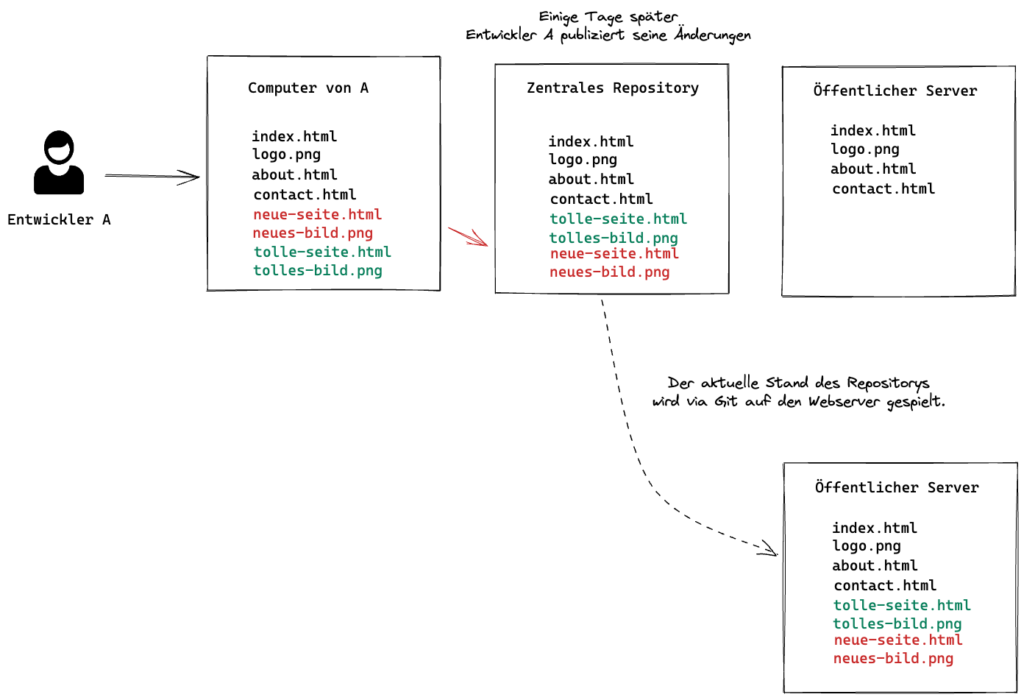
Warum kann das nun ein Problem sein?
Das oben beschriebene Vorgehen funktioniert technisch hervorragend, führt dann aber dazu dass die Website schnell mal mehr Details offenbart als den Entwicklern lieb sein kann. Denn grundsätzlich sind alle Dateien welche im Verzeichnis eines Webservers liegen, auch übers Internet erreichbar. Das ist normalerweise ja auch so gewollt (sonst würden Webseiten-Zugriffe gar nicht erste funktionieren), heisst dann aber auch, dass man nicht einfach so eine Datei namens geheim.html auf seinem Webserver ablegen sollte. Denn selbst wenn diese aus den übrigen Seiten heraus nicht verlinkt ist, reicht das Wissen um ihre Existenz, dass man mit https://www.example.com/geheim.html problemlos darauf zugreifen kann.
Und genau diese einfache Zugreifbarkeit wird jetzt im Zusammenhang mit einem Git-Repository im Hauptverzeichnis des Webservers zum Problem:
- Git verwaltet nicht nur den eigentlichen Quelltext sondern darüber hinaus eine Reihe von Metainformationen. Darunter sind nicht nur die früheren Versionen jeder Datei sondern je nach Konfiguration auch die Login-Daten für den Webserver oder Testumgebungen.
- Je nach Grösse und Art der Website enthält das Git-Repository neben den eigentlichen Website-Dateien noch zusätzliche Files, welche zum Testen der Site verwendet wurden, Überreste von Experimenten oder abgeschalteten Funktionen etc. usw.
Zumindest die für die Konfiguration von Git relevanten Dateien mit den Metadaten heissen unabhängig vom verwalteten Inhalt immer gleich. Und so reicht dann ein Zugriff auf https://www.example.org/.git/config um diese Konfiguration und die allenfalls enthaltenen Login-Daten im Browser anzuzeigen. Unser Diagram von oben müsste daher eigentlich wie folgt aussehen:

Und wenn man nicht nur die Konfiguration sondern auch alle anderen Dateien des Repositories anschauen will?
- Im einfachsten Fall erlaubt der Webserver das Durchsuchen von Verzeichnissen via Browser (d.h. man kann mit Eingabe von
https://www.example.org/.git/den Inhalt des Git-Verzeichnis anschauen). Dann reicht es, dieses Verzeichnis mit wget (ein Tool welches das Kopieren von Webseite-Inhalten erlaubt) auf den lokalen Rechner zu kopieren. Da dieses neben der Konfiguration auch alle Dateien inklusive deren Versionsgeschichte enthält, kann man aus dieser lokalen Kopie anschliessend mit Git ein lokales Repository mit dem aktuellen Stand aller Dateien erstellen (inklusive der erwähnten Experimente etc). - Etwas aufwändiger wird es, wenn Verzeichnisse nicht via Browser durchsucht werden können. Da kann man sich zu Nutzen machen, dass der Inhalt des .git-Verzeichnisses immer gleich strukturiert ist, und die Namen der darin enthaltenen Files daher entweder bekannt sind oder erraten werden können. Das dauert dann zwar etwas länger, aber auch so hat man am Schluss eine Kopie aller Dateien auf dem eigenen Rechner. Vereinfacht wird das ganze durch Tools wie GitTools.
Wer es sich einfach machen will, installiert in Firefox oder Chrome die Erweiterung DotGit, welche beim Surfen nicht nur automatisch offene Git-Verzeichnisse erkennt sondern erlaubt, deren Inhalt direkt als ZIP-Daten herunterzuladen.
Wichtig: Das alles sind Standard-Funktionen von Git bzw. dem eingesetzten Webserver, es handelt sich also nicht um eine Sicherheitslücke in der jeweiligen Software. Es ist schlicht eine Fehlkonfiguration: Git-Repositories gehören nicht ungeschützt ins Hauptverzeichnis eines Webservers. Um das nochmals zusammenzufassen:
- Alle Dateien im Verzeichnis eines Webservers sind grundsätzlich (solange man sie nicht spezifisch schützt) über das Internet lesbar sofern man die deren Namen (bzw. die URL) weiss.
- Wenn ein Git-Repository direkt ungeschützt ins Hauptverzeichnis eines Webservers geladen wird, liegen dessen Konfigurations- und Metadaten mit bekanntem Namen auf dem Server und sind daher übers Internet lesbar.
Wer also aus welchen Gründen auch immer sein Git-Repository trotzdem direkt im Webserver platziert, muss bei der Konfiguration des Webservers entsprechende Vorkehrungen treffen um die versionierten Daten vor Fremdzugriffen zu schützen (dazu später mehr).
Wie alles seinen Anfang nahm
Anfang 2022 erhielten wir eine Liste von rund 1600 Websites in .ch zugespielt, auf welcher im jeweiligen Root-Verzeichnis der Webseite das .git-Verzeichnis frei zugänglich war. Auf den ersten Blick schien die Liste keine grossen Namen zu enthalten, die aufgeführten Sites gehörten zu vielen eher statischen Webauftritten von Shops, Dienstleistungsbüros, Festanlässen oder Restaurants.
Wir nutzten die oben beschriebenen Methoden um uns die Sites genauer anzuschauen und fanden so einiges, was wohl in dieser Form nicht für die Öffentlichkeit bestimmt ist.
- Bei zwei Sites enthielt bereits das Git-Config-File Login-Daten für diverse von der jeweiligen Webagentur betreuten Websites.
- Sites zum Beispiel von Restaurants enthalten oft ein Kontaktformular für Kundenanfragen, diese Anfragen werden je nach Lösung in eine Datenbank gespeichert. Und bei einiger dieser Sites fanden wir einen Auszug dieser Datenbank als Textfile im Git-Repository, inklusive der jeweiligen Anfrage und der Kontaktdaten des Anfragenden.
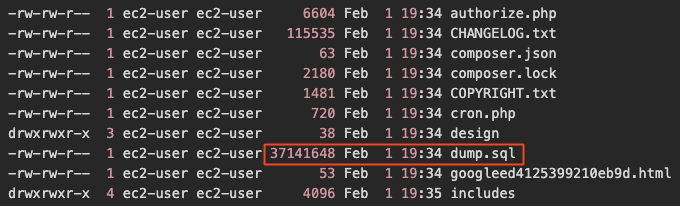

- Je nach Inhalt des Git-Repositories konnte man nicht nur auf sämtliche Dateien des Webservers zugreifen sondern auch auf darin enthaltene Zertifikaten sowie weitere Schlüssel.
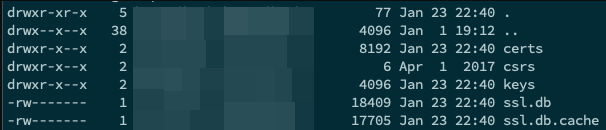
- Bei diversen Sites waren die Zugangsdaten zur dahinterliegenden Datenbank mit den Seiteninhalten in Git abgelegt. Diese Datenbanken sind meist nur vom jeweiligen Rechner aus erreichbar, aber auch da können sich ja Konfigurationsfehler einschleichen. Und dann ist ein einfach lesbares Passwort natürlich gefundenes Fressen für Angreifer.
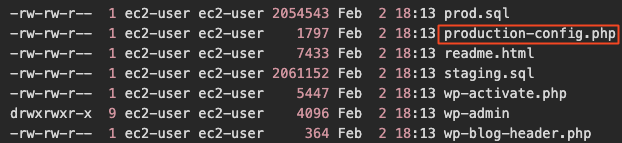
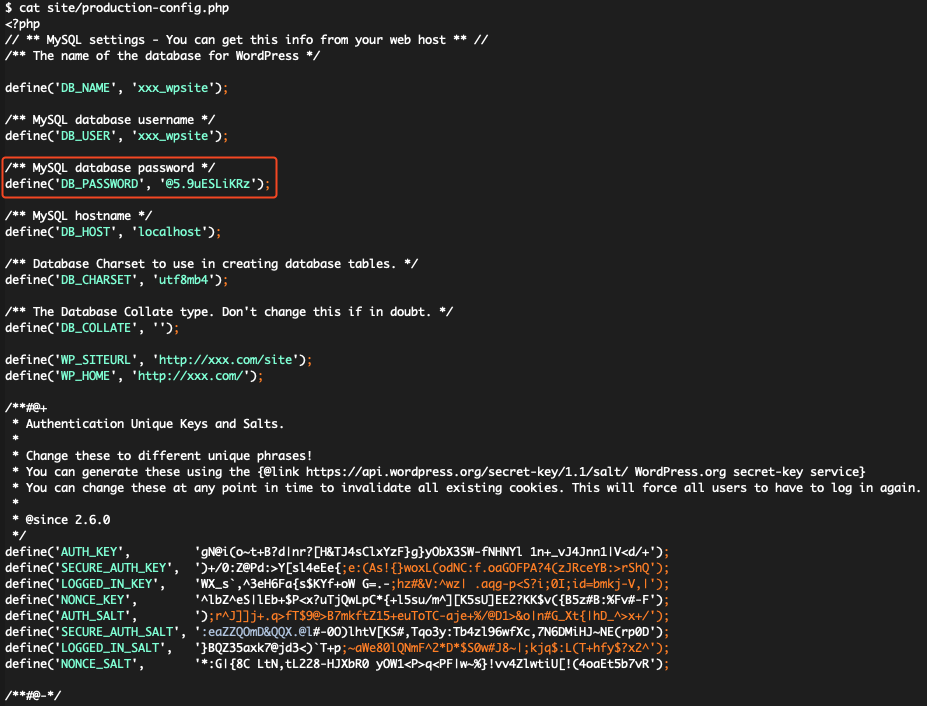
- Teilweise waren auch die Zugriffsdaten für Mail-Accounts in Git abgelegt.
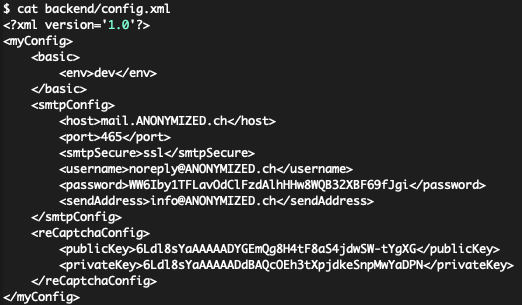
Wir hatten über diese offen zugänglichen Git-Verzeichnisse also Zugriff auf
- Login-Daten von Websites, Mail-Konten und Entwicklungsumgebungen
- Auszüge von Kontaktformularen mit Kundennamen, Email-Adressen, Telefonnummern
- Website-Zertifikate und Schlüssel
Immerhin fanden sich auch beim genaueren Durchlesen der URLs keine „grossen“ Namen von bekannten Unternehmen oder Organisationen, das Risiko eines breiten Missbrauchs durch Ausnutzung der gefundenen Login-Informationen und Kontaktformularen war also eher klein. Trotzdem kann man nur darüber spekulieren ob allenfalls Dritte die Informationen aus den meist schon längere Zeit offenstehenden Repositories für eigene Zwecke „genutzt“ haben..
Soweit die (denen damals noch nicht bekannten) Probleme der Webseiten-Betreiber, vorerst standen wir aber vor einer ganz anderen Herausforderung.
Wie kontaktiert man die Betreiber von über tausend Webservern?
Wir hatten also ein Liste von rund 1600 Webservern mit offenen Git-Verzeichnissen, diverse davon gaben Daten preis welche nicht für die Öffentlichkeit bestimmt waren. Und damit stellte sich die Frage: wie können wir die Besitzer dieser Webserver vor der Publikation informieren um ihnen die Chance zu geben, die Problematik zu bereinigen?
Den direkten Weg einer Email an die Kontaktadresse auf der Webseite haben wir nur bei den beiden Webagenturen gewählt, welche direkt in der Git-Konfiguration Logins und Passwörter der von ihnen betreuten Seiten aufgeführt hatten. Die eine Agentur reagierte postwendend innert weniger Stunden und sperrte den Zugang zur Konfiguration (es wäre natürlich noch besser gewesen wenn sie auch die uns nun bekannten Passwörter geändert hätten), bei der anderen ist unterdessen zumindest die betroffene Website nicht mehr erreichbar (womit sich das Problem ebenfalls gelöst hat). Was aber sollten wir mit den anderen 1600 Sites machen?
- Zumindest theoretisch hätten wir allen eine Mail schicken können. Praktisch scheitert das aber sehr schnell daran, dass nicht sämtliche Websites ein Kontaktformular enthalten und dieses (falls vorhanden) bei jeder Website anders aussieht und anders bedient wird. Die Vorstellung, uns durch hunderte von Websites zu klicken um eine Nachricht abzusetzen, war da auch nicht unbedingt prickelnd.
- Zwar gibt es mit RFC 9116 einen Standard zum Hinterlegen von Kontaktdaten auf einem Webserver. Der ist aber in der Schweiz nur schwach verbreitet, und erstaunlicherweise ist die automatisierte Abfrage via Script (was bei 1600 Websites Pflicht wäre) auch nicht so einfach. Beim Zugriff zum Beispiel auf
https://google.com/.well-known/security.txtkriegt man eine HTML-Seite(!) zurück welche den Hinweis enthält, doch bitte aufhttps://www.google.com/.well-known/security.txt zuzugreifen. Wenn es einem sogar Google so schwer macht, dürfte eine automatisierte Auswertung bei Kleinanbietern eher noch aufwändiger sein. - Beim Registrieren einer Domain muss man eine Kontakt-Email hinterlegen. Diese Informationen waren früher über den Whois-Service abrufbar, seit ein paar Jahren ist dies aber aus Datenschutzgründen nicht mehr möglich.
- Grundsätzlich könnte man über den jeweiligen Hosting-Anbieter gehen, der müsste ja wissen, wie er seine Kunden erreichen kann. Aber das verlagert primär das Problem, schlussendlich ist auch das Identifizieren des jeweiligen Hosters sowie dessen Kontaktadresse nicht so ganz einfach und für rund 1600 Sites auch nur sehr eingeschränkt automatisierbar (und wenn man Pech hat, liegt die Webseite zum Beispiel bei AWS oder einem anderen Cloud-Anbieter).
Mit einem akzeptablen Aufwand wäre es also kaum möglich gewesen, für sämtliche betroffenen Domains eine aktuelle Mail-Adresse zu finden. Und selbst wenn: Wie hätten wir sie inhaltlich so anschreiben können, dass sie einerseits das Problem verstehen (gerade wenn die Mail dann nicht an den IT-Support sondern zum Beispiel an einen Verkaufsmitarbeiter geht), andererseits aber nicht wegen vermeintlichen Hacker-Angriffen an die Presse gelangen oder (wenn es dumm läuft) direkt die Justiz einschalten? Wenn schon nur konservativ geschätzte 10% der Angeschriebenen mit Rückfragen an uns reagiert hätten, hätten wir einiges zu tun gehabt.
Glücklicherweise gibt es eine Stelle in der Schweiz welche sämtliche .ch-Domains kennt: die Stiftung Switch welche nicht nur Internet-Dienstleistungen für Hochschulen und Forschungseinrichten anbietet sondern im Auftrag des BAKOM als offizielle Registrierungsstelle (Registry) alle Domain-Namen mit der Endung .ch verwaltet. In dieser Rolle hat Switch notwendigerweise Zugriff auf die hinterlegten Kontakt-Adressen sämtlicher .ch-Adressen, da müsste (sofern das rechtlich zulässig ist) die Kontaktierung unser 1600 Domain-Inhaber doch eigentlich ein Kinderspiel sein.
Dachten wir zumindest…
Verkürzt gesagt: Technisch ja, zuständigkeitsmässig nein. Natürlich kennt Switch die Kontaktdaten aller .ch-Domainhalter und engagiert sich zum Beispiel mit der Saferinternet-Kampagne für mehr Internet-Sicherheit in der Schweiz. Aber als zentrale Anlaufstelle für Cybervorfälle gibt es in der Schweiz das NCSC welches bei solchen Schwachstellen die Aufgabe hat, Domain-Halterinnen zu informieren. Und auch wenn ein öffentlich zugängliches Git-Verzeichnis in den betrachteten Fällen deutlich weniger Brisanz hat als die Restmenge der nach wie vor offenen Exchangeserver so ist das doch ein Thema, um das sich das NCSC kümmern kann.
Und so erhielten in den letzten Wochen rund 400 Domain-Inhaber oder technische Kontakte die eingangs erwähnte Mitteilung des NCSC zu den von ihnen betreuten 1300 Domains (1300 weil gegenüber unserer ursprünglichen Liste in der Zwischenzeit einige Domains vom Netz gingen oder das Problem schon gelöst hatten). Da auch das NCSC sowas nicht im Einzelschrittverfahren von Hand machen kann, haben sie die Thematik gleich zum Anlass genommen, das Vorgehen soweit möglich zu automatisieren. Auf das es beim nächsten Mal etwas einfacher und schneller geht.
PS: Können sich Webserver-Betreiber auch selber schützen?
Nun, der einfachste Schutz ist natürlich, gar nicht erst das ganze Git-Repository auf den Webserver zu laden (Daten, die nicht zugreifbar sind, können auch nicht kopiert werden). Aber das ist einerseits meist nicht kurzfristig realisierbar, andererseits erschwert man das Publizieren von Updates.
Die schnelle Lösung besteht darin, dem Webbrowser den Zugriff auf das Git-Verzeichnis zu verbieten und so den Zugriff übers Web zu Verhindern. In häufig eingesetzten Webserver Apache lässt sich das einfach über die Konfiguration des Servers erreichen.
<DirectoryMatch "^/.*/\.git/">
Require all denied
</DirectoryMatch>Für andere Webserver wird man in der Anleitung von Cyberscan.io fündig.
Wenn man es etwas sicherer mag, aber nicht auf die Vorteile von Git auf dem Webserver verzichten will, kann man das Git-Repository auf dem Server auch in ein Verzeichnis legen welches vom Webserver gar nicht erst erreicht wird. Allerdings kann Git so nur noch dazu genutzt werden, die für die Website notwendigen Files auf den Rechner zu bringen auf welchem der Webserver läuft. Das eigentliche Updaten der Site muss dann über Skripte erfolgen welche die notwendigen Daten ins Verzeichnis des Webservers kopieren.


2 Kommentare
Der Witz von Git ist, dass es gerade nicht zentral ist. Aber für das Thema ist das nicht relevant, von daher trotzdem ein guter Beitrag.